- ONNX Runtime permite ejecutar modelos ONNX de forma rápida y multiplataforma, aprovechando CPU, GPU, NPU y otros aceleradores.
- Los modelos entrenados en frameworks como PyTorch o TensorFlow pueden exportarse a ONNX y desplegarse en aplicaciones .NET, C++ o móviles sin reentrenar.
- En Windows, ONNX Runtime se integra con DirectML, WinUI, Windows ML y AI Dev Gallery para vision por ordenador y LLM en local.
- El ecosistema ONNX facilita portar modelos como ResNet o YOLO a producción en entornos cloud, edge, móvil e industrial.
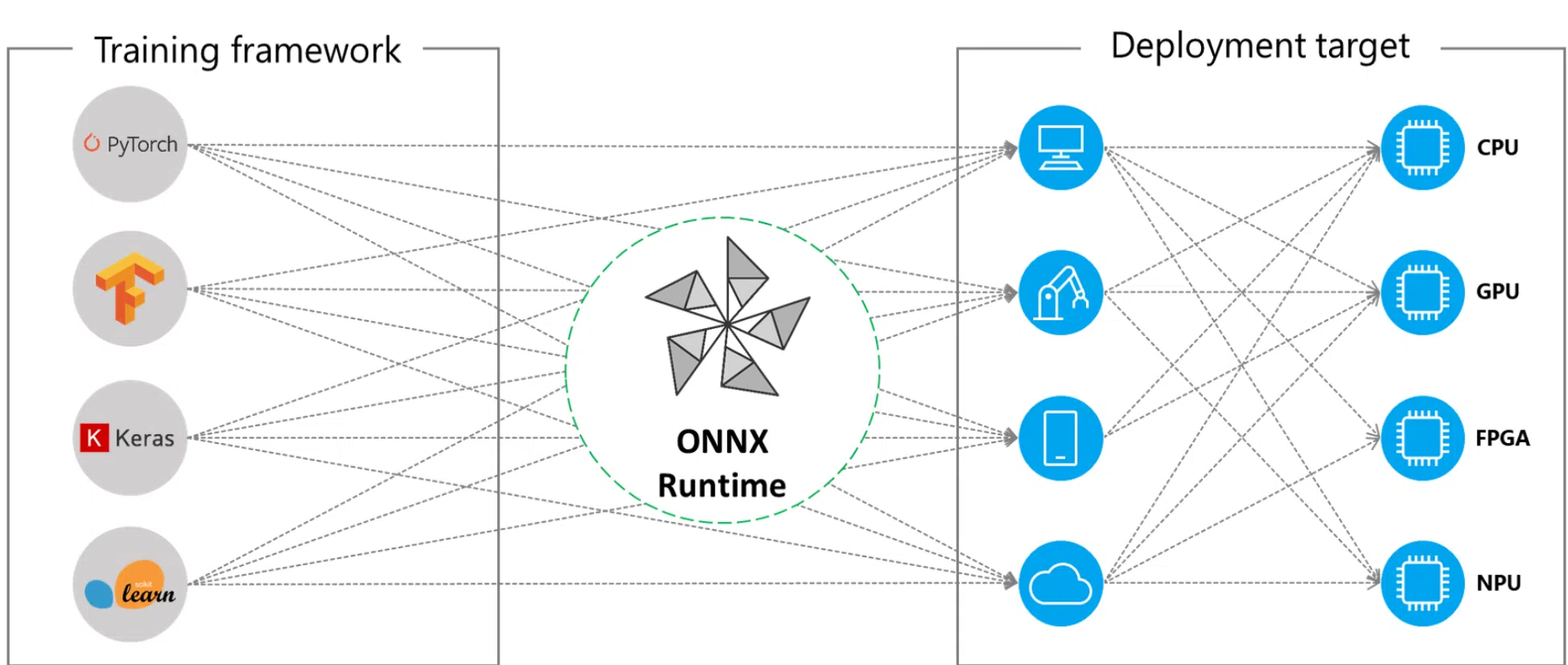
Si trabajas con inteligencia artificial y machine learning en tu día a día, tarde o temprano te vas a topar con modelos en formato ONNX y con el motor ONNX Runtime. Esta combinación se ha convertido en uno de los pilares para llevar modelos de IA desde el entorno de laboratorio hasta aplicaciones reales en Windows, la nube, móviles e incluso dispositivos de borde.
