- MLflow centraliza el ciclo de vida de modelos ML con tracking, proyectos y gestión de modelos.
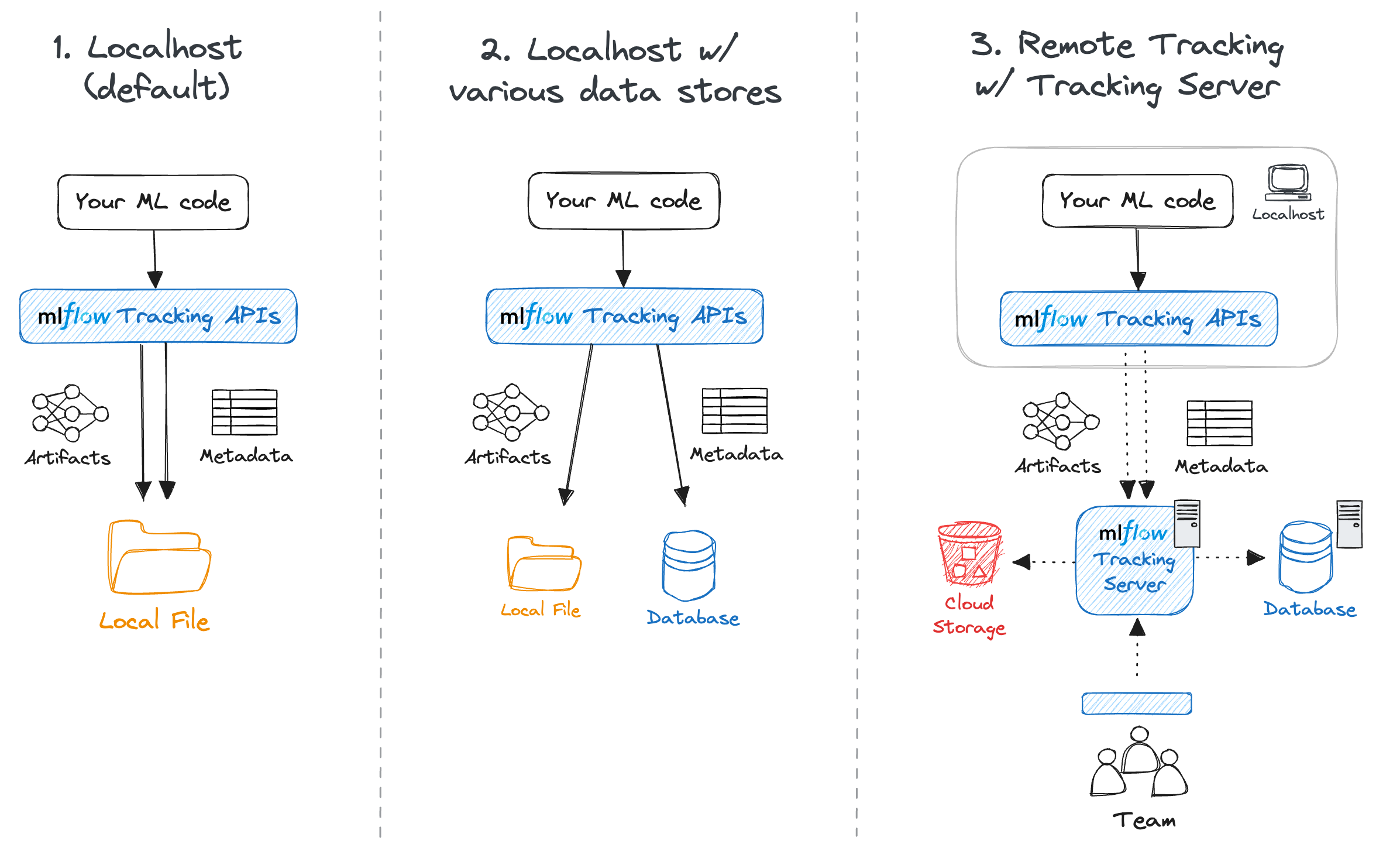
- Un despliegue robusto requiere servidor, base de datos relacional y almacén de artefactos.
- El tracking de experimentos permite comparar runs, reproducir entrenamientos y versionar modelos.
- MLflow se integra con múltiples frameworks y nubes, y puede ampliarse con plugins y APIs REST.
