- Heavy/Expert para precisión y tareas complejas; Fast/Grok‑4‑Fast para latencia mínima; Auto equilibra según la consulta.
- Acceso web en tiempo real y uso nativo de herramientas diferencian a Grok frente a modelos sin estas funciones activas.
- Grok‑4‑Fast aporta 2M tokens de contexto, tool‑use RL y menos tokens de “pensamiento”, bajando coste.
- Planes y despliegue: Heavy ~$300/mes, estándar ~$30/mes; Grok4Fast en pruebas para suscriptores.
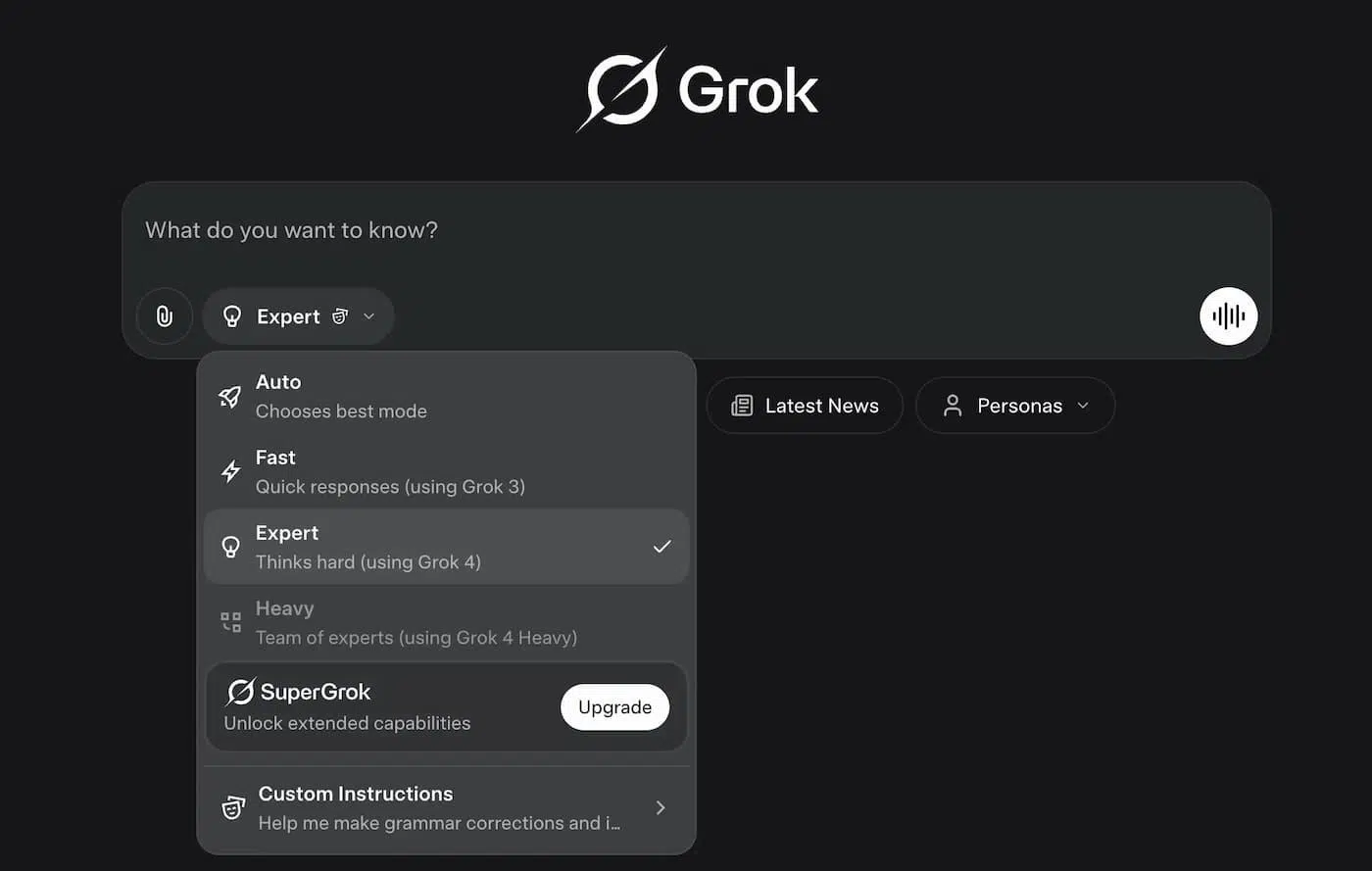
Si alguna vez te has preguntado cómo sacar partido a una IA que consulta Internet al vuelo y razona con más de un agente a la vez, aquí tienes una guía completa para entender para qué sirven los modos Heavy, Expert, Fast y Auto de Grok. La clave está en elegir el modo adecuado según si priorizas velocidad, profundidad de análisis o equilibrio automático.