En esta guía vamos a ver, con calma pero sin rodeos, cómo sacar partido a ONNX Runtime tanto para modelos clásicos como para LLM y visión por ordenador. Te explicaré qué es exactamente, cómo se relaciona con frameworks como PyTorch o TensorFlow, cómo integrarlo en aplicaciones .NET y WinUI, cómo aprovechar aceleración por GPU, NPU o FPGA, y cuáles son los escenarios más interesantes de uso práctico.
Qué es ONNX y qué resuelve ONNX Runtime
ONNX (Open Neural Network Exchange) es un estándar abierto para representar modelos de IA de forma que puedan moverse entre distintos frameworks y hardware sin rehacer el trabajo. Piensa en ONNX como en un “traductor universal” de redes neuronales: entrenas en PyTorch, exportas a ONNX y luego puedes ejecutar el mismo modelo en otros entornos optimizados.
Internamente, un modelo ONNX se define como un grafo computacional estático, donde cada nodo representa una operación matemática (convolución, activación, normalización, etc.) y las aristas representan el flujo de tensores de datos. Este grafo utiliza un conjunto de operadores estándar que los distintos motores de ejecución saben interpretar.
ONNX Runtime es el motor de inferencia de alto rendimiento pensado para ejecutar esos modelos ONNX. Es multiplataforma, está muy optimizado y permite enchufar distintos proveedores de ejecución (execution providers) para aprovechar la CPU, GPU, NPU, FPGA u otros aceleradores de hardware sin que tengas que cambiar tu código de inferencia.
En la práctica, ONNX Runtime actúa como una capa de compatibilidad y aceleración: recibe un único archivo .onnx y se encarga de ejecutarlo usando el mejor hardware disponible, aplicando optimizaciones como fusión de operadores, planificación eficiente de memoria y soporte para modelos cuantizados.
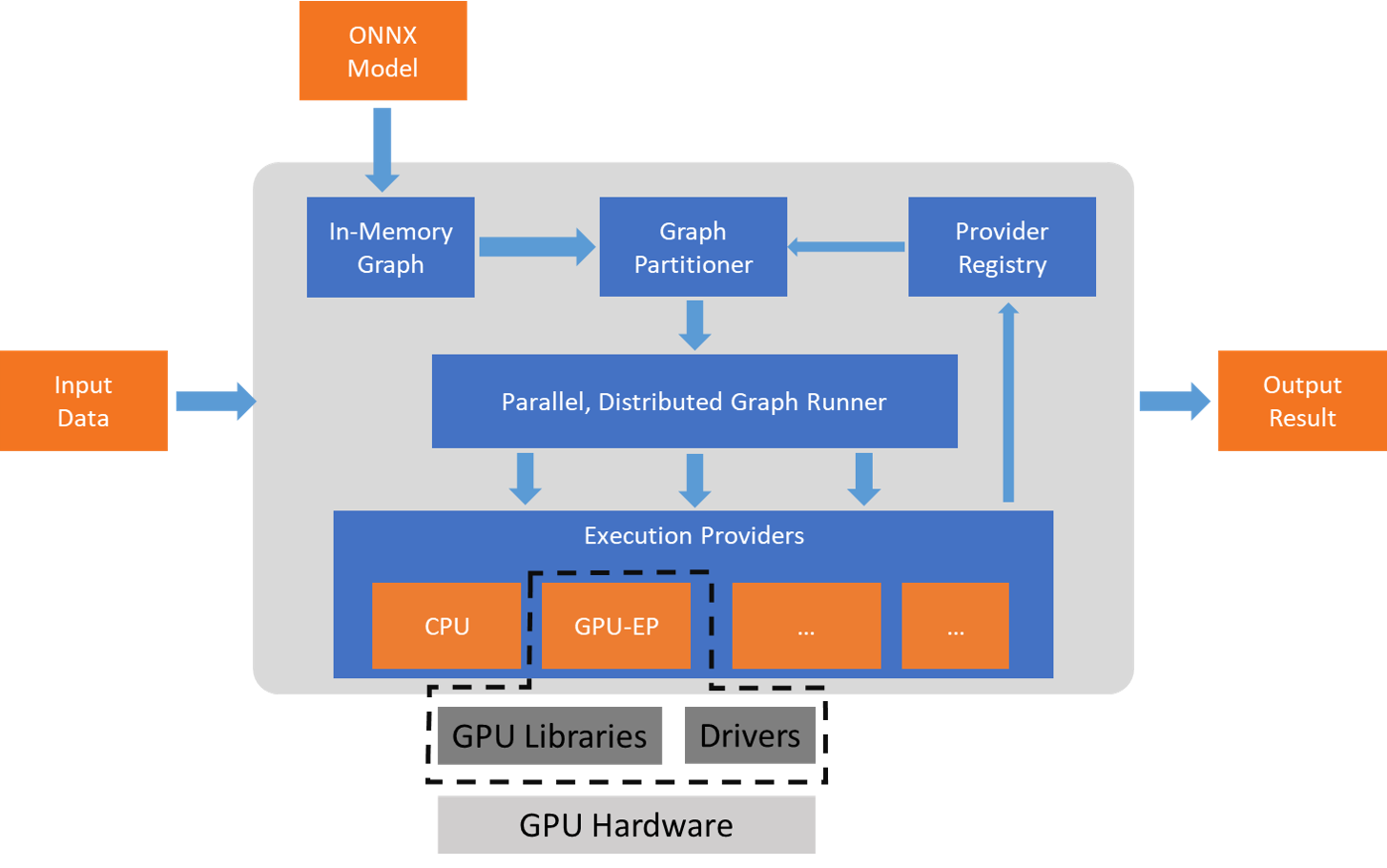
Ventajas de usar ONNX Runtime en local
Una de las grandes gracias de ONNX Runtime es que permite ejecutar modelos de IA de forma completamente local, sin depender de servicios en la nube. Esto encaja muy bien con escenarios donde la privacidad, la latencia o el coste son críticos.
La primera ventaja evidente es la privacidad: los datos no salen de tu máquina. Si tienes que procesar imágenes médicas, documentos internos o conversaciones sensibles, poder ejecutar el modelo en el dispositivo evita enviar información a terceros, lo que simplifica el cumplimiento normativo y reduce riesgos.
