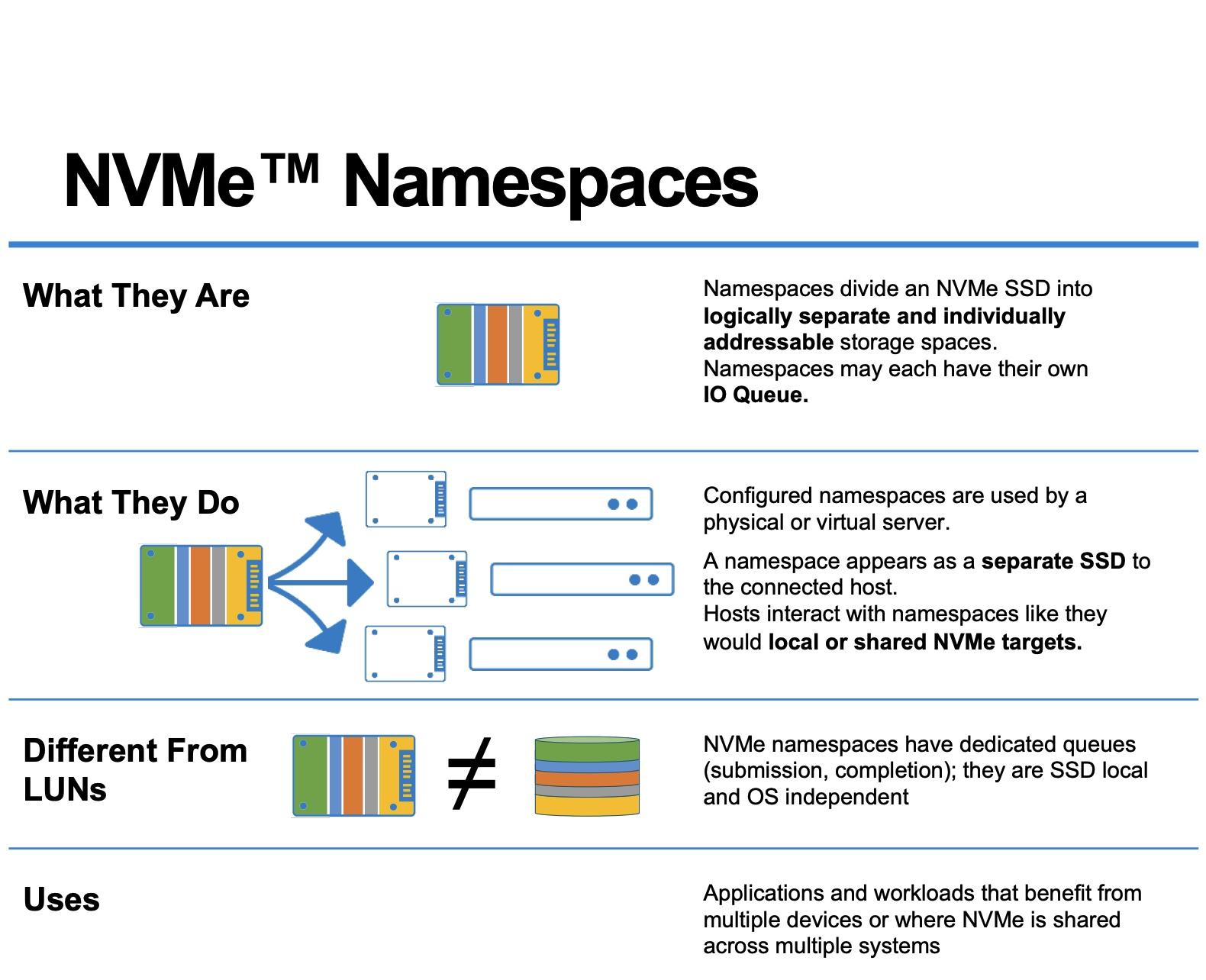
- En un SSD NVMe, un namespace es un conjunto lógico de bloques (LBA) que el host ve como un dispositivo independiente, gestionado mediante comandos de creación, borrado y asociación.