Si te gusta crear modelos de datos pero te cuesta mantener el orden en tus experimentos de machine learning, estás en el sitio adecuado. A medida que los proyectos crecen, probar variantes de modelos, preprocesados, hiperparámetros y conjuntos de datos se convierte en un caos si no tienes una herramienta que lo organice todo.
Ahí es donde entra en juego MLflow como pieza central de MLOps: una plataforma open source que te ayuda a controlar el ciclo de vida completo de tus modelos, desde los primeros experimentos hasta el despliegue en producción. En este tutorial de MLflow vas a aprender, paso a paso, qué es, cómo instalarlo en un servidor, cómo integrar una base de datos y un almacenamiento de artefactos, cómo registrar tus experimentos y cómo publicar modelos como APIs listas para usarse.
Qué es MLflow y por qué se usa tanto en MLOps
MLflow es una herramienta de código abierto para gestionar el ciclo de vida de modelos de machine learning, muy centrada en resolver los problemas típicos de tener muchos experimentos, múltiples versiones de modelos y diferentes entornos de ejecución.
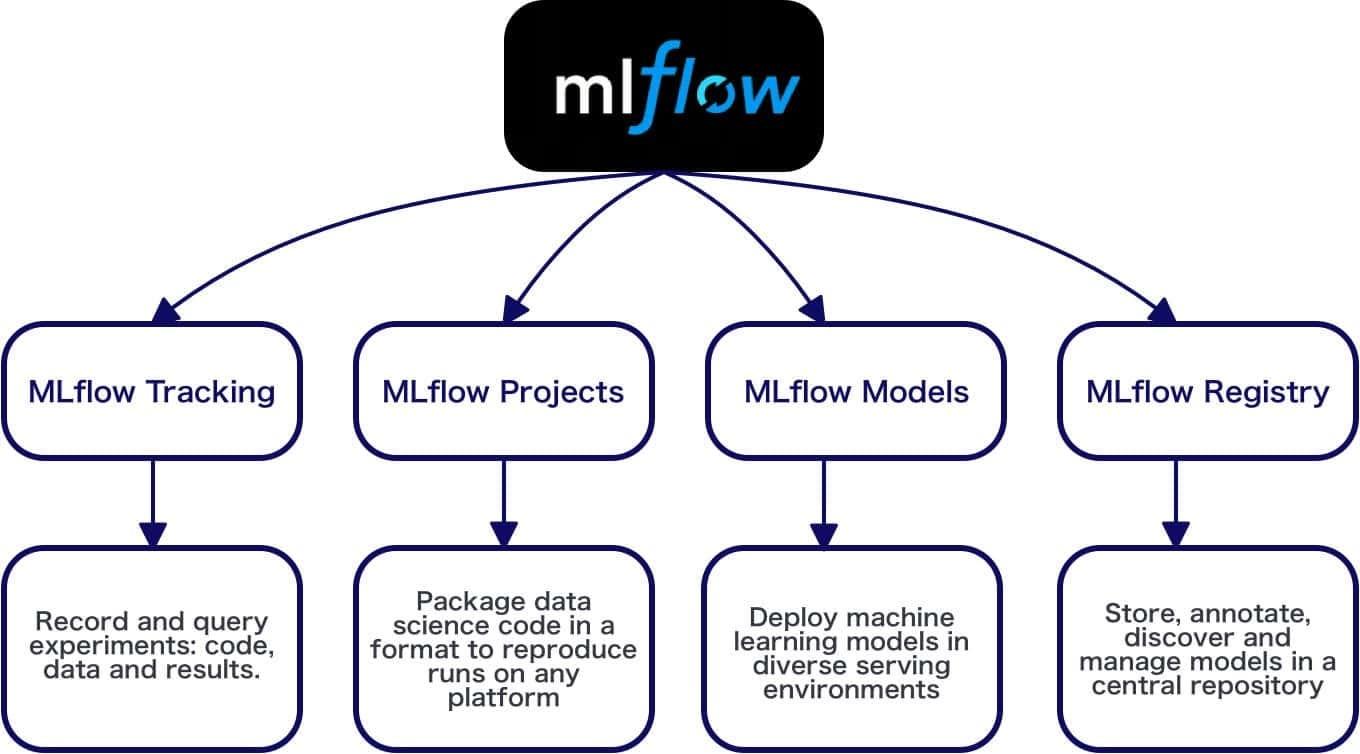
La plataforma se apoya en varios componentes clave que puedes usar juntos o por separado según tus necesidades, sin tener que adoptar todo el stack de golpe, algo que hace que MLflow sea muy flexible y agnóstico del ecosistema.