También destaca el aspecto económico, ya que no necesitas pagar por inferencia en servicios cloud ni preocuparte por límites de uso. Una vez instalado el modelo y ONNX Runtime, puedes hacer todas las predicciones que quieras en tu propio hardware.
A nivel de experiencia de usuario, la latencia baja marca la diferencia: al no depender de la red, las respuestas del modelo son prácticamente instantáneas, algo fundamental en aplicaciones interactivas, juegos, herramientas de edición o sistemas de control en tiempo real.
Finalmente, está el factor de control: tú decides cómo versionar, actualizar o reemplazar los modelos, sin atarte a una API externa. Puedes integrar ONNX Runtime con tus sistemas existentes en C#, C++, Python u otros lenguajes, y automatizar todo el ciclo de despliegue de modelos.
Modelos ONNX y su relación con los frameworks de entrenamiento
Un modelo de IA en formato ONNX es una combinación de estructura de red, pesos entrenados y definición clara de entradas y salidas. La estructura describe las capas y operaciones, los pesos contienen el conocimiento aprendido durante el entrenamiento y las especificaciones de entrada/salida indican qué formatos de datos admite el modelo.
Generalmente, entrenas el modelo en frameworks como PyTorch, TensorFlow o Keras utilizando sus formatos nativos (.pt, .pb, .h5, etc.). Una vez que estás satisfecho con el rendimiento, exportas ese modelo al formato .onnx utilizando las herramientas oficiales de cada framework o librerías auxiliares.
En cuanto a interoperabilidad, ONNX te evita tener que reescribir o volver a entrenar modelos al cambiar de entorno. Por ejemplo, puedes entrenar un modelo de visión en PyTorch y luego usarlo en una aplicación móvil gracias a ONNX Runtime for Mobile, o integrarlo en un backend en C++ sin cargar todo el stack de Python.
Además, el estándar ONNX incluye soporte para operadores cuantizados y distintos conjuntos de operadores (opsets), lo que facilita adaptar el mismo modelo a diferentes niveles de precisión (por ejemplo, pasar de float32 a int8) y a nuevas capacidades de hardware conforme van apareciendo.
