- GPT-OSS permite usar modelos de OpenAI en local en Windows, sin depender de la nube y con privacidad total.
- El modelo gpt-oss-20b es el más adecuado para PC domésticos, requiriendo al menos 16 GB de memoria y una GPU moderna para un buen rendimiento.
- Ollama y LM Studio simplifican la instalación y el uso de GPT-OSS ofreciendo descargas guiadas y chats locales al estilo ChatGPT.
- Una vez instalado, GPT-OSS sirve para redacción, estudio, programación y análisis de documentos directamente desde tu ordenador.

Si llevas tiempo usando ChatGPT u otras IAs en la nube, seguramente te habrás planteado alguna vez qué pasaría si pudieras tener algo parecido instalado directamente en tu PC con Windows, sin cuotas mensuales, sin depender de servidores externos y sin ceder ni una sola conversación. Eso es justo lo que permiten los nuevos modelos abiertos de OpenAI: gpt-oss-20b y gpt-oss-120b.
En las siguientes líneas vamos a ver con todo lujo de detalles cómo instalar GPT-OSS en Windows, qué necesitas a nivel de hardware, qué diferencias hay entre las dos variantes del modelo, y cómo usarlo tanto con Ollama como con LM Studio. Además, te contaré para qué sirve en el día a día, qué puedes esperar del rendimiento en un PC normalito y qué peajes vas a pagar si tu equipo va justo de recursos.
Qué es GPT-OSS y qué puede hacer por ti
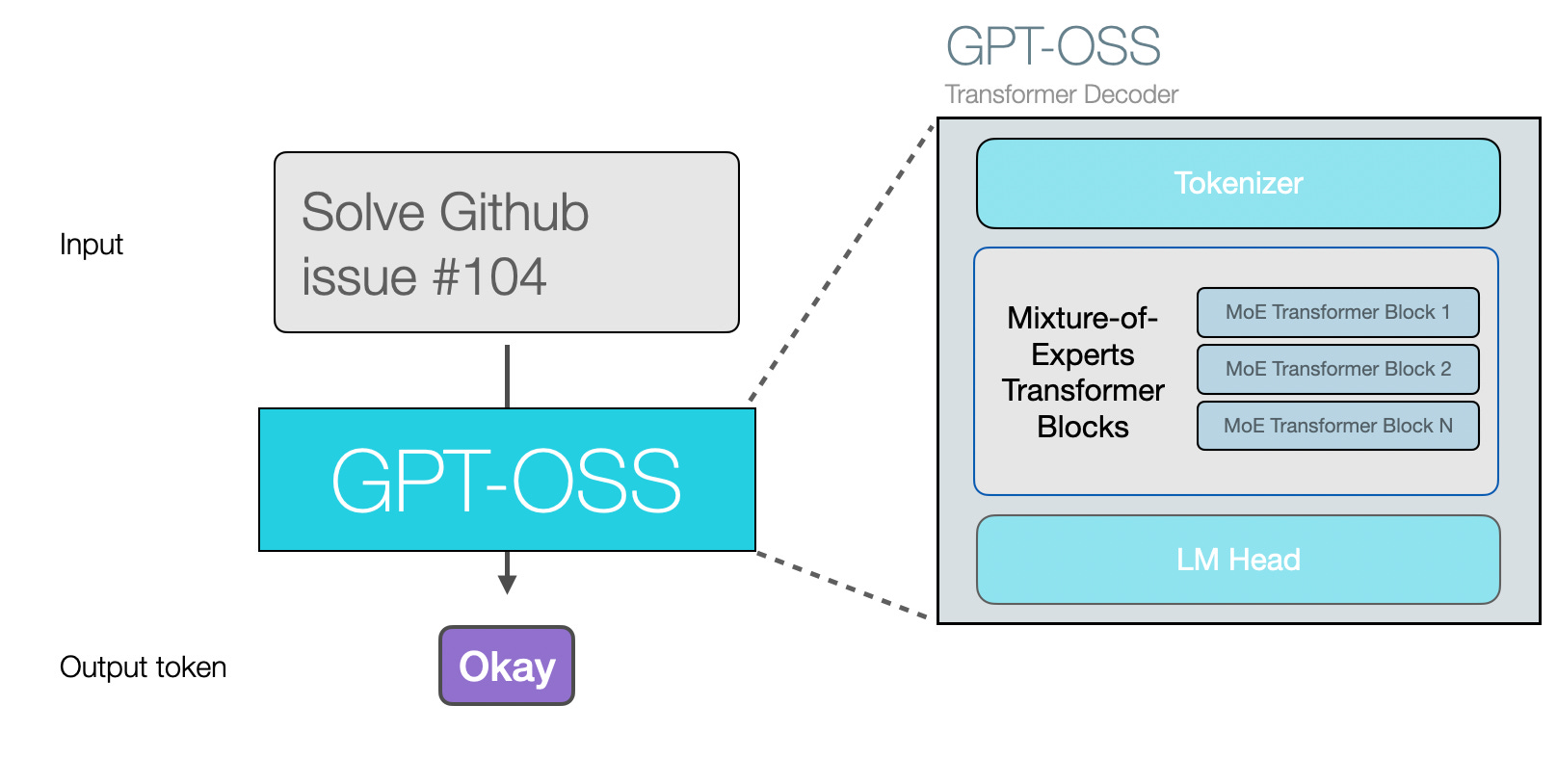
GPT-OSS es la familia de modelos open source de OpenAI, pensada para que cualquiera pueda descargarlos y ejecutarlos en sus propios dispositivos: ordenadores, estaciones de trabajo e incluso algunos móviles potentes. El nombre viene de Generative Pretrained Transformer – Open Source Series, es decir, una serie de modelos generativos de texto de código abierto bajo licencia Apache 2.0.
Con GPT-OSS puedes realizar prácticamente las mismas tareas que con un asistente en la nube: generar textos de todo tipo (emails, posts para redes sociales, guiones, historias, poemas…), resumir documentos largos, reescribir párrafos, mejorar la redacción o adaptar el tono a un estilo más formal o más cercano.