- Linux expone cada namespace como /dev/nvmeXnY, sobre el que se pueden crear particiones, sistemas de ficheros o usarlo como bloque crudo, gestionando permisos a nivel de dispositivo.
- Los namespaces también son un mecanismo del kernel para aislar recursos (PID, red, montajes, usuarios, etc.), base de contenedores y sandboxes como Docker, Podman o Flatpak.
- En Kubernetes, los namespaces organizan y aíslan recursos lógicos del clúster, permitiendo multitenancy, control de acceso por RBAC y cuotas de recursos dentro de un mismo clúster físico.
Cuando empiezas a meterte de verdad con almacenamiento moderno, NVMe y Linux, es normal que te explote un poco la cabeza: namespaces, particiones, LVM, contenedores, Kubernetes… Parece que todo usa la misma palabra, pero no siempre significa lo mismo. Aquí vamos a centrar el tiro en qué son los namespaces en un SSD NVMe, cómo se ven desde Linux y, ya que el término se reutiliza, veremos también cómo encajan los namespaces en el kernel de Linux y en Kubernetes para que no los confundas más.
La idea es construir una imagen completa: desde lo que pasa físicamente dentro de un SSD NVMe con namespaces lógicos, pasando por cómo se exponen como dispositivos /dev/nvme0n1 en Linux, cómo se gestionan con herramientas como nvme-cli, y terminando con el concepto de namespaces a nivel de sistema (IPC, PID, red, etc.) y en orquestadores como Kubernetes. Todo ello con un enfoque práctico, cercano y, sobre todo, sin dejarte ningún fleco suelto.
Qué es realmente un namespace en un SSD NVMe
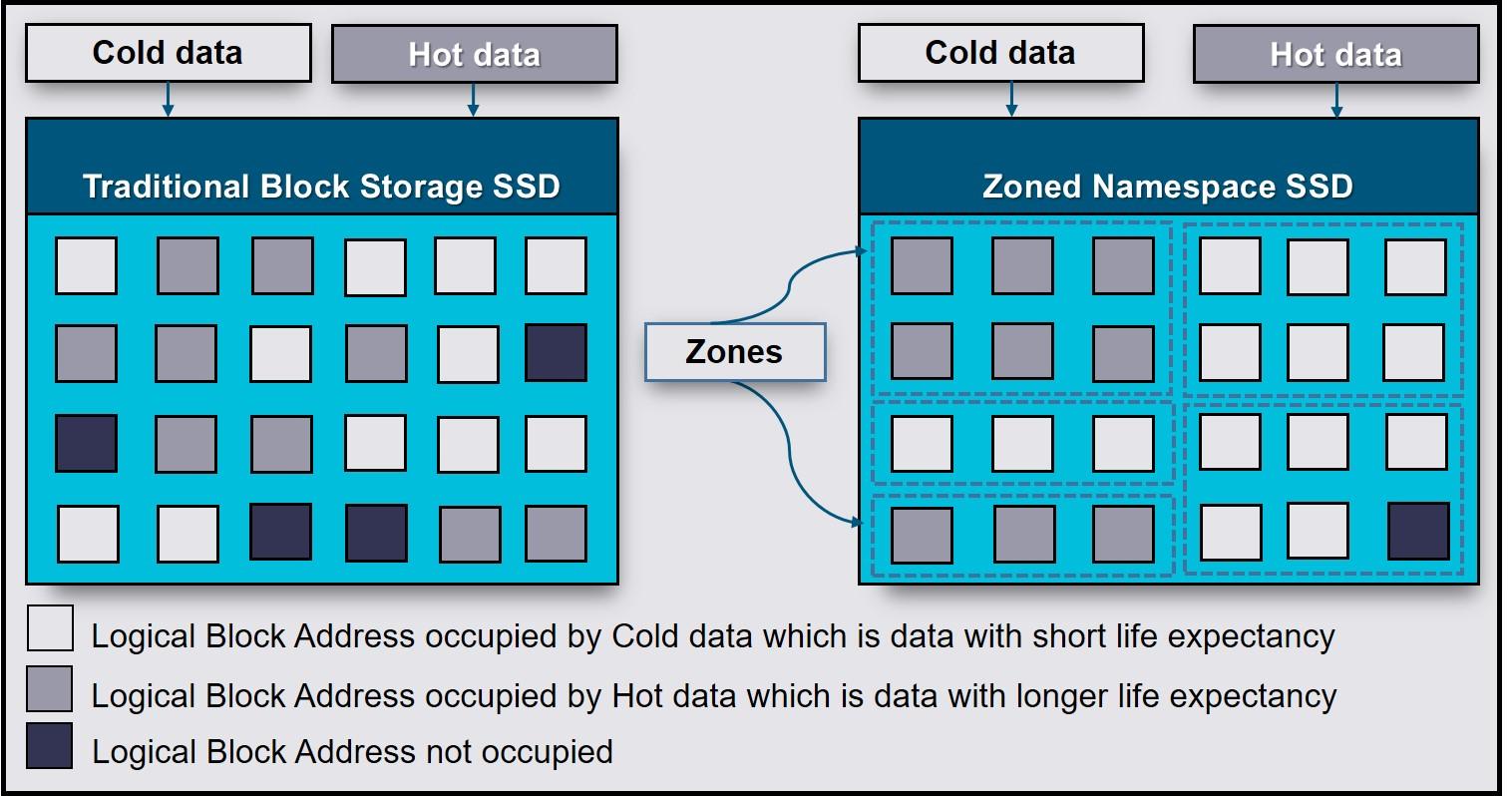
En la tecnología NVMe un namespace es, literalmente, un conjunto de direcciones de bloque lógicas (LBA, Logical Block Addresses) que el sistema operativo puede ver como si fuera un dispositivo de bloque independiente. No es un trozo físico separado de NAND, sino una separación lógica dentro del SSD.
