- Un fallo en Cloudflare ha provocado errores y caídas en millones de webs y servicios en todo el mundo.
- La incidencia ha afectado especialmente a España y Europa, con problemas en banca, comercio electrónico, redes sociales y videojuegos.
- El problema se ha originado en el Panel de Control y las APIs de Cloudflare, con impacto sobre Workers y funcionalidades dinámicas.
- Es la segunda gran interrupción en menos de un mes, lo que evidencia la fuerte dependencia global de este proveedor de infraestructura.

Buena parte de Internet ha vuelto a tambalearse por un nuevo fallo de Cloudflare, el proveedor de infraestructura en la nube que se encuentra detrás de millones de webs y aplicaciones. Usuarios de España, Europa y el resto del mundo han visto cómo, de repente, páginas que usan a diario dejaban de cargar o devolvían errores.
Durante la mañana, plataformas tan variadas como redes sociales, videojuegos, servicios bancarios, tiendas online y herramientas de trabajo han sufrido problemas intermitentes o caídas completas. Lo que para muchos parecía un fallo puntual de su móvil o de su conexión, en realidad tenía su origen en uno de los engranajes fundamentales de la red.
Qué está pasando con Cloudflare
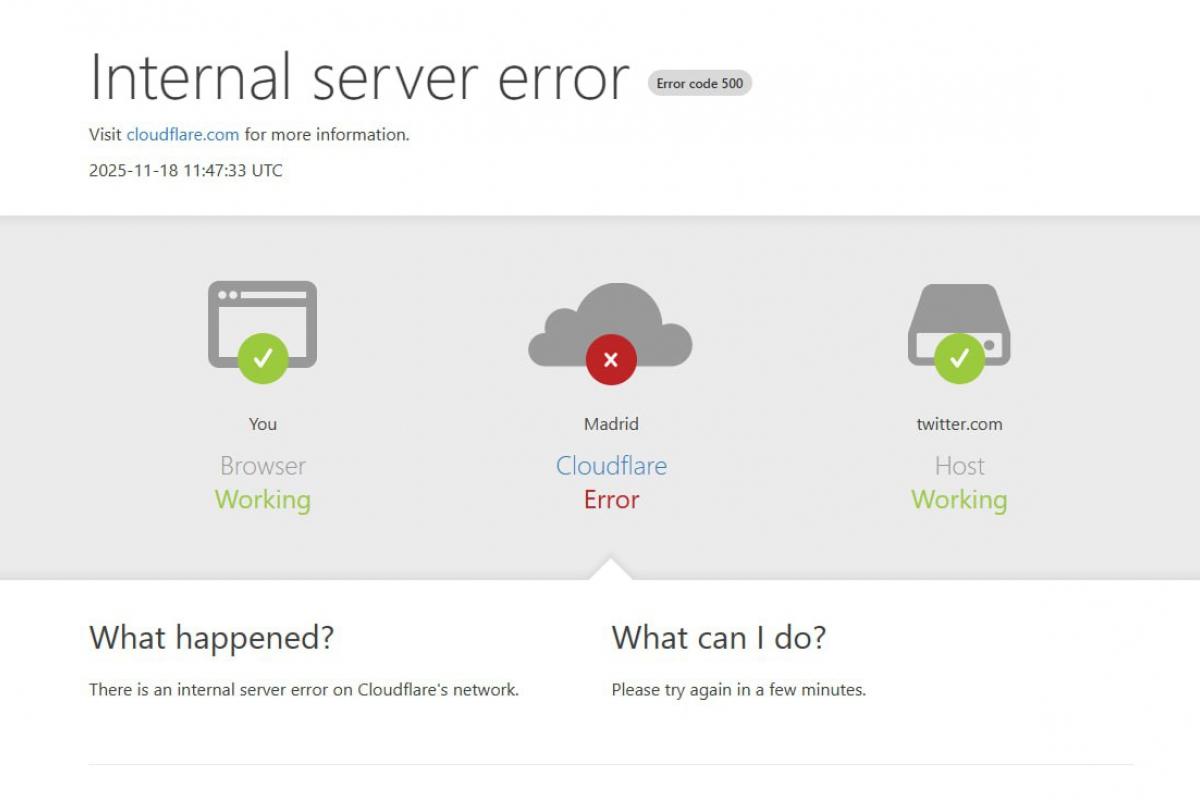
Cloudflare ha reconocido en su página oficial de estado que está investigando una incidencia en su Panel de Control (Dashboard) y en las APIs relacionadas, es decir, en las herramientas que utilizan tanto sus clientes como muchos servicios automatizados para gestionar la red. La compañía ha advertido de que las peticiones pueden fallar y mostrar páginas en blanco o errores 5xx al interactuar con sus sistemas.