También es capaz de encargarse de tareas más técnicas: explicar código, detectar errores de programación, sugerir mejores enfoques en distintos lenguajes, ayudarte a aprender a programar o darte pistas para resolver problemas lógicos y matemáticos. No tiene acceso directo a Internet, pero maneja muy bien el razonamiento paso a paso y puede guiarte en muchos procesos complejos.
En el terreno de la productividad personal, GPT-OSS funciona muy bien para organizar proyectos, hacer lluvia de ideas, elaborar esquemas de trabajos, generar listas de tareas, responder dudas sobre temáticas muy diversas o ayudarte a redactar informes y trabajos académicos. Si eres estudiante, freelance, creador de contenido o desarrollador, puedes sacarle muchísimo partido funcionando en local.
Ventajas y desventajas de usar GPT-OSS de forma local en Windows
La gran diferencia de GPT-OSS respecto a modelos como ChatGPT, Gemini o Claude es que no dependes de un servidor remoto. El modelo se ejecuta en tu propio PC con Windows, lo que trae unas ventajas muy claras, pero también algún inconveniente que conviene conocer antes de lanzarte a instalarlo.
La primera gran ventaja es la privacidad absoluta de tus datos. Cada conversación, archivo o pregunta que pasas por el modelo se queda en tu ordenador, sin que ninguna empresa pueda usarlo para entrenar más modelos, perfilarte o mostrarte publicidad. Si necesitas tratar documentos sensibles, contratos, datos internos de tu empresa o información personal, esto es oro puro.
Muy ligada a esto está la seguridad: al no enviarse nada a la nube, no hay tráfico de información hacia terceros, por lo que reduces de golpe la superficie de ataque relacionada con servicios externos. Evidentemente sigues teniendo que cuidar la seguridad de tu propio PC, pero al menos eliminas el factor del proveedor cloud.