Cuando el fabricante configura el disco, el controlador NVMe organiza la memoria flash en uno o varios namespaces. Cada uno se identifica mediante un NSID (Namespace ID) y el controlador se encarga de exponer esos namespaces al sistema anfitrión. Cada namespace se presenta al sistema como un destino independiente, lo que permite que un mismo SSD parezca, a ojos del sistema, varios “discos” diferentes.
En Linux, cada namespace aparece como un dispositivo de bloque tipo /dev/nvmeXnY, donde X es el índice del controlador (por ejemplo, 0) e Y es el ID del namespace (por ejemplo, 1). Así, /dev/nvme0n1 indica “controladora NVMe 0, namespace 1”. Este dispositivo se puede tratar como cualquier otro disco: se puede particionar, formatear, añadir a LVM, usar como volumen crudo, etc.
Un detalle importante es que, en la mayoría de unidades, por defecto existe un único namespace cuyo tamaño abarca toda la capacidad utilizable del SSD. Sin embargo, el estándar NVMe permite borrar ese namespace y recrear varios, cada uno con su propio tamaño y ciertas propiedades particulares, como un formato de LBA concreto o políticas de seguridad específicas.
Tamaño, capacidad y uso de un namespace NVMe
El estándar NVMe define una estructura llamada Identify Namespace que contiene varias métricas críticas: tamaño, capacidad y utilización de cada namespace. Esta información la puedes consultar con herramientas como nvme-cli mediante el comando nvme id-ns y también con programas para diagnosticar discos duros y SSD.
Dentro de esa estructura destacan tres campos clave: NSZE, NCAP y NUSE. Entenderlos bien es fundamental para controlar cómo estás usando realmente el espacio dentro de cada namespace y cómo responde la unidad a operaciones de borrado lógico (TRIM o Deallocate).