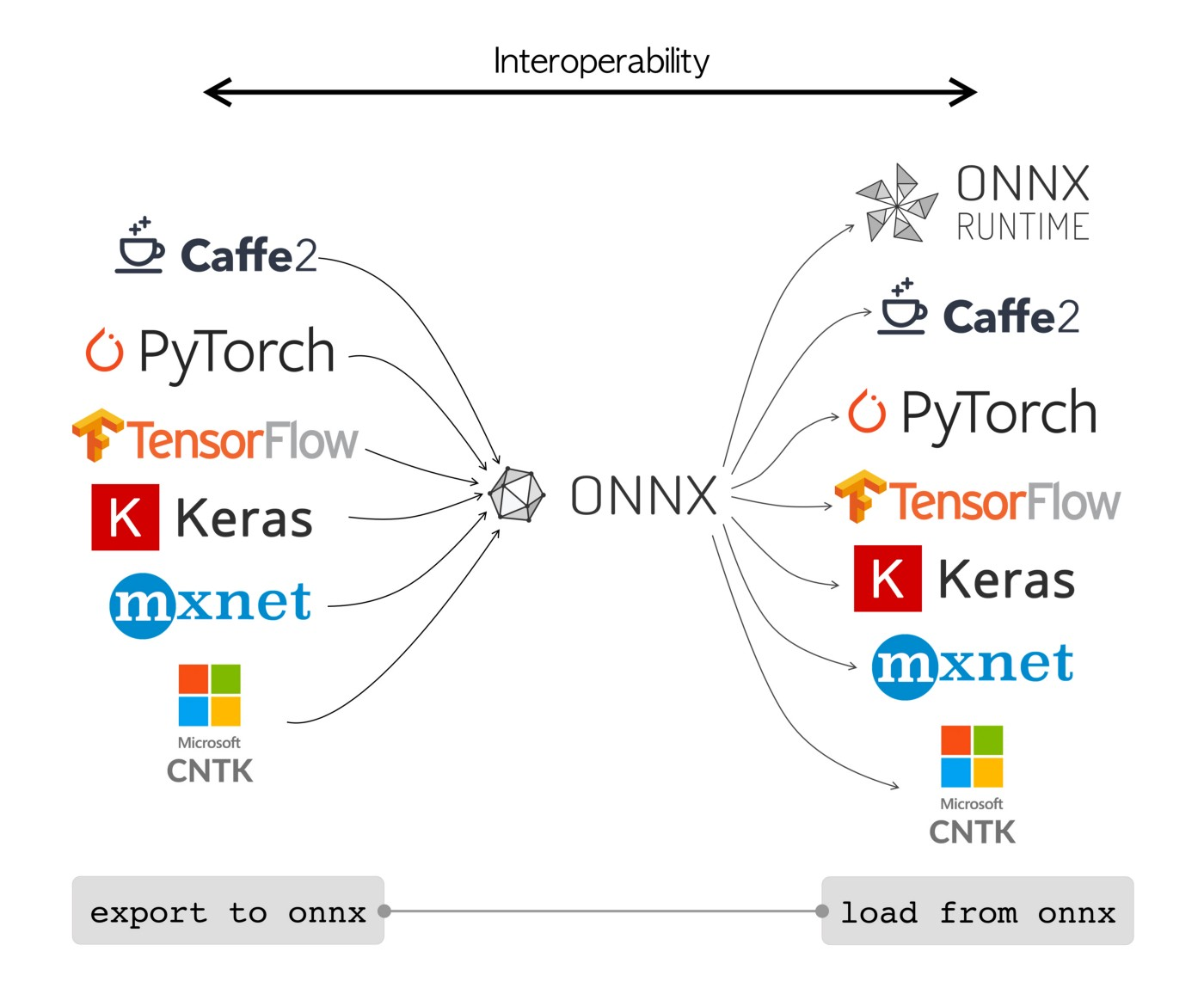
Cómo funciona ONNX Runtime y sus proveedores de ejecución
El corazón de ONNX Runtime es un motor de inferencia optimizado que interpreta el grafo ONNX y decide cómo ejecutar cada operación de la forma más eficiente posible. Para ello se apoya en los llamados execution providers, que son módulos especializados para distintos tipos de hardware.
Entre los proveedores más usados está DirectML en Windows, que permite aprovechar GPU y NPU a través de una API unificada. Al usar el proveedor DirectML, tu aplicación puede correr el mismo modelo ONNX en una amplia gama de tarjetas gráficas y aceleradores integrados sin cambios de código.