Otro punto a favor es la libertad económica. Los servicios comerciales suelen funcionar con suscripciones mensuales (ChatGPT Plus, Gemini Advanced, etc.) o con pago por uso vía API. Con GPT-OSS, el modelo es totalmente gratuito: lo descargas una vez, lo instalas y listo, nada de cuotas recurrentes ni límites artificiales de mensajes.
Además, al ser un modelo abierto tienes un grado de control y personalización que los servicios cerrados no ofrecen. Puedes ajustar parámetros, cambiar el comportamiento por defecto, integrarlo en tus propias aplicaciones, automatizar tareas con scripts o conectarlo a herramientas locales mediante APIs que se ejecutan en tu máquina.
La parte menos amable llega por el lado del hardware y la complejidad. Ejecutar un modelo de este tipo es una tarea intensa para el equipo, y la velocidad de respuesta depende mucho de tu CPU, tu GPU y tu memoria. En un ordenador potente, las respuestas pueden fluir de manera bastante ágil; en un portátil justito notarás que se lo toma con calma.
También tienes que asumir cierta carga técnica: eres tú quien instala, configura, actualiza y asegura todo el sistema. No es excesivamente complicado gracias a herramientas como Ollama o LM Studio, pero no deja de ser un punto más avanzado que abrir una web y empezar a escribir.
Diferencias entre gpt-oss-20b y gpt-oss-120b
Dentro de la familia GPT-OSS vas a encontrarte principalmente con dos tamaños de modelo: gpt-oss-20b y gpt-oss-120b. Aunque el nombre se parezca, no juegan en la misma liga ni en capacidades ni, sobre todo, en requisitos de hardware.
gpt-oss-120b es el modelo grande, pensado para centros de datos, estaciones de trabajo con varias GPUs o máquinas de gama muy alta. Su rendimiento está cercano a modelos comerciales como OpenAI o4-mini, pero a cambio exige al menos 60 GB de memoria VRAM o unificada. Esto deja fuera prácticamente a todos los ordenadores domésticos.
En el extremo más accesible tenemos gpt-oss-20b, el modelo mediano, que se acerca en capacidades a modelos como o3-mini. Este sí está diseñado para equipos de consumo: necesita 16 GB de VRAM o memoria unificada para funcionar de forma razonable y se puede ejecutar tanto en sobremesas gaming como en muchos portátiles con GPU dedicada o en algunos Mac con Apple Silicon.
En la práctica, si tu intención es instalar GPT-OSS en un PC con Windows en casa o en la oficina, el candidato realista es gpt-oss-20b. El 120b queda reservado para setups muy específicos con varias tarjetas gráficas o estaciones profesionales.
Requisitos mínimos recomendados para instalar GPT-OSS en Windows
Antes de empezar con descargas e instalaciones conviene revisar qué pide GPT-OSS para funcionar de manera decente en Windows. Lo bueno es que, para el modelo 20b, los requisitos no son descabellados para un PC moderno, aunque sí un poco exigentes para portátiles antiguos.
En cuanto al sistema operativo, necesitas Windows 10 o Windows 11 de 64 bits. Las versiones de 32 bits quedan totalmente descartadas, tanto por limitaciones de memoria como por compatibilidad con las herramientas que vamos a usar.
La memoria es uno de los puntos clave. Para gpt-oss-20b se recomienda tener al menos 16 GB de RAM para ir con margen y poder mantener el sistema estable mientras el modelo trabaja. Técnicamente puede arrancar en equipos con 8 GB, pero la experiencia se vuelve muy justa y tendrás que cerrar casi todo lo demás para que no haga cuello de botella.
Si hablamos de gpt-oss-120b, la película cambia bastante: mínimo 32 GB de RAM y, idealmente, más, además de una barbaridad de VRAM, por lo que en la práctica su instalación en un PC normal con Windows no suele ser viable.
En cuanto al procesador, no necesitas lo último de lo último, pero tampoco algo prehistórico. Se recomienda como base un Intel Core i5 de cuarta generación en adelante o un AMD Ryzen 3 o superior. La CPU puede encargarse de ejecutar el modelo por sí sola si no tienes GPU, pero la generación de texto será bastante más lenta.