Según los primeros reportes publicados por la empresa, el problema se ha empezado a notar en torno a las 08:56 UTC (09:56 hora peninsular española), coincidiendo casi milimétricamente con el inicio de las quejas masivas de usuarios en España y el resto de Europa. Portales como Downdetector han registrado un fuerte pico de avisos a partir de las 10:00, justo cuando las interrupciones se han vuelto más visibles.
Además del Dashboard, Cloudflare ha confirmado que la incidencia ha alcanzado a Cloudflare Workers, su servicio que permite ejecutar código directamente en la red de la compañía. Esto explica por qué algunas portadas de webs cargaban, pero fallaban funciones críticas como carritos de compra, inicios de sesión o paneles internos.
En paralelo, la empresa tenía previstos trabajos de mantenimiento en centros de datos de Estados Unidos, como el de Chicago (ORD). Aunque todavía no se ha establecido con claridad la relación exacta entre ambos hechos, la coincidencia temporal ha levantado muchas sospechas en el sector.

Servicios afectados: de la banca al ocio digital
El alcance del fallo ha sido notable en España y Europa, donde tanto usuarios particulares como empresas han reportado errores continuos al tratar de acceder a servicios cotidianos. Entre los afectados se encuentran bancos, comercios electrónicos, plataformas de videollamadas, herramientas de diseño e incluso redes sociales y servicios de inteligencia artificial.
En el ámbito corporativo y del comercio electrónico, gigantes como PCComponentes o MediaMarkt han experimentado caídas o tiempos de carga extremadamente lentos. En algunos casos, las webs mostraban páginas vacías o errores del tipo «500 Internal Server Error» o «Bad Gateway», dificultando que los usuarios pudieran comprar o tramitar pedidos con normalidad.
La banca digital también se ha visto salpicada. En España, entidades como CaixaBank y Bankinter han registrado incidencias en sus portales, con usuarios sin poder acceder a sus cuentas o a determinados apartados de la banca online. Estas interrupciones se suman a otros episodios recientes en los que aplicaciones bancarias, Bizum y otros servicios financieros ya se habían visto afectados por problemas similares.
Entre las herramientas más utilizadas a nivel global, Zoom y LinkedIn figuran entre los nombres señalados en los reportes. También se han detectado fallos en Canva, la popular plataforma de diseño, donde muchos usuarios se han encontrado con mensajes de error 503 y dificultades para cargar proyectos. A su vez, algunos servicios basados en IA, como Claude o ChatGPT, han presentado problemas de acceso o funcionamiento irregular.
El impacto tampoco ha pasado desapercibido en el mundo del ocio digital. Videojuegos y servicios asociados como Fortnite, Valorant, League of Legends, Epic Games Store o Crunchyroll han sufrido cortes puntuales, errores de conexión con el servidor y fallos en funcionalidades clave. A efectos prácticos, muchos jugadores se han quedado sin poder iniciar sesión o sin poder completar partidas con normalidad.