ONNX Runtime también se integra con aceleradores específicos como las FPGA Xilinx U250, a través de bibliotecas como Vitis AI. En este caso, Microsoft y Xilinx han trabajado juntos para que ONNX Runtime pueda ejecutar modelos en estas FPGA aprovechando al máximo su capacidad de paralelización.
Otra pieza clave es la integración con Windows ML y el catálogo de Execution Providers de Windows. Aplicaciones como AI Dev Gallery utilizan este catálogo para asegurarse de que los proveedores certificados están registrados y listos, y así elegir automáticamente la mejor combinación de CPU, GPU o NPU disponible en el dispositivo.
Por último, ONNX Runtime se usa también como backend para entornos de producción críticos como Bing Semantic Precise Image Search, donde se exige un rendimiento altísimo y estabilidad. En estos escenarios, su capacidad para optimizar grafos y gestionar memoria resulta clave para servir millones de inferencias al día.
Crear una app WinUI en C# que use ONNX Runtime
Un ejemplo muy ilustrativo del uso de ONNX Runtime en Windows es crear una aplicación de escritorio con WinUI 3 en C# que cargue un modelo ONNX de clasificación de imágenes (como ResNet-50), ejecute inferencias aceleradas por GPU y muestre las predicciones al usuario.
El primer paso es preparar el entorno de desarrollo: necesitas un dispositivo Windows con modo desarrollador activado y tener instalado Visual Studio 2022 o superior con la carga de trabajo de “Desarrollo de aplicaciones de escritorio .NET”. Con eso tendrás todo lo necesario para trabajar con proyectos WinUI empaquetados.
Dentro de Visual Studio, debes crear un nuevo proyecto de tipo “Aplicación vacía, empaquetada (WinUI 3 en escritorio)” usando C#. Un nombre habitual para este tipo de ejemplo podría ser algo como ONNXWinUIExample, aunque puedes llamarlo como prefieras, siempre que mantengas la estructura clara.
A partir de ahí, la idea es añadir al proyecto las dependencias de NuGet que permiten usar ONNX Runtime, procesar imágenes y hablar con DirectX. Esto se hace desde el Administrador de paquetes NuGet en la solución, buscando los paquetes y eligiendo la versión estable más reciente.

Paquetes NuGet y configuración de la interfaz
Para este ejemplo de clasificación de imágenes con aceleración en Windows, los paquetes básicos a instalar son Microsoft.ML.OnnxRuntime.DirectML, SixLabors.ImageSharp y SharpDX.DXGI. Cada uno cubre una parte concreta del flujo de trabajo.
El paquete Microsoft.ML.OnnxRuntime.DirectML añade soporte para usar ONNX Runtime con GPU vía DirectML. Es el que te permite ejecutar modelos ONNX de forma eficiente en el hardware gráfico del dispositivo sin que tengas que ocuparte de la gestión de bajo nivel.
La librería SixLabors.ImageSharp proporciona utilidades avanzadas para cargar, redimensionar y procesar imágenes en .NET. La usamos para transformar la imagen elegida por el usuario en el tensor normalizado que espera el modelo de clasificación (por ejemplo, 224×224 píxeles en RGB).
Por su parte, SharpDX.DXGI expone funcionalidades de DirectX desde C# y nos posibilita seleccionar adaptadores gráficos concretos (como la primera GPU disponible) para asociarlos a la sesión de inferencia de ONNX Runtime cuando configuramos DirectML como execution provider.
Una vez tengas instalados los paquetes, es recomendable añadir las directivas using correspondientes en el archivo MainWindow.xaml.cs para referenciar fácilmente los espacios de nombres de OnnxRuntime, Tensors, SharpDX y ImageSharp. De esta forma el código de la ventana principal puede usar directamente todas estas APIs.
Añadir el modelo ONNX y construir la interfaz sencilla
El siguiente paso consiste en incluir el modelo ONNX en el propio proyecto. Una práctica habitual es crear una carpeta llamada “model” dentro del proyecto y copiar allí el archivo .onnx descargado, por ejemplo el modelo ResNet50 v2 (resnet50-v2-7.onnx) desde el repositorio oficial de ONNX Models en GitHub.
En el Explorador de soluciones de Visual Studio, conviene configurar la propiedad “Copiar al directorio de salida” del archivo de modelo para que se copie automáticamente al compilar la aplicación. La opción “Copiar si es más reciente” suele ser suficiente para asegurarse de que el modelo esté disponible junto al ejecutable.