Componentes principales de MLflow
Dentro de MLflow hay varios módulos pensados para atacar problemas específicos del desarrollo de modelos, cada uno con su propia API y forma de trabajar, pero todos integrados bajo la misma interfaz de seguimiento.
- Tracking: se encarga de registrar parámetros, métricas, artefactos y modelos en cada ejecución de entrenamiento, de forma que puedas comparar fácilmente diferentes runs dentro de un experimento.
- Projects: permite empaquetar el código y las dependencias de un proyecto de ML para hacerlo reproducible, de manera que otra persona (o tú mismo en el futuro) pueda ejecutar exactamente el mismo flujo.
- Models: gestiona el versionado, registro y despliegue de modelos en distintos formatos y destinos, incluyendo endpoints HTTP propios, integración con servicios cloud como Azure ML o AWS SageMaker y exportación para entornos como Apache Spark.
Un detalle interesante es que no estás obligado a usar todos los módulos. Hay equipos que solo utilizan Tracking y Models, y dejan a un lado Projects porque su flujo de trabajo ya tiene resuelta la parte de empaquetado con Docker o similares. La gracia de MLflow es que se adapta relativamente bien a diferentes formas de trabajar.
Además, MLflow no viene atado a una única base de datos ni a un único sistema de ficheros: puedes combinar distintos backends de almacenamiento (MySQL, PostgreSQL, SQLite, S3, Google Cloud Storage, etc.) y desplegar los modelos tanto en el propio servidor como en plataformas externas.
Requisitos para montar un servidor de MLflow en producción
Antes de ponerte a loguear modelos como si no hubiera un mañana, necesitas tener un servidor de MLflow bien configurado. No es complicado, pero sí hay varias piezas que deben encajar: máquina virtual, base de datos, almacenamiento de artefactos y alguna regla de red.
En la práctica, el despliegue típico de MLflow en un entorno de equipo se basa en tres elementos principales que conviene separar lo mejor posible para que escale y sea mantenible.
1. Máquina virtual o servidor donde correr MLflow
Lo primero es disponer de una máquina virtual o servidor donde se ejecutará el proceso de MLflow, su interfaz web y, opcionalmente, los endpoints de modelos. Puedes hacerlo on-premise o en la nube; un ejemplo muy habitual es usar una instancia pequeña en Google Cloud, AWS o Azure.
En Google Cloud, por ejemplo, se puede crear una VM desde Compute Engine, incluso aprovechando tipos muy ligeros como las e2-micro gratuitas para entornos de prueba. Tras crear la instancia, te conectas por SSH desde la consola del proveedor y ya estás dentro del sistema para instalar dependencias.
2. Base de datos para los metadatos del tracking
El servidor de MLflow necesita una base de datos donde guardar la información de seguimiento: parámetros, métricas, referencias a artefactos, información de runs, etc. MLflow soporta varios backends, pero en entornos serios se suele tirar de:
- PostgreSQL
- MySQL
- SQLite (solo recomendable para pruebas o uso local)
En muchos despliegues se instala la base de datos en la misma máquina virtual que el servidor de MLflow para simplificar, aunque para proyectos serios suele ser mejor tener la base de datos como servicio gestionado o en un servidor separado, por rendimiento y seguridad.
3. Almacenamiento de artefactos (modelos, datos, gráficos…)
Además de los metadatos, MLflow necesita un repositorio de artefactos donde guardar todo lo que no son parámetros o métricas: modelos serializados, ficheros de datos, gráficos, informes, etc. Puedes usar el propio disco de la VM, pero lo más habitual en producción es utilizar un datalake tipo:
- Amazon S3
- Google Cloud Storage
- Azure Blob Storage
En un ejemplo sobre Google Cloud, lo más natural es crear un bucket de Cloud Storage dedicado a MLflow y usar su URI (por ejemplo, gs://nombre_del_bucket) como ubicación de artefactos del servidor y de los clientes.
Instalación de MLflow paso a paso en una máquina virtual
Una vez tienes la VM creada y accesible por SSH, el siguiente paso es instalar MLflow y sus dependencias. Lo más cómodo suele ser trabajar con entornos aislados, por ejemplo usando Conda o Miniconda para no ensuciar el sistema global.
En una sesión típica, descargas e instalas Miniconda, aceptas la licencia y añades Conda al PATH. Después, activas el entorno base o creas uno nuevo para MLflow, donde instalarás la librería principal y, si quieres, todos los extras útiles.