Horarios y evolución de la incidencia
De acuerdo con los datos recopilados por páginas de monitorización y los comunicados oficiales, los primeros síntomas se han detectado alrededor de las 8:00-9:00 hora peninsular española, aunque no ha sido hasta aproximadamente las 10:00 cuando el volumen de quejas ha empezado a dispararse.
Cloudflare ha ido publicando actualizaciones cronológicas en su portal de estado. A las 08:56 UTC ha reconocido que estaba analizando un problema con el Panel de Control y las APIs. Minutos después ha repetido que la investigación seguía en marcha, confirmando que el impacto se extendía a los clientes que usan las APIs para gestionar sus servicios.
Poco después de las 9:20 (hora peninsular española), la compañía ha informado de que ya se había desplegado una corrección y que el sistema entraba en fase de supervisión. Esta fórmula implica que la solución técnica se ha aplicado, pero todavía se vigila de cerca el comportamiento de la red para asegurarse de que no persisten errores residuales ni aparecen nuevos impactos derivados.
En la práctica, esto se ha traducido en que algunas webs y aplicaciones han ido recuperando la normalidad de forma progresiva, mientras que otras seguían experimentando fallos puntuales. Es frecuente que, tras una caída de este tipo, el restablecimiento del servicio no sea inmediato y uniforme en todas las regiones o para todos los productos.
El propio CTO de Cloudflare ha querido dejar claro en la red social X que no se trata de un ciberataque. Ha explicado que la causa raíz está vinculada a cambios internos relacionados con la mitigación de vulnerabilidades recientes (como un CVE de React) y con la gestión de determinados registros de la red, y ha prometido una explicación detallada en un informe técnico.
Una caída que llega tras otros incidentes recientes
El episodio de hoy no es un caso aislado. Cloudflare ya había sufrido una interrupción global hace menos de un mes, que se prolongó durante unas cuatro horas y dejó fuera de juego a servicios tan conocidos como X (antes Twitter), ChatGPT, Canva, League of Legends, Movistar, La Caixa, MediaMarkt o DownDetector, entre muchos otros.
En aquella ocasión, la compañía explicó que el origen del problema estaba en un cambio de permisos en una base de datos interna. Ese ajuste provocó que el sistema empezara a generar miles de entradas adicionales en un archivo usado por el módulo de gestión de bots, el componente que distingue si un visitante es un humano o un programa automatizado.
A medida que el archivo crecía, duplicó su tamaño y superó el límite que el software podía manejar para encauzar el tráfico. El resultado fue un efecto dominó: el sistema de identificación de bots se saturó y empezó a lastrar el funcionamiento del resto de servicios que dependen de él. Aquella explicación técnica ya puso sobre la mesa lo delicado que puede ser un simple cambio de configuración en una infraestructura de esta envergadura.
El nuevo incidente se suma también a otras grandes caídas recientes en el ecosistema de la nube, como las sufridas por Amazon Web Services (AWS) o Microsoft Azure en los últimos meses. En todos los casos, una interrupción en uno de estos proveedores se traduce en fallos simultáneos en webs de todo tipo: desde banca y comercio electrónico hasta educación online, administraciones públicas y servicios de entretenimiento.
Esta repetición de incidentes en un periodo de tiempo relativamente corto ha reavivado el debate sobre la resiliencia de la infraestructura global de Internet y sobre hasta qué punto es saludable depender tanto de unos pocos proveedores. Cada vez que uno de ellos tropieza, el impacto se deja notar en la vida cotidiana de millones de personas, que ven cómo trámites rutinarios se vuelven imposibles durante horas.
Por qué un fallo en Cloudflare derriba medio Internet
Para entender el alcance de lo ocurrido, conviene recordar qué hace exactamente Cloudflare. La compañía actúa principalmente como red de distribución de contenidos (CDN) y proxy inverso, situándose entre los usuarios que visitan una web y el servidor de origen donde se aloja esa página.