La interfaz de usuario del ejemplo puede ser muy sencilla: un botón para seleccionar una fotografía desde el disco, un control Image para mostrarla y un TextBlock donde listar las predicciones. Todo ello se puede organizar con un Grid de tres columnas para que cada elemento ocupe su espacio.
En el archivo MainWindow.xaml, puedes sustituir el StackPanel inicial generado por plantilla por un Grid con tres columnas: botón en la primera, imagen en la segunda y resultados de texto en la tercera. El botón disparará un evento de clic que será el responsable de todo el flujo de inferencia.
Para hacer la experiencia más cómoda, es útil ajustar el control Image para que limite el ancho máximo de la imagen mostrada (por ejemplo, 300 píxeles), de forma que no rompa el diseño, y mantener el TextBlock alineado en la parte superior para que el usuario pueda leer las predicciones sin hacer scroll.
Inicializar la sesión de ONNX Runtime con DirectML
Una vez que la interfaz está definida, hay que preparar el motor de inferencia. En la clase de la ventana principal, suele declararse un campo privado de tipo InferenceSession y una ruta base hacia la carpeta del modelo. Esto permite inicializar la sesión sólo una vez y reutilizarla en sucesivas inferencias.
La función de ayuda InitModel se encarga de crear una instancia de Factory1 de SharpDX para obtener el adaptador gráfico (normalmente el primero, índice 0) y, con ese identificador de dispositivo, configurar un objeto SessionOptions de ONNX Runtime donde se indica que se utilizará el execution provider DirectML con dicho dispositivo.
En ese mismo método, se crea la InferenceSession pasando la ruta completa al archivo .onnx y las opciones de sesión. También es habitual establecer el nivel de severidad del log para depurar (por ejemplo, ORT_LOGGING_LEVEL_INFO), lo que ayuda a entender qué está ocurriendo internamente si hay algún problema.
Es importante que InitModel compruebe primero si la sesión ya está creada. Si el campo privado _inferenceSession no es nulo, no hace falta repetir la inicialización. Así evitas cargar el modelo una y otra vez, ahorras tiempo y recursos, y solo pagas el coste inicial la primera vez que se usa.
Con esta estructura, tu aplicación ya tiene un motor ONNX Runtime configurado para usar DirectML sobre el adaptador gráfico seleccionado, listo para recibir tensores de entrada y devolver salidas de modelo con aceleración por hardware cuando esté disponible.
Carga y preprocesado de imágenes con ImageSharp
El flujo de inferencia suele arrancar desde el controlador del clic del botón. En este manejador, se utiliza un FileOpenPicker para permitir que el usuario elija una imagen desde el sistema de archivos, restringiendo las extensiones a formatos comunes como .jpg, .jpeg, .png o .gif.
Una vez seleccionada la imagen, se puede mostrar inmediatamente en el control Image de la interfaz usando un BitmapImage y estableciendo su origen a partir del stream del archivo. Con esto, el usuario ve la foto sobre la que se van a generar predicciones.
Para preparar la entrada del modelo, entra en juego SixLabors.ImageSharp, que permite abrir la imagen como Image<Rgb24> y redimensionarla a las dimensiones esperadas por el modelo, habitualmente 224×224 píxeles para modelos tipo ResNet de clasificación generalista.
En este punto se suele aplicar un Resize con modo Crop para ajustar la imagen de forma adecuada, manteniendo la proporción y recortando si hace falta, y después se guarda en un stream de memoria con el mismo formato que se detectó inicialmente. Este paso asegura que todos los datos de entrada tengan el mismo tamaño.
El último paso del preprocesado es la normalización: se crea un DenseTensor<float> con forma (batch de 1, tres canales RGB, alto y ancho), y se recorre la imagen línea a línea normalizando cada canal por separado usando medias y desviaciones típicas habituales (255* y 255*).
Configurar las entradas y ejecutar la inferencia
Una vez que el tensor de imagen está rellenado, hay que vincularlo a un OrtValue para que ONNX Runtime pueda consumirlo. Lo ideal es crear este valor desde memoria usando OrtValue.CreateTensorValueFromMemory con el buffer del DenseTensor, evitando copias adicionales de datos.
Se construye un diccionario donde la clave es el nombre de la entrada del modelo (por ejemplo, «data») y el valor es el OrtValue recién creado. Este diccionario se pasa después a la sesión de inferencia para indicar qué tensores se deben alimentar a las entradas del grafo.