Instalar MLflow con o sin extras
MLflow se puede instalar de dos formas principales desde pip o conda, según quieras una instalación mínima o una más completa:
- Instalación con extras: se incluye MLflow junto con integraciones para bibliotecas y proveedores muy comunes (scikit-learn, Azure, AWS, etc.), lo que evita tener que ir instalando paquetes adicionales poco a poco.
- Instalación básica: solo instala mlflow “pelado” y tú vas añadiendo a mano las dependencias que necesites (frameworks de ML, conectores cloud, etc.).
Si estás montando un entorno de pruebas o un entorno compartido para el equipo, suele compensar instalar MLflow con extras para no perder tiempo luego con dependencias que casi seguro vas a usar.
Configurar el firewall y puertos de acceso
Para poder ver la UI web de MLflow y exponer modelos como endpoints HTTP, necesitas abrir los puertos adecuados en el firewall de tu infraestructura. En un despliegue de ejemplo en GCP, podrías crear una regla de firewall con algo como:
- Destino por etiquetas (por ejemplo, la etiqueta de red de la VM, tipo mlflow).
- Origen: rango de IPs que tendrán acceso; para pruebas rápidas se suele usar 0.0.0.0/0, aunque en producción es mejor restringirlo.
- Puertos TCP abiertos: por ejemplo, 8080 para la UI y otros como 8081 o 1234 para modelos desplegados.
Con la regla creada, puedes lanzar el servidor de MLflow en la VM y acceder desde tu navegador con la IP externa de la máquina y el puerto asignado, algo así como XX.XXX.XXX.XXX:8080, donde verás la interfaz de tracking.
Conexión de MLflow a una base de datos relacional
Para dejar atrás el backend de ficheros locales y tener un entorno robusto, es fundamental configurar una base de datos relacional como backend de tracking. Esto permite que distintos usuarios y máquinas escriban y lean de la misma fuente de verdad.
Un patrón muy habitual es usar PostgreSQL instalado en la propia VM (para entornos sencillos) o una instancia gestionada externa (para escenarios de más carga o producción seria).
Crear la base de datos y el usuario de MLflow
La secuencia típica para preparar el backend en PostgreSQL consiste en:
- Instalar el servidor de PostgreSQL en la máquina (o conectarte a uno ya existente).
- Crear una nueva base de datos que usarás como almacén de metadatos de MLflow.
- Definir un usuario y contraseña específicos para MLflow y darle permisos sobre esa base de datos.
Una vez creada la base de datos, MLflow la utilizará para almacenar toda la información sobre experimentos, ejecuciones, modelos registrados y LoggedModels (la entidad introducida en MLflow 3 que eleva los modelos generados por las ejecuciones a un primer nivel dentro del ciclo de vida).
Instalar los conectores de base de datos para MLflow
Para que MLflow pueda hablar con PostgreSQL necesitas instalar el conector correspondiente, por ejemplo psycopg2 o psycopg2-binary en Python. Sin este paquete, el servidor de MLflow no podrá conectarse a la base de datos ni crear las tablas necesarias.
Con el conector instalado, la configuración se reduce a proporcionar una URI de conexión en el arranque del servidor, con un formato del estilo:
postgresql://usuario:password@host/basededatos
A partir de ahí, todas las ejecuciones, parámetros y métricas que registres quedarán centralizadas en esa base de datos, listas para ser consultadas tanto desde la UI como desde las APIs de alto y bajo nivel.
Configurar el almacenamiento de artefactos con un datalake
Además de la base de datos, MLflow necesita una ubicación donde guardar los artefactos: modelos, datasets, gráficos, logs extra, etc. Esos ficheros pueden crecer bastante, así que tiene sentido apoyarse en un sistema de almacenamiento escalable.
En entornos cloud, una opción muy cómoda es usar un bucket en Cloud Storage (GCP), S3 (AWS) o servicios equivalentes, que MLflow entiende de forma nativa mediante URIs específicas.
Creación de un bucket de Cloud Storage para MLflow
En Google Cloud, el procedimiento típico para usar un bucket como repositorio de artefactos sería:
- Ir a Cloud Storage y crear un bucket nuevo con un nombre único.
- Elegir el tipo de almacenamiento y la región según tus necesidades.
- Copiar la URI de gsutil, algo como
gs://nombre_del_bucket, que será la que usarás en la configuración de MLflow.