Su red se encarga de replicar y acercar el contenido a los usuarios desde servidores distribuidos por todo el mundo, mejorando la velocidad de carga y reduciendo la latencia. De este modo, una tienda online alojada en un único servidor puede ofrecer una navegación ágil a usuarios de distintos países sin necesidad de desplegar su propia infraestructura global. A esto se suman servicios de seguridad, mitigación de ataques DDoS, protección frente a tráfico malicioso y opciones para cifrar tu DNS sin tocar el router.
Cloudflare ha llegado a afirmar que da soporte a más de 25 millones de sitios en Internet, lo que da una idea de su peso en la estructura de la red. Entre sus clientes hay bancos, medios de comunicación, redes sociales, plataformas de contenidos, servicios de pago y empresas de todo tipo. Cuando su sistema funciona con normalidad, la mayoría de los usuarios ni siquiera es consciente de su papel; cuando falla, las consecuencias se hacen evidentes al instante.
En la práctica, esto significa que si Cloudflare se cae, “medio Internet se viene abajo”. Expertos en operaciones y DevOps señalan que, en incidentes de este tipo, el usuario medio poco puede hacer más allá de esperar a que el proveedor recupere la operativa. Reiniciar el router o cambiar de dispositivo no resuelve nada si el problema está en la columna vertebral de la red.
Además de la CDN y el proxy inverso, muchas compañías utilizan servicios adicionales como Workers, reglas de firewall avanzadas, gestión de bots y otros productos integrados. Cuando alguno de estos componentes clave sufre una incidencia, puede generar errores muy diversos: páginas en blanco, formularios que no se envían, carritos de compra que se vacían solos, paneles de administración inaccesibles o flujos de pago que se interrumpen a mitad de proceso.
Dependencia creciente y vulnerabilidades estructurales
El suceso de hoy vuelve a poner el foco en la dependencia de empresas y administraciones de grandes proveedores de nube como Cloudflare, AWS o Azure. Este modelo les permite reducir costes, escalar rápidamente y aprovechar capas avanzadas de seguridad y rendimiento, pero a cambio introduce un punto único de fallo que afecta a miles de servicios a la vez.
Cuando uno de estos actores sufre una incidencia, el impacto no se limita a un sector concreto. Banca digital, comercio electrónico, redes sociales, educación online, videojuegos, plataformas de vídeo, servicios de IA o trámites administrativos pueden verse afectados simultáneamente, dejando a los usuarios sin acceso a herramientas que hoy muchos consideran imprescindibles.
Voces del sector tecnológico llevan tiempo advirtiendo de que, en estas situaciones, los dispositivos de los usuarios se convierten prácticamente en “pisapapeles”: todo funciona correctamente a nivel local, pero el “cerebro” que coordina gran parte del tráfico está temporalmente fuera de juego. De ahí que algunos especialistas recomienden, con cierta sorna pero también con realismo, aprovechar una caída de este tipo para desconectar un rato, ya que poco se puede hacer hasta que los equipos técnicos de estos proveedores terminan de aplicar sus correcciones.
Este tipo de incidentes está impulsando a muchas organizaciones a replantearse sus estrategias de redundancia y multi-nube, así como a estudiar alternativas para diversificar proveedores en componentes críticos. Sin embargo, en la práctica, replicar el alcance global y las capacidades técnicas de empresas como Cloudflare no es trivial ni barato, por lo que la concentración de servicios en pocas manos sigue siendo la norma.
Tras lo ocurrido, Cloudflare mantiene abiertos sus canales de notificación y su portal de estado, desde donde sus clientes pueden seguir la evolución de la incidencia y sus posibles derivadas. Mientras la compañía termina de afinar sus sistemas y de publicar los detalles técnicos de lo ocurrido, lo que queda claro es que cualquier tropiezo en uno de estos pilares de la red tiene un efecto inmediato y muy visible en la vida diaria de millones de usuarios en España, Europa y el resto del mundo.
Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.