El campo Namespace Size (NSZE) indica el número total de bloques lógicos que componen el namespace, numerados desde LBA 0 hasta LBA n-1. Es, por así decirlo, el tamaño nominal del namespace: la cantidad de direcciones de bloque que el host ve como disponibles, independientemente de que estén o no asignadas internamente.
El campo Namespace Capacity (NCAP) marca el máximo de bloques que el dispositivo permite tener realmente asignados en un momento dado. Aunque parezca lo mismo que NSZE, no tiene por qué coincidir: la capacidad puede ser menor que el tamaño oficial del namespace, lo que abre la puerta a técnicas de gestión avanzada de espacio y sobreaprovisionamiento interno.
Por último, el campo Namespace Utilization (NUSE) refleja cuántos bloques lógicos están efectivamente asignados ahora mismo. Tras un formateo completo, NUSE debería ser cero; a medida que se van escribiendo datos, este valor aumenta y solo vuelve a bajar cuando el sistema envía comandos de liberación de bloques (TRIM o Deallocate). Este indicador es muy útil para aplicaciones y sistemas que quieran saber si el dispositivo está atendiendo correctamente las peticiones de liberación de espacio.
Formato de bloques y otras capacidades del namespace
Además del tamaño y el uso, cada namespace describe, a través del comando Identify, qué formatos de LBA soporta, qué tamaños de bloque son óptimos y si dispone de funciones adicionales como protección de extremo a extremo o distintos modos de seguridad. Esta información la usan los sistemas operativos y las aplicaciones para ajustar el tamaño de las operaciones de lectura/escritura y aprovechar al máximo el hardware.
Un mismo SSD puede aceptar uno o varios formatos de LBA (por ejemplo, 4 KiB, 8 KiB, etc.). En algunos modelos, todos los namespaces deben compartir el mismo formato; en otros, es posible que cada namespace tenga un tamaño de bloque diferente. Esto resulta especialmente útil cuando se combinan cargas de trabajo diversas, donde un namespace está optimizado para I/O de ficheros pequeños y otro para grandes lecturas secuenciales.
La estructura de identificación también indica si el namespace admite información de protección (Protection Information, PI), es decir, metadatos adicionales que permiten verificar la integridad de los datos a lo largo de todo el camino, desde la aplicación hasta la NAND, reduciendo la probabilidad de corrupción silenciosa.
Conviene subrayar que un mismo namespace puede estar asociado a una o varias controladoras NVMe dentro del mismo subsistema. Si solo está ligado a una controladora se habla de namespace privado; si se adjunta a varias, se denomina namespace compartido. Esta flexibilidad es esencial en entornos de alta disponibilidad y cabinas de almacenamiento NVMe-oF (NVMe over Fabrics).

Gestión de namespaces: creación, borrado y asociación
La especificación NVMe incluye dos grandes grupos de comandos para manejar namespaces: gestión (Management) y asociación (Attachment). Con el primero puedes crear, modificar y eliminar namespaces; con el segundo, adjuntarlos o separarlos de una o varias controladoras del subsistema.
El flujo típico es el siguiente: primero el host crea un namespace con los parámetros deseados (tamaño, capacidad, formato de LBA, etc.). En ese momento el namespace aún no es visible como dispositivo de bloque para el sistema operativo. Para que aparezca, hay que ejecutar un comando de attach, que lo vincula a una controladora concreta o a varias. Tras un reset de la controladora o un redescubrimiento, el sistema acabará exponiéndolo como un dispositivo /dev/nvmeXnY.
También se puede seguir el camino inverso: desvincular un namespace existente de sus controladoras para dejar de exponerlo al host y, a continuación, borrarlo por completo. Esto es lo que se suele hacer cuando se quiere recrear la distribución de namespaces en una unidad, por ejemplo, para cambiar el porcentaje de sobreaprovisionamiento o para reorganizar el reparto entre distintos tenant.