Antes de lanzar la inferencia, conviene asegurarse de que la sesión está inicializada llamando a InitModel si aún no se ha hecho. Así garantizas que el modelo está en memoria y configurado con el proveedor de ejecución adecuado (DirectML en este caso).
Para ejecutar el modelo se llama a _inferenceSession.Run pasando unas RunOptions, el diccionario de entradas y la colección de nombres de salidas. El resultado es una colección de OrtValue de solo lectura que contienen los tensores de salida del modelo.
Este proceso encapsula toda la lógica de ejecución en ONNX Runtime, de modo que no tienes que preocuparte por detalles internos de planificación en CPU o GPU. Tu código sigue siendo relativamente sencillo: preparas la entrada, llamas a Run y recoges las salidas.
Postprocesado, softmax y selección de predicciones
La salida de un modelo de clasificación suele ser un vector de logits, es decir, valores sin normalizar para cada clase posible. En este ejemplo, los logits se obtienen a partir del primer OrtValue de resultados usando GetTensorDataAsSpan<float> y convirtiéndolo a un array para manipularlo con LINQ.
Para transformar estos logits en probabilidades entendibles, se aplica una función softmax, que calcula exponenciales de cada valor y los normaliza para que sumen 1. De esta forma, cada índice del vector representa la confianza del modelo en que la imagen pertenezca a esa clase.
El siguiente paso es cruzar estas probabilidades con un mapa de etiquetas (LabelMap) que contenga los nombres humanos de cada clase en el mismo orden que se usó en el entrenamiento del modelo. El índice del array de salida debe corresponder exactamente con el índice de la etiqueta en LabelMap.
Para presentar la información de forma clara al usuario, se suele ordenar la colección por confianza descendente y quedarse con las 10 etiquetas más probables. Cada una se representa con un objeto auxiliar que contiene la etiqueta y la probabilidad asociada.
Finalmente, se recorre esta lista de predicciones y se construye una cadena de texto que se muestra en el TextBlock de la interfaz, incluyendo cada etiqueta y su nivel de confianza. De esta forma, el usuario ve rápidamente qué objetos considera el modelo más probables en la imagen seleccionada.
Clases auxiliares: Prediction y LabelMap
Para manejar los resultados de una forma más limpia, suele definirse una clase sencilla llamada Prediction, con dos propiedades: Label y Confidence. Esta clase se utiliza al proyectar las probabilidades junto con los nombres de clase en una secuencia de resultados tipados.
La propiedad Label puede ser de tipo object para mayor flexibilidad, aunque en la práctica se suele usar como string con el nombre de la categoría que devuelve el modelo. La Confidence es un float que almacena la probabilidad calculada por softmax.
Por otro lado, hace falta una clase estática LabelMap con un array público de cadenas llamado Labels. Este array contiene todas las etiquetas con las que se entrenó el modelo, en el orden exacto en el que se utilizaron durante el entrenamiento y están codificadas en el archivo ONNX.
En el caso de modelos tipo ImageNet, la lista de etiquetas es extensa y suele incluir cientos o miles de clases (por ejemplo, “tench”, “goldfish”, “great white shark”, etc.). Lo habitual es tomar esta lista directamente de los ejemplos del repositorio de ONNX Runtime para evitar desajustes de índice.
Al combinar Prediction y LabelMap, el código de postprocesado se simplifica bastante: se recorren las probabilidades, se asocian con sus etiquetas y se ordenan por confianza, ofreciendo un resultado final legible y fácil de mostrar en la interfaz de usuario.
ONNX Runtime con LLM en AI Dev Gallery
Además de modelos de visión, ONNX Runtime también soporta modelos de lenguaje grande (LLM) a través del formato ONNX Runtime GenAI. Microsoft ofrece una aplicación de Windows llamada AI Dev Gallery, disponible en Microsoft Store, que permite probar de forma interactiva estos modelos ONNX LLM.
La aplicación incluye ejemplos de generación de texto, chat, resumen, análisis de sentimiento, moderación de contenido y otros escenarios, todos ellos basados en LLM en formato GenAI. Puedes cargar modelos previamente convertidos o convertir los tuyos propios desde frameworks habituales.