Esa URI se convertirá en la ruta base donde MLflow guardará todos los artefactos asociados a las ejecuciones, agrupados por experimento y run.
Dar permisos a la cuenta de servicio de la VM
Para que el servidor pueda leer y escribir en ese bucket, hay que otorgar permisos a la cuenta de servicio que usa la VM. Típicamente se hace desde la sección de IAM del proyecto:
- Localizas la cuenta de servicio de Compute Engine, con formato tipo xxxxx-compute@developer.gserviceaccount.com.
- Vas a la pestaña de permisos del bucket y añades esa cuenta de servicio como miembro.
- Le asignas un rol adecuado, por ejemplo Storage Object Admin, para permitirle crear y acceder a los artefactos.
Con esto, el servidor de MLflow, que corre dentro de la VM y usa esa cuenta de servicio, podrá interactuar sin problemas con el bucket en segundo plano.
Permisos para el servidor y para el cliente
En el lado del servidor, si la VM y el bucket están en el mismo proyecto, normalmente no hace falta nada más. En el lado del cliente (tu portátil u otra máquina externa) sí suele ser necesario configurar credenciales para poder subir artefactos directamente.
En el caso de GCP, el flujo típico es descargar un fichero JSON con las claves de la cuenta de servicio desde la consola de IAM, guardarlo en tu proyecto local y usar librerías como las de Google Cloud Storage para autenticarte antes de escribir artefactos. Los clientes que ejecuten código con MLflow usarán estas credenciales para acceder al bucket igual que lo hace el servidor.
Poner en marcha el servidor de MLflow con backend remoto
Cuando ya tienes claros los tres ingredientes (host/puerto, URI de base de datos y ruta de artefactos), solo te queda arrancar el servidor de MLflow con esos parámetros. Lo habitual es ejecutar el comando de servidor indicando explícitamente:
- El host de escucha, por ejemplo 0.0.0.0 para aceptar conexiones externas.
- El puerto de la UI, por ejemplo 8080.
- La URI de la base de datos relacional.
- La URI del almacén de artefactos, por ejemplo gs://bucket_name.
Con el servidor corriendo, si abres el navegador y apuntas a la IP pública y el puerto configurado, verás la interfaz de seguimiento de MLflow y podrás empezar a crear experimentos, lanzar runs y registrar modelos. A partir de aquí viene lo divertido: instrumentar tu código y sacarle partido al tracking.
Cómo usar MLflow Tracking para organizar tus experimentos
El módulo de Tracking es probablemente la parte más usada de MLflow, porque resuelve un problema muy real: saber exactamente qué has probado, con qué configuración y qué resultado ha dado. Sin esto, iterar sobre modelos complejos se vuelve una lotería.
La idea de fondo es sencilla: cada vez que entrenas un modelo, abres una ejecución (run), registras parámetros, métricas, artefactos y el propio modelo, y dejas todo eso centralizado en el servidor para poder compararlo más tarde de forma visual o programática.
Conceptos básicos: experimentos, ejecuciones y modelos
MLflow organiza la información de tracking alrededor de tres entidades clave que deberías tener claras desde el principio:
- Experimentos: agrupan un conjunto de ejecuciones relacionadas. Lo normal es tener un experimento por proyecto o por problema de negocio (por ejemplo, “Predicción churn clientes”).
- Ejecuciones (runs): representan una ejecución concreta de tu código, con una configuración y unos datos determinados. Cada run tiene su ID, hora de inicio, duración y estado (éxito o fallo).
- Modelos / LoggedModels: son los artefactos de modelo entrenado que se generan en las ejecuciones. Desde MLflow 3, LoggedModels los eleva como entidad de primer nivel para seguir su ciclo de vida más allá de una sola run.
Durante una ejecución, puedes registrar distintos tipos de información usando la API de Tracking, ya sea con rutas automáticas (autolog) o de forma manual, lo que te da un control muy fino sobre lo que quieres guardar.
Conectar el cliente al servidor de MLflow
Antes de registrar nada, tu script o notebook tiene que apuntar al servidor de tracking correcto. Esto se hace configurando la tracking URI en tu código, por ejemplo con Python:
mlflow.set_tracking_uri("http://IP_DEL_SERVIDOR:8080")
A partir de ese momento, todo lo que registres irá a ese servidor, salvo que cambies la URI. Además, puedes indicar explícitamente en qué experimento se deben registrar las ejecuciones mediante mlflow.set_experiment o funciones similares.