Grok 4, creado por xAI (la empresa de Elon Musk e integrada con la plataforma X), llega con promesas potentes: navegación web en tiempo real, uso de herramientas nativo y una versión “Heavy” con arquitectura multiagente. Con precios diferenciados y funciones que no suelen estar activadas por defecto en otros modelos, conviene saber en qué destaca cada modo y cuándo usarlo.
Qué modos ofrece Grok y en qué situaciones conviene cada uno
La familia Grok se ha diversificado para cubrir necesidades muy distintas, desde respuestas inmediatas hasta razonamientos complejos de varios pasos. Heavy, Expert, Fast y Auto no son etiquetas publicitarias, sino modos de trabajo con implicaciones reales en coste, latencia y calidad.
- Modo Heavy: pensado para trabajos exigentes donde intervienen múltiples pasos y especialidades simultáneamente. En Grok 4 Heavy, varios agentes internos cooperan “entre bambalinas” (un agente planifica, otro verifica, otro redacta), ideal para ingeniería, desarrollo de software, investigación técnica y análisis extensos. Si necesitas exactitud y cadenas de razonamiento profundas, este es el perfil premium.
- Modo Expert: orientado a respuestas precisas y analíticas sin llegar al despliegue completo del esquema multiagente de Heavy. En preguntas que requieren calma, rigor y comprobaciones, Expert tarda un poco más, pero suele afinar mejor el resultado que un modo de latencia bajísima. Para consultas complejas, informes técnicos o matemáticas no triviales, Expert suele marcar la diferencia.
- Modo Fast: juego rápido, latencia mínima. Este modo está optimizado para “preguntas express”, síntesis rápidas, búsquedas puntuales y tareas cotidianas. Cuando te importa más recibir la respuesta ya que exprimir cada matiz, Fast brilla por su inmediatez.
- Modo Auto: selector inteligente que decide por ti qué estrategia conviene según la consulta y los límites de coste/tiempo. En la práctica, elige un enfoque ligero cuando la tarea es simple y activa razonamientos más profundos si detecta complejidad. Para quien no quiera andar cambiando de modo a mano, Auto busca el equilibrio entre rapidez y profundidad.

Grok 4 vs Grok 4 Heavy: diferencias que se notan en el día a día
Grok 4 “estándar” es un modelo muy capaz y versátil, pero Grok 4 Heavy sube el listón al coordinar varios agentes internos especializados. Este esquema multiagente permite partir un problema complejo en subtareas y resolverlas de forma colaborativa.
Ese trabajo en equipo interno se traduce en mejores resultados para código, análisis técnicos, investigación y tareas con múltiples dependencias. Si trabajas con pipelines largos (p. ej., planificar → buscar → verificar → sintetizar), Heavy aporta más seguridad y coherencia.
Ambas variantes usan herramientas en tiempo real (calculadoras, navegación web, extracción de contenidos, etc.), con un foco claro en respuestas actualizadas. En Grok 4, la web no es un adorno; se consulta en vivo para contrastar hechos y aportar contexto reciente.
Acceso web en tiempo real y uso de herramientas: por qué importan
La mayoría de LLMs dependen sobre todo de lo que “recuerdan”, entrenados con datos que se quedan viejos. Grok apuesta por consultar la red mientras responde. Esto es oro si necesitas datos al día, referencias recientes o confirmar algo que cambió esta semana.
Además, el uso de herramientas está integrado de forma nativa: ejecutar código, buscar, raspar una página… todo dentro del flujo de respuesta. Para ti, significa menos copiar/pegar entre apps y más autonomía del asistente para traer lo que hace falta.
Grok‑4‑Fast: velocidad, ventana de 2M tokens y menos “pensamiento” por tarea
xAI ha puesto a prueba un modo nuevo llamado Grok4Fast (disponible para algunos suscriptores) que acelera la respuesta, especialmente en matemáticas o preguntas complejas donde el arranque suele ser la parte lenta. La sensación es que contesta casi al instante, lo cual se agradece cuando vas con prisa.
¿Qué aporta frente a modos rápidos anteriores? Grok‑4‑Fast mezcla en un mismo espacio de pesos comportamientos de razonamiento y no-razonamiento; según el “system prompt”, se activa uno u otro. Esto le permite cambiar de marcha sobre la marcha, del turbo a la precisión, sin cambiar de modelo.
Tres puntos prácticos saltan a la vista: 1) contexto extremo de hasta 2 millones de tokens (cabida para documentación enorme), 2) entrenamiento para decidir cuándo usar herramientas (tool-use RL) y 3) menos tokens de “pensamiento” (~40% menos para igualar la precisión de Grok‑4), lo que baja costes en cargas de alto volumen. Si gestionas agentes autónomos o asistentes con memoria larga, aquí hay ahorro y agilidad.