En Linux, la herramienta de referencia para esto es nvme-cli. Con ella puedes listar namespaces (nvme list), consultar detalles con Identify, crear nuevos namespaces (nvme create-ns), adjuntarlos (nvme attach-ns), separarlos (nvme detach-ns) y borrarlos (nvme delete-ns). Estas operaciones suelen requerir privilegios de administrador y deben planificarse bien, ya que implican cambios profundos en el layout de la unidad. Además, es recomendable mantener el firmware actualizado.
Cuando se trabaja con varios namespaces en la misma unidad, es habitual usar namespaces privados para entornos aislados (por ejemplo, un host concreto) y namespaces compartidos para arquitecturas más complejas, donde varios hosts acceden coordinadamente a los mismos datos a través de un subsistema NVMe-oF.
Por qué dividir un SSD NVMe en múltiples namespaces
Puede parecer que lo más sencillo es dejar el SSD con un único namespace que ocupe toda la capacidad, pero hay razones de peso para crear varios. Entre las más habituales destacan la separación lógica de clientes, la mejora de la seguridad y el ajuste fino de rendimiento y durabilidad.
En escenarios de multitenancy, por ejemplo en proveedores de servicios en la nube o grandes plataformas, un mismo SSD físico puede alojar los datos de varios clientes. Mediante namespaces, cada tenant obtiene su “disco lógico” aislado. Esto simplifica bastante la gestión, la facturación y el diseño de SLA, sin obligar a repartir físicamente la NAND.
Otro motivo frecuente es la seguridad y el cifrado por namespace. Muchas unidades NVMe compatibles con OPAL permiten definir políticas de cifrado sobre rangos de LBA. Si se trabaja con un único namespace, se pueden configurar varios rangos protegidos dentro de él; pero si se crean namespaces separados para distintos grupos de datos, es posible aplicar distintas claves y reglas de cifrado por namespace, alineadas con el nivel de sensibilidad de cada conjunto de información.
También está el caso de los entornos con requisitos de rendimiento muy distintos en la misma máquina. Un namespace puede reservarse para una base de datos crítica, con un porcentaje de sobreaprovisionamiento alto para minimizar la latencia y mejorar la resistencia, mientras que otro namespace sirve para datos menos exigentes en I/O. Esta separación ayuda a evitar que una carga de trabajo ruidosa degrade la experiencia de otra más sensible.
Además, los namespaces permiten aplicar políticas de solo lectura a datos importantes, por ejemplo, un sistema operativo embebido o una imagen de arranque en productos móviles, entornos de alta seguridad o sistemas industriales. El NVMe puede marcar un namespace como de solo lectura temporal (hasta el siguiente ciclo de energía), hasta que el bloqueo se quite y se reinicie, o incluso dejarlo permanentemente en modo lectura para toda la vida útil del disco.
Sobreaprovisionamiento y ajuste fino por namespace
Los SSD siempre reservan internamente cierta cantidad de memoria flash no visible para el sistema, que se usa como espacio de sobreaprovisionamiento para tareas internas como garbage collection, nivelado de desgaste y gestión de bloques defectuosos. Sin embargo, al jugar con el tamaño de los namespaces, el administrador puede influir en cuánto de la NAND queda sin asignar al host y, por tanto, disponible como reserva interna.
Si se crea un namespace notablemente más pequeño que la cantidad total de flash física, se está dejando una fracción mayor de memoria sin exponer al host. Cuanto más sobreaprovisionado queda el dispositivo, mejor suele ser la estabilidad de rendimiento y mayor la resistencia en ciclos de escritura, algo fundamental en cargas de trabajo intensivas en escrituras.
Por ejemplo, imagina un SSD de 7,68 TB al que se le define un namespace utilizable de aproximadamente 6,14 TB. El resto queda oculto al host y pasa a engrosar el “colchón” de sobreaprovisionamiento. Con herramientas como nvme-cli es posible borrar los namespaces anteriores, recrearlos con el tamaño deseado y adjuntarlos de nuevo a las controladoras para conseguir exactamente ese efecto.