Crear o seleccionar un experimento
Para que tus runs no acaben en un experimento genérico o en uno del cuaderno por defecto (en plataformas como Databricks), es buena idea crear un experimento propio o reutilizar uno existente. Puedes hacerlo desde la UI o desde código.
En la API de Python, existe un comando que, dado un nombre de experimento, lo crea si no existe o lo selecciona como activo si ya está creado, lo que resulta muy cómodo para automatizar tus notebooks o scripts. Aunque MLflow tiene también un método create_experiment(), la aproximación que combina creación y selección suele dar menos guerra.
Iniciar y cerrar ejecuciones correctamente
Para que MLflow sepa a qué run asociar los parámetros y métricas, debes abrir una ejecución con start_run. Lo más limpio es utilizarlo dentro de un context manager de Python:
with mlflow.start_run(run_name="nombre_run"):
# aquí entrenas el modelo y haces los logs
La ventaja de este patrón es que MLflow cierra automáticamente la ejecución al salir del bloque, incluso si hay errores. Alternativamente, puedes controlar el ciclo de vida manualmente con start_run() y end_run(), pero es más fácil olvidarse de cerrar runs así.
Qué se puede registrar en una ejecución
Dentro de un run puedes loguear varios tipos de información que MLflow muestra luego ordenada en la interfaz y que también puedes consultar por API:
- Parámetros: suelen ser hiperparámetros o valores de configuración que tú estableces (número de árboles, tipo de solver, tamaño de lote, etc.). Se registran con
mlflow.log_paramolog_params. - Métricas: son resultados numéricos del entrenamiento o evaluación (accuracy, AUC, RMSE, pérdida, etc.). Se registran con
mlflow.log_metric, pudiendo actualizarse varias veces para una misma métrica a lo largo del tiempo. - Artefactos: cualquier fichero que quieras asociar al run: conjuntos de datos, gráficos, reportes, cuadernos, etc. Se suben con
mlflow.log_artifactolog_artifacts. - Modelos: el propio modelo entrenado, que se registra usando las APIs específicas de cada framework, como
mlflow.sklearn.log_model,mlflow.xgboost.log_model, etc.
Una funcionalidad muy potente es el autolog: para ciertos frameworks (scikit-learn, TensorFlow, Keras, XGBoost, LightGBM, PyTorch, Fastai, Statsmodels, Spark, H2O, Transformers, etc.) MLflow puede registrar automáticamente buena parte de los parámetros y métricas sin que tú tengas que llamarlos uno por uno.
Ejemplos prácticos de tracking con MLflow
Para ver el tracking en acción, puedes usar datasets clásicos como Iris o Titanic y entrenar modelos sencillos con scikit-learn. La clave no es tanto la complejidad del modelo como la disciplina de registrar lo que haces.
Por ejemplo, puedes montar un flujo donde imputas valores faltantes (media para la edad, moda para variables categóricas), eliminas columnas irrelevantes, divides en train/test y entrenas un modelo de Regresión Logística o Random Forest con validación cruzada, guardando cada combinación de hiperparámetros como una ejecución distinta.
Registro de varios runs con distintos hiperparámetros
Imagina que quieres probar varias configuraciones de un modelo de clasificación: cambias el solver, el valor de C y el número máximo de iteraciones en una Regresión Logística. Para cada combinación, haces lo siguiente dentro de un run:
- Registras los hiperparámetros con log_param.
- Calculas las métricas de evaluación (por ejemplo, accuracy en el conjunto de test) y las guardas con log_metric.
- Serializas el modelo a un fichero
.pkly lo subes como artefacto o, mejor aún, usas la API de modelo de MLflow para loguearlo.
En la UI verás una tabla de ejecuciones donde cada fila es un run, con sus parámetros, métricas y un indicador de si la ejecución terminó bien o con errores. También podrás asignar nombres más descriptivos a los runs mediante el parámetro run_name, algo muy recomendable para no perderte.
Navegar y comparar ejecuciones desde la interfaz
Al hacer clic en cualquiera de las ejecuciones, accedes a una vista detallada donde MLflow muestra:
- Los parámetros registrados y su valor.
- Las métricas, incluyendo su evolución en el tiempo si has logueado varias actualizaciones.
- Los artefactos adjuntos, como el modelo en formato serializado, gráficos o conjuntos de datos.