En pruebas de la comunidad, se nota el salto en latencia respecto a Fast actual: casi sin espera y experiencia muy fluida. Eso sí, queda por ver si su capacidad iguala siempre a Expert cuando el nivel de matiz es crítico.
Para activarlo (si te sale la opción), entra en la versión web de Grok, toca tu avatar → Configuración → Suscripción de Grok y activa “Modelo preliminar temprano”; ahí podrás elegir Grok4Fast. Por ahora, esta función no está disponible para cuentas gratuitas; la ven los suscriptores.
Cuándo elegir cada modo: escenarios claros para no liarte
- Preguntas rápidas y tareas cotidianas: ve a Fast o Grok‑4‑Fast si prima la inmediatez (resúmenes, aclaraciones, consultas puntuales).
- Problemas técnicos con varios pasos: elige Heavy para dividir y vencer, con agentes especializados que coordinan el trabajo.
- Análisis precisos o sensibles: Expert compensa con rigor y suele “clavar” la explicación, aunque tarde un pelín más.
- No quieres decidir cada vez: Auto gestiona el equilibrio y ajusta profundidad y coste según el tipo de consulta.
Un truco sencillo: si la consulta afecta a una decisión profesional o económica relevante, prueba Expert o Heavy; si es para salir del paso, Fast/Grok‑4‑Fast te quita esperas. Auto es tu copiloto si prefieres olvidarte del interruptor.
Rendimiento en benchmarks y casos de uso reales
xAI reporta resultados fuertes en evaluaciones públicas como AIME‑2025 (92.0% pass@1) y HMMT‑2025 (93.3% pass@1), así como buen posicionamiento en competiciones abiertas (LMArena). Estos números orientan, pero lo determinante es cómo rinde en tu flujo real con datos cambiantes.
¿Dónde brilla en la práctica? En asistentes de investigación y búsqueda, agentes conversacionales avanzados (combinar respuesta veloz y cadenas largas de razonamiento), programación con mejor coste/precisión y aplicaciones multilingües con mejoras reportadas también en chino y en benchmarks de búsqueda. Cuando el contexto es gigante y necesitas que el modelo “se organice” solo, Grok‑4‑Fast suma puntos.
Comparativa con GPT‑4.5, Gemini 1.5 Pro y Claude 3
Si valoras navegación web al minuto y colaboración interna de agentes, Grok 4 y Heavy sacan ventaja frente a modelos que no traen estas funciones activas por defecto; en comparación con otras opciones puedes ver recomendaciones en la mejor IA para cada tarea. Además, Grok integra señales de X (antes Twitter), incluyendo referencias de publicaciones de Elon Musk cuando es relevante.
Ahora bien, GPT‑4.5 y Gemini 1.5 Pro siguen dominando muchos benchmarks y ofrecen ecosistemas de plugins y políticas de seguridad muy amplios; Claude 3 es otra alternativa consolidada. Si necesitas traducción súper especializada o garantías de seguridad a nivel empresarial, OpenAI y Google siguen teniendo terreno ganado.
Traducción y métricas lingüísticas: qué tal se comporta Grok 4
En marketing digital al español, se ha medido alrededor de un 95% de acierto en terminología técnica y un 90% de corrección gramatical, con un 85% de retención contextual del original. Hay margen para pulir frases y adaptar regionalismos (p. ej., cambiar “comercializadores” por “expertos en marketing” mejora claridad).
Con corrección humana ligera se cubren el ~5% de lagunas terminológicas y el ~10% de matices gramaticales, elevando la eficacia global a cerca del 93%. Para uso profesional es sólido, y con una vuelta de localización queda fino.
| Modelo | Fluidez (TFFT) | Exactitud | Retención de contexto | Precisión gramatical |
|---|---|---|---|---|
| Grok 4 | 8,9/10 | 92% | Excelente | 94% |
| GPT‑4.5 | 9,2/10 | 94% | Muy bien | 96% |
| Gemini 1.5 Pro | 9,0/10 | 93% | Excelente | 95% |
| Claude 3 | 8,7/10 | 91% | Bien | 93% |
Si tu prioridad es traducción con terminología afinada al máximo, aún puede merecer la pena una capa humana o considerar modelos punteros según el dominio. Para la mayoría de flujos, Grok 4 cumple con solvencia y gana puntos si necesitas contexto en vivo.
Precios, planes y coste por token
El plan Grok 4 Heavy ronda los 300 dólares/mes y da acceso anticipado a lo último; está orientado a perfiles avanzados que exprimen la arquitectura multiagente. El Grok 4 estándar es más asequible, unos 30 dólares/mes, y hay un Grok 3 gratuito para usuarios de X con funciones recortadas.