Uno de los retos en este proceso es ajustar adecuadamente la granularidad de tamaño y capacidad del namespace. El estándar contempla que tanto NSZE como NCAP se manejen en unidades que no tienen por qué coincidir exactamente con el tamaño lógico de bloque, lo que puede provocar que queden pequeñas porciones de memoria no direccionables si no se eligen bien los valores. El objetivo es minimizar ese espacio “perdido” para que el namespace quede lo más redondo posible.
Durante la creación del namespace, se deben tener en cuenta las restricciones del dispositivo que reporta el propio dispositivo. Ajustando los valores de NSZE y NCAP en función de esos factores, se puede lograr que casi toda la memoria física quede correctamente aprovechada, ya sea como espacio accesible por el host o como sobreaprovisionamiento interno útil para el controlador.
Namespaces, particiones Linux, LVM y acceso directo al bloque
Desde la perspectiva de Linux, cada namespace NVMe aparece como un dispositivo de bloque base tipo /dev/nvme0n1. A partir de ahí, el administrador puede decidir cómo usarlo: dejarlo sin particiones para I/O directo, particionarlo como un disco clásico o integrarlo en LVM o en otros sistemas de gestión de volúmenes.
Cuando se crean particiones sobre ese namespace, el kernel las expone como /dev/nvme0n1p1, /dev/nvme0n1p2, etc. El sufijo “p” indica precisamente que se trata de una partición del namespace, igual que /dev/sda1 es una partición de /dev/sda. Sobre esas particiones se pueden montar sistemas de ficheros, usarlas en LVM, RAID por software, etc.
Si lo que se busca es exponer almacenamiento de bloque “crudo” directamente a una base de datos o a un sistema de almacenamiento distribuido, es habitual trabajar contra el dispositivo del namespace sin particiones, o bien contra una partición dedicada, pero sin sistema de ficheros encima. En estos casos, la aplicación suele hablar directamente en términos de bloques lógicos y gestionar su propio espacio interno.
Conviene tener en cuenta que no es trivial dividir un namespace que ya está en uso con particiones sin afectar a los datos. Para modificar el layout de namespaces, lo normal es respaldar la información, desmontar, borrar el namespace y crearlos de nuevo con el tamaño deseado, lo cual implica una planificación cuidadosa en entornos de producción.
En cuanto a los permisos, un dispositivo de bloque sin sistema de ficheros se controla, como cualquier otro nodo en /dev, mediante propietario, grupo y modo de acceso. Además de eso, se pueden usar ACLs, reglas de udev y mecanismos de control de acceso del propio sistema (por ejemplo, grupos especiales para acceso a discos) para decidir qué usuarios o servicios pueden leer y escribir sobre un namespace o una de sus particiones.
Namespaces del kernel de Linux: aislamiento de recursos del sistema
La palabra namespace no solo se usa en el contexto de NVMe. El kernel de Linux ofrece un mecanismo con el mismo nombre, pero orientado a aislar recursos del sistema para procesos. Esta funcionalidad es la base de tecnologías como contenedores Docker, Podman, LXC o sandboxes tipo Flatpak y bubblewrap.
En este caso, un espacio de nombres envuelve un recurso global (puntos de montaje, pila de red, PIDs, usuarios, hostname, relojes, etc.) en una abstracción que hace que los procesos que viven dentro vean su propia instancia aislada de ese recurso. Los cambios realizados desde dentro de ese namespace solo son visibles para los procesos que comparten ese mismo espacio de nombres.
Linux soporta actualmente varios tipos de namespaces: cgroup, ipc, mnt (mount), net, pid, user, uts y time. Cada uno aísla un aspecto concreto del sistema. Por ejemplo, el namespace de red permite que un contenedor tenga sus propias interfaces y tablas de enrutamiento, mientras que el namespace de PID le da su propia numeración de procesos empezando en 1.