Desde la vista de experimento puedes seleccionar varias ejecuciones y compararlas, filtrarlas por rangos de métricas o valores de parámetros y construir gráficas que te ayuden a entender qué combinaciones dan mejor rendimiento.
Acceso programático a las ejecuciones
Más allá de la UI, MLflow expone una API de cliente en Python, Java, R y REST que te permite consultar los datos de las runs de manera programática. Por ejemplo, puedes usar:
- search_runs para obtener un DataFrame (Pandas o Spark) con las ejecuciones de un experimento, filtrando por métricas o etiquetas.
- get_run para recuperar toda la información asociada a un run concreto.
- list_run_infos para listar los identificadores de ejecución y metadatos básicos.
Eso sí, la estructura de estos objetos puede ser un poco farragosa, así que mucha gente opta por convertirlos primero a diccionarios o DataFrames limpios, y a partir de ahí construir paneles y análisis personalizados sobre la evolución de las métricas en el tiempo o el comportamiento de diferentes usuarios.
Seguimiento con MLflow en plataformas como Azure Databricks
Si trabajas en entornos gestionados tipo Azure Databricks, buena parte de la infraestructura ya viene resuelta: MLflow está preinstalado en los clústeres de Runtime ML y el área de trabajo incorpora un servidor de tracking hospedado, sin que tengas que montar tú uno.
En este contexto, hay algunos detalles que cambian, pero la filosofía es la misma: gestionar experimentos, ejecuciones y modelos con la API estándar de MLflow, apoyándote en utilidades extra de la plataforma.
Tracking URI y experimentos en Databricks
Por defecto, los notebooks de Databricks registran las ejecuciones en el experimento asociado al propio cuaderno, sin que tengas que indicar nada. Aun así, puedes cambiar esto configurando:
- La tracking URI, por ejemplo para apuntar a otro workspace remoto de Databricks.
- El nombre del experimento en el que quieres registrar las runs, mediante
mlflow.set_experiment().
Si no defines un experimento activo, las ejecuciones irán al experimento por defecto del cuaderno; para proyectos con más orden, suele ser preferible centralizar las runs en experimentos de área de trabajo que agrupen varios notebooks relacionados.
Registro automático y APIs en MLflow 2.x y 3
Databricks mantiene cuadernos de ejemplo donde se enseña a usar el registro automático (autolog) con scikit-learn y otros frameworks, tanto para MLflow 2.x como para MLflow 3, que introduce funcionalidades avanzadas como los LoggedModels de nueva generación.
También hay ejemplos centrados en el uso de la API de logging manual (Python, REST, R y Java), para cuando necesitas más control sobre qué se registra, adjuntar trazas, CSVs, gráficos personalizados u otros artefactos que el autolog no capta de serie.
Análisis de ejecuciones con DataFrames
En Databricks resulta especialmente cómodo construir paneles porque tienes a mano tanto Pandas como Spark. Dos caminos habituales para analizar las ejecuciones son:
- Usar mlflow.search_runs desde el cliente de Python para obtener un DataFrame de Pandas con las runs de uno o varios experimentos.
- Usar el origen de datos de experimento de MLflow para leer las ejecuciones como un DataFrame de Spark, ideal si tienes muchísimas runs o quieres hacer agregaciones complejas.
Con estas herramientas puedes construir dashboards que muestren, por ejemplo, la evolución del rendimiento del modelo a lo largo del tiempo, el número de runs iniciadas por cada usuario o el volumen total de ejecuciones por día.
Sobre la variabilidad en resultados de entrenamiento
Un tema importante cuando analizas resultados con MLflow es entender que muchos algoritmos tienen componentes aleatorios: inicializaciones, muestreos, particionados… Incluso fijando semillas, pequeñas variaciones de orden de datos o de particionado distribuido pueden hacer que las métricas no sean idénticas de una run a otra.
En flujos con Spark y datos distribuidos, esta variación puede aumentar, por eso se recomienda, cuando tiene sentido, usar funciones como repartition y sortWithinPartitions para controlar mejor el orden y la distribución de los datos antes del entrenamiento, sin obsesionarse con obtener números idénticos al milímetro.
Workflows avanzados y ejemplos de uso de MLflow
Más allá del tracking básico, MLflow ofrece ejemplos y tutoriales para workflows más complejos que cubren desde la orquestación de varios pasos hasta el aseguramiento de la cadena de suministro de código y la integración con frameworks de deep learning o LLMs.