Entre los modelos soportados actualmente para conversión al formato ONNX Runtime GenAI se encuentran DeepSeek R1 Distill Qwen 1.5B, Phi 3.5 Mini, Qwen 2.5-1.5B y Llama 3.2 1B, principalmente en variantes orientadas a “instrucción” o “prompting”. Estos modelos se adaptan bien a tareas de chat y generación de texto en local.
La propia AI Dev Gallery se integra con la extensión AI Toolkit para Visual Studio Code, lo que permite lanzar directamente la herramienta de conversión desde el selector de modelos. Si no tienes instalada la extensión, puedes buscar “AI Toolkit” en el marketplace de VS Code y, una vez instalada, usarla para convertir tus LLM al formato GenAI.
Después de convertir o descargar un modelo, basta con volver al selector de modelos de AI Dev Gallery, elegir la pestaña de modelos personalizados y añadir el archivo desde disco. A partir de ahí, puedes seleccionar tu LLM en los ejemplos interactivos y ver el comportamiento en diferentes tareas de texto.
Integración con Microsoft.Extensions.AI y WinML
Por debajo de la interfaz de AI Dev Gallery, la ejecución de LLM en formato GenAI se gestiona mediante el cliente OnnxRuntimeGenAIChatClient, que actúa como puente entre ONNX Runtime y las abstracciones de Microsoft.Extensions.AI para chat.
Este cliente se ajusta a interfaces como IChatClient y tipos como ChatMessage, de modo que el código que consume el modelo trabaja con mensajes de alto nivel en lugar de lidiar con tensores y detalles de bajo nivel. Esto permite que la misma aplicación pueda cambiar de backend (por ejemplo, de un servicio en la nube a un modelo local ONNX) con cambios mínimos.
En la factoría OnnxRuntimeGenAIChatClientFactory se realiza el registro de los proveedores de ejecución de Windows ML (WinML) usando ExecutionProviderCatalog.GetDefault y llamadas asincrónicas para asegurar y registrar los proveedores certificados antes de crear el cliente de chat.
Cuando se crea el OnnxRuntimeGenAIChatClient, se le pasa la ruta al modelo ONNX y una plantilla de prompt (LlmPromptTemplate) que define el formato de los roles system, user y assistant, así como las secuencias de parada que indican dónde cortar la generación de texto.
Con todo esto en su sitio, la aplicación puede recibir mensajes, llamar a GetStreamingResponseAsync y volcar las respuestas en la interfaz de forma incremental, consiguiendo una experiencia de chat fluida con el modelo ONNX local, aprovechando la aceleración de hardware disponible a través de WinML y ONNX Runtime.
Exportar modelos YOLO a ONNX y desplegarlos
Más allá de los ejemplos de Microsoft, el ecosistema ONNX también es muy popular en librerías de terceros como Ultralytics, donde convertir un modelo YOLO a ONNX es cuestión de pocas líneas de código. Esto abre la puerta a desplegar el mismo detector de objetos en distintos tipos de dispositivos.
Con la API de Ultralytics, puedes cargar un modelo YOLO preentrenado (por ejemplo, yolo11n.pt) y exportarlo con la opción format=»onnx». El proceso se encarga de traducir la arquitectura y los pesos al estándar ONNX y genera un archivo .onnx listo para usar.
Una vez que tienes el modelo en ONNX, es posible integrarlo en aplicaciones móviles, web o IoT utilizando ONNX Runtime y sus variantes específicas. En móviles, ONNX Runtime for Mobile ofrece una versión recortada y optimizada para consumir menos recursos, mientras que en edge e IoT se utilizan builds adaptadas a dispositivos con poca memoria.
En entornos industriales, la conversión a ONNX facilita integrar modelos de visión por ordenador en sistemas heredados C++ o C#, sin necesidad de incrustar intérpretes de Python. Esto simplifica el mantenimiento y reduce los requisitos de despliegue en sistemas donde cada dependencia cuenta.
Comparado con usar formatos nativos de framework, apoyarse en ONNX reduce la fricción cuando se pasa de prototipos de laboratorio a soluciones de producción, ya que evita reescrituras costosas y permite aprovechar al máximo las optimizaciones de ONNX Runtime, TensorRT u otros motores compatibles con el formato.
ONNX Runtime se coloca como una pieza clave para quienes quieren ejecutar modelos de IA en local, aprovechar aceleración de hardware y mantener flexibilidad entre frameworks y plataformas, tanto en aplicaciones de escritorio como en móviles, nube o dispositivos de borde.

Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.