Para inspeccionar a qué namespaces pertenece un proceso concreto, basta con mirar los enlaces simbólicos en /proc/<PID>/ns/. Cada enlace apunta a un identificador de namespace, que puede compartirse con otros procesos (si están en el mismo espacio) o ser distinto (si tiene un entorno aislado).
Herramientas como bubblewrap (bwrap), utilizada por Flatpak, se apoyan precisamente en estos mecanismos. Bwrap crea sandboxes lanzando procesos con namespaces separados para montaje, PID, usuario, red, etc., de modo que la aplicación se ejecuta en un entorno acotado donde solo ve los recursos que se le han concedido.
Experimentos prácticos con unshare y nsenter
Si quieres trastear con namespaces de Linux sin instalar nada raro, tienes a tu disposición comandos del propio sistema como unshare y nsenter. Son muy útiles para entender qué está pasando por debajo cuando ejecutas contenedores o aplicaciones sandbox.
Con unshare puedes lanzar un proceso nuevo con uno o varios namespaces aislados: por ejemplo, un shell que tiene su propio conjunto de PIDs y usuarios. Al ejecutarlo con opciones como –user, –pid y –fork, obtendrás una sesión donde el proceso que corre dentro ve el PID 1 como propio y, además, se ejecuta con un usuario diferente (por ejemplo, nobody), lo que subraya ese aislamiento.
En estos entornos, es importante montar un /proc nuevo y aislado usando la opción –mount-proc. Si no se hace, algunas utilidades que dependen de /proc/<PID>/exe pueden fallar porque intentan ver información de procesos según el namespace del host, y el kernel bloquea ese acceso para mantener el aislamiento de seguridad.
También hay que tener en cuenta que, si unshare no usa –fork, podría ejecutar el comando dentro del mismo proceso y provocar errores curiosos, como la imposibilidad de montar /proc adecuadamente o fallos de asignación de memoria, ya que el proceso no asume el rol correcto de PID 1 dentro del nuevo namespace.
Por otro lado, nsenter hace el camino inverso: te permite “entrar” en los namespaces de un proceso ya existente. Es lo que se suele hacer para examinar desde el host cómo ve el mundo un contenedor o una aplicación Flatpak. Una vez dentro, puedes inspeccionar su pila de red, sus puntos de montaje, la tabla de procesos interna, etc., como si estuvieras “dentro” del contenedor.
Namespaces y contenedores: de Flatpak a Podman y Docker
Una vez entiendes los namespaces del kernel, es fácil ver cómo los contenedores no son magia, sino composición de varias primitivas: namespaces para aislar recursos, cgroups para limitar consumo, capacidades para controlar privilegios y sistemas de ficheros en capas para empaquetar aplicaciones.
Flatpak utiliza bubblewrap para crear entornos aislados para aplicaciones de escritorio. Cada aplicación corre en un conjunto de namespaces donde se restringen las rutas a las que puede acceder, la visibilidad de procesos, la red, etc. A nivel de proceso, se ve claramente que los PIDs, mount points y, a menudo, el usuario, difieren de los del sistema anfitrión.
De forma similar, herramientas como LXC, Docker o Podman componen distintos namespaces para construir contenedores de uso general. Por ejemplo, un contenedor rootless puede usar un namespace de usuario para mapear IDs internos a IDs sin privilegios en el host, y un namespace de red para tener interfaces virtuales dedicadas. Analizando el PID del proceso de contenedor en el host y entrando con nsenter, se puede comprobar de primera mano este aislamiento.
Para situaciones donde se quiere crear namespaces “rootless” de forma más cómoda, se puede recurrir a herramientas como rootlesskit, que ayudan a configurar todo el tinglado necesario para que un usuario sin privilegios pueda crear entornos aislados sin acceso directo a root, algo cada vez más demandado en entornos multiusuario modernos.
Namespaces en Kubernetes: clústeres virtuales lógicos
El término namespace vuelve a aparecer en Kubernetes, pero aquí hace referencia a un mecanismo lógico para segmentar recursos dentro de un único clúster. No tiene nada que ver con direcciones de bloque NVMe ni con aislamiento a nivel de kernel, aunque conceptualmente también se usa para separar y organizar.