Estos recursos se organizan en bloques temáticos que te ayudan a centrarte en lo que más te interesa: optimización de hiperparámetros, reproducibilidad, seguridad, integración con frameworks concretos o extensiones personalizadas mediante plugins.
Workflows principales y uso de la API y REST
Si tu prioridad es exprimir tus modelos con diferentes configuraciones, el ejemplo de búsqueda de hiperparámetros te muestra cómo lanzar búsquedas en rejilla o aleatorias, integrando herramientas como Optuna y registrando todos los resultados para luego compararlos en la UI.
Cuando tu pipeline es más complejo (preprocesado, entrenamiento, postprocesado, evaluación…), hay guías que explican cómo orquestar flujos de varios pasos, de forma que cada etapa registre sus propios artefactos y métricas, pero todo quede asociado al mismo experimento y a ejecuciones relacionadas.
Si prefieres hablarle directamente al servidor sin SDKs, también hay ejemplos de cómo usar la API REST de MLflow con curl o Python, enviando peticiones para crear runs, registrar métricas o gestionar modelos sin depender de un lenguaje en concreto.
Reproducibilidad y seguridad de la cadena de suministro
La reproducibilidad es un tema serio en ML. MLflow se integra bien con enfoques donde empaquetas todo tu entrenamiento en un contenedor Docker que incluye código, dependencias y llamadas a tracking. Hay tutoriales que enseñan a construir la imagen, subirla a un registry y ejecutarla de forma controlada, manteniendo un entorno constante.
En lo que respecta a la seguridad, hay ejemplos de protección frente a manipulación de paquetes Python, firmando wheels, verificando checksums e integrando estos pasos en tu pipeline de CI/CD. Así te aseguras de que el código que se registra en MLflow es realmente el que se ejecuta luego y reduces la clásica excusa del “en mi máquina funciona”.
Instrumentar código de entrenamiento con distintos frameworks
MLflow tiene integraciones con un abanico muy amplio de librerías, tanto de machine learning clásico como deep learning, series temporales, NLP, estadística y workflows de LLM. Algunos ejemplos destacados:
- Modelos clásicos: scikit-learn, XGBoost, LightGBM, H2O, RAPIDS y otros.
- Deep learning: Keras, TensorFlow, PyTorch, con soporte para registrar curvas de entrenamiento, checkpoints y métricas de GPU.
- Series temporales: Prophet, pmdarima, con logging de componentes estacionales y métricas de forecast.
- Estadísticos y R: integración con Statsmodels y librerías como glmnet en R, registrando coeficientes, resúmenes y gráficos de diagnóstico.
- NLP y transformers: spaCy y Transformers de Hugging Face, pudiendo loguear pesos de modelos, ejemplos de textos generados y puntuaciones de evaluación.
- Explainability: integración con SHAP para guardar valores de atribución de características y visualizarlos en la UI.
- Workflows de LLM: guías con LangChain y OpenAI para instrumentar prompts, respuestas, historiales de conversación y métricas de calidad.
En todos estos casos, la filosofía es similar: minimizar el boilerplate de logging aprovechando las APIs específicas de cada framework, pero manteniendo un modelo coherente de parámetros, métricas, artefactos y modelos registrados.
Extender MLflow con plugins propios
Si tu caso de uso se sale de lo estándar, MLflow también permite desarrollar plugins personalizados para añadir nuevos sabores de modelo, stores de artefactos o incluso pestañas adicionales en la UI. Los tutoriales de plugins explican cómo:
- Definir la lógica del plugin (por ejemplo, un nuevo tipo de modelo o integración con un sistema de ficheros corporativo).
- Empaquetarlo e instalarlo en tu entorno de desarrollo y en producción.
- Probarlo y depurarlo localmente antes de desplegarlo a otros usuarios.
De esta manera, puedes adaptar MLflow a necesidades muy específicas de tu organización sin tener que bifurcar el proyecto original, manteniéndote alineado con las versiones oficiales.
Con todo lo visto, MLflow se convierte en una especie de “centro de mando” para tus proyectos de machine learning y deep learning: te ayuda a mantener controlados tus experimentos, te permite comparar variantes de forma ordenada, facilita reproducir entrenamientos, favorece la trazabilidad del código y simplifica el despliegue de modelos como servicios o endpoints REST, tanto en servidores propios como en nubes públicas, algo que redunda directamente en ciclos de desarrollo más rápidos, menos caos y modelos en producción mucho más fáciles de mantener.
Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.