En uso por API, xAI publica tramos por token; por ejemplo, unos 0,20$ por cada millón de tokens de entrada en contextos hasta ~128k, con otras franjas para salida y contextos mayores. Con Grok‑4‑Fast, la reducción de tokens de “pensamiento” ayuda a bajar el coste por operación en escenarios con mucho volumen.
La infraestructura que lo hace posible: Colossus y consumo energético
Debajo del capó está Colossus, una supercomputadora en Memphis (Tennessee) con más de 200.000 GPUs. Esta potencia bruta permite consultas web en tiempo real y manejar miles de sesiones simultáneas sin despeinarse.
Ese músculo conlleva un peaje: la discusión sobre el consumo eléctrico y el impacto medioambiental de los LLM sigue abierta. Si tu empresa tiene objetivos de sostenibilidad, conviene monitorizar el uso y compensar donde proceda.
Lanzamiento, integración con X y guiños de Musk
El lanzamiento de Grok 4 se produjo en julio de 2025 y Elon Musk lo ha descrito como “la IA más inteligente del mundo”. La integración con X no es superficial: el modelo puede incorporar señales y referencias de publicaciones recientes (incluidas de Musk) cuando aportan contexto.
Esto convierte a Grok en una propuesta atractiva para seguir noticias de última hora y temas que “arden” en la red social. Si te mueves en contenidos pegados a actualidad, esta conexión es un plus.
Cómo activarlo y disponibilidad del modo Grok4Fast
Hoy por hoy, Grok4Fast está en pruebas para ciertos suscriptores. Si lo tienes habilitado, encontrarás la opción en el avatar de la web → Configuración → Suscripción → activar “Modelo preliminar temprano” y seleccionar Grok4Fast. Los usuarios gratuitos no lo verán de momento; queda por saber cuándo llegará a todo el mundo.
En las primeras pruebas compartidas por internautas, su desempeño al responder preguntas complejas es notable por la latencia casi nula frente al modo rápido tradicional. Para tareas simples donde pesa la inmediatez, el recorte de espera se nota mucho.
Usos profesionales: desde mercado y soporte hasta código y contenidos
Con búsqueda en vivo, multiagente y herramientas, Grok es útil para monitorizar tendencias, soporte técnico, investigación académica y generación de contenidos basada en noticias de última hora. En desarrollo, ayuda con bibliotecas y frameworks actuales, siempre con el radar en cambios recientes.
Si te va lo de automatizar: Grok‑4‑Fast permite agentes que alternan respuesta instantánea y razonamiento largo sin saltos de modelo. Así, el mismo asistente puede pasar de un “sí/no” a una estrategia con varios pasos si el caso lo exige.
Integración empresarial y recomendaciones técnicas
- Aprovecha la ventana larga con cabeza: sube solo lo necesario (documentos, políticas, historiales) y trocéalo; no llenes 2M tokens “porque sí”.
- Orquestación con herramientas: deja que el modelo decida cuándo navegar o ejecutar código, pero monitoriza llamadas para controlar coste y latencia.
- Coste real: calcula según tamaño medio de entrada, salida y proporción de tokens de “pensamiento”; Grok‑4‑Fast ayuda a reducirlos.
- Compatibilidad: encaja en pipelines con chatbots, voicebots y microservicios; define bien eventos y permisos al invocar bases de datos o APIs.
Si buscas acompañamiento, firmas como Aimoova ofrecen diseño y despliegue de agentes a medida, integración en atención al cliente multicanal, automatizaciones combinando IA y reglas, y formación en prompts, gobernanza y métricas. Su enfoque va a minimizar tokens y latencia sin pedirte un equipo técnico gigante.
¿Merece la pena pagar el plan alto?
Si tu día a día implica redacción técnica, ayuda de ingeniería o acceso a datos en tiempo real, el nivel más alto puede ser inversión, no gasto. Para la mayoría, el plan estándar es suficiente; y si solo quieres curiosear, Grok 3 gratuito en X funciona como toma de contacto.
Un consejo práctico: empieza por el escalón inferior y evalúa con un piloto corto (soporte, búsqueda interna o asistencia de código). Medir impacto real durante unas semanas te dirá si Heavy compensa los 300 dólares/mes.
Hoja de ruta: multimodal, proyecto “Eve” e incluso coches
La siguiente tanda de funciones apunta a multimodalidad: imágenes, vídeo y voz en la misma experiencia. Además, “Eve” promete interacciones más naturales, y no se descarta integración en vehículos de Tesla para navegación y búsquedas por voz.
Para quien trabaja con traducciones, hay plataformas que centralizan los LLM punteros —Grok, Claude, ChatGPT o DeepSeek— en un único sitio (por ejemplo, MachineTranslation.com) para flujos más rápidos y consistentes. Es una manera de obtener respuestas multifuente sin saltar entre cuentas.

Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.