En Kubernetes, un namespace es como un clúster virtual dentro del clúster físico. Sirve para agrupar recursos (pods, servicios, deployments, etc.) de forma que puedan gestionarse y aislarse por equipos, proyectos o entornos (desarrollo, pruebas, producción) sin necesidad de levantar varios clústeres reales.
Estos espacios de nombres permiten que existan recursos con el mismo nombre en contextos distintos. Por ejemplo, puedes tener un servicio llamado mi-servicio en el namespace desarrollo y otro con el mismo nombre en producción sin conflicto, porque la unicidad se garantiza solo dentro de cada namespace.
Además, los namespaces de Kubernetes se integran con RBAC (role-based access control). Es posible definir permisos que limitan qué usuarios o cuentas de servicio pueden crear, modificar o leer recursos en un namespace determinado, lo que facilita muchísimo la delegación segura entre distintos equipos u organizaciones compartiendo infraestructura.
Otra pieza clave son las quotas de recursos. Kubernetes permite restringir, por namespace, la cantidad de CPU, memoria, objetos (como pods) y otros recursos que pueden consumir las cargas de trabajo. De esta forma, se evita que un proyecto se “coma” todo el clúster y se fomenta un uso más predecible y justo.
Funcionamiento práctico de namespaces en Kubernetes
En un clúster recién instalado, Kubernetes suele crear varios namespaces por defecto: default, kube-system y kube-public. El primero se utiliza para recursos que no especifican namespace; el segundo está destinado a componentes internos del sistema; el tercero, accesible incluso para usuarios no autenticados, se reserva para ciertos elementos que necesitan ser leídos públicamente a nivel de clúster.
Para ver los namespaces disponibles, se puede usar kubectl get namespaces o su abreviatura. A partir de ahí, el administrador puede crear y borrar namespaces según lo necesite, normalmente siguiendo una estrategia de organización por proyectos o entornos (por ejemplo, dev, staging, prod).
Cuando se lanza un comando con kubectl, se puede indicar temporalmente el namespace objetivo mediante la opción –namespace, o bien configurar un contexto por defecto que haga que todas las operaciones apunten a un namespace determinado, lo que ahorra errores y te evita escribir la opción en cada comando.
En cuanto a DNS, Kubernetes registra los servicios usando un nombre completo del estilo <service-name>.<namespace>.svc.cluster.local. Dentro de un mismo namespace, basta con usar el nombre simple del servicio y la resolución DNS hará el resto. Pero si desde un pod en un namespace quieres acceder a un servicio de otro namespace, debes usar el FQDN completo o un nombre parcial que incluya al menos servicio y namespace.
No todos los objetos de Kubernetes viven dentro de un namespace. Los propios namespaces, los nodos o los volúmenes persistentes son recursos a nivel de clúster y no están encapsulados dentro de un namespace. Esto es importante para entender qué recursos se segmentan lógicamente y cuáles se consideran globales.
En general, se recomienda empezar a usar namespaces cuando el clúster tiene ya un número considerable de usuarios y aplicaciones, o cuando necesitas aislamiento claro entre equipos. Para diferencias menos profundas (como versiones de una aplicación) suele ser mejor usar etiquetas dentro de un mismo namespace que multiplicar innecesariamente el número de namespaces.
Si juntamos todas estas piezas —namespaces en SSD NVMe para segmentar direcciones de bloque, namespaces del kernel para aislar recursos de procesos y namespaces en Kubernetes para organizar lógicamente los recursos del clúster— se ve que la misma palabra se reutiliza para ideas emparentadas: crear dominios separados dentro de un espacio compartido, cada uno con su propia visión y reglas. Entender bien en qué capa estás en cada momento es lo que marca la diferencia entre un sistema ordenado y uno imposible de mantener.

Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.