Para el almacenamiento, piensa que los modelos ocupan lo suyo y siempre es buena idea dejar espacio libre para que Windows no se ahogue. Un SSD con al menos 500 GB libres te dará margen para GPT-OSS y otros modelos. A modo orientativo, gpt-oss-20b ronda los 12-13 GB, mientras que gpt-oss-120b puede subir hasta los 70 GB según la versión.
La parte importante para acelerar la generación es la tarjeta gráfica (GPU). Si quieres un rendimiento cómodo, lo ideal es contar con una NVIDIA GeForce RTX 3060 o superior, o una AMD Radeon RX 6700 o superior. Modelos previos siguen funcionando, pero el número de tokens por segundo caerá y notarás más lentitud en las respuestas largas.
Si no tienes GPU dedicada, GPT-OSS puede funcionar tirando solo de CPU y RAM, aunque con una velocidad claramente inferior. Las GPUs integradas ayudan algo, pero ni de lejos se acercan a una tarjeta dedicada moderna.
Por último, necesitarás conexión a Internet solo para descargar el modelo. Una vez descargado e instalado, la ejecución es totalmente offline, de modo que puedes desconectar el cable o el WiFi y seguir usando la IA con normalidad.
Cómo instalar GPT-OSS en Windows usando Ollama (interfaz gráfica y comandos)
Para no pelearte directamente con líneas de código y configuraciones crudas, lo más cómodo es apoyarse en herramientas pensadas para gestionar modelos de lenguaje. Aquí Ollama es una de las opciones más sencillas y pulidas para usuarios de Windows, tanto si quieres usar una interfaz gráfica como si prefieres tirar de terminal.
Ollama funciona como un “lanzador” de modelos LLM en local: se encarga de descargar, almacenar y ejecutar GPT-OSS (y otros modelos como LLaMA, Gemma o Qwen) con una instalación bastante guiada. Es gratuito, de código abierto y está disponible para Windows, macOS y Linux.
El proceso arranca entrando en la web oficial de Ollama y descargando el instalador para Windows, normalmente un archivo llamado algo como OllamaSetup.exe. Guardas el archivo, lo ejecutas y sigues los pasos típicos de cualquier programa de escritorio: aceptar condiciones, elegir carpeta si quieres cambiarla y esperar a que termine.
Antes de instalar, revisa que cumples unas condiciones mínimas: Windows 10/11 de 64 bits, al menos 8 GB de RAM (aunque 16 GB es lo ideal para GPT-OSS), y una CPU x86 con cuatro núcleos como mínimo (por ejemplo, un Intel Core i5/i7 de cuarta generación o un AMD Ryzen 3/5/7). La GPU dedicada es opcional, pero altamente recomendable para acelerar la experiencia.
Una vez que abras Ollama por primera vez, verás una interfaz similar a un chat. En la zona central, bajo el logo del programa, aparece un cuadro donde puedes seleccionar el modelo que quieres usar. Al desplegarlo, encontrarás una lista con los modelos disponibles tanto en la nube como en local.
Entre ellos verás las entradas gpt-oss:20b y gpt-oss:120b. Si estás en un PC doméstico, elige gpt-oss:20b, que es el modelo mediano. Al seleccionarlo, basta con escribir cualquier mensaje en el cuadro de texto (por ejemplo, un simple “hola”) y enviarlo para que Ollama inicie la descarga automática del modelo.
La descarga puede tardar desde unos segundos hasta varios minutos, dependiendo de tu conexión, porque el archivo pesa alrededor de 12,8-13 GB. Una vez completada, el modelo se carga y ya puedes empezar a conversar con GPT-OSS como si estuvieras delante de ChatGPT, pero sin salir de tu ordenador.
Si en lugar de la interfaz gráfica prefieres usar la línea de comandos, Ollama también soporta ese flujo. Desde PowerShell o la terminal de Windows puedes usar órdenes como “ollama pull gpt-oss:20b” para descargar el modelo y “ollama run gpt-oss:20b” para arrancarlo y empezar a chatear. Para el modelo grande, bastaría con cambiar el nombre a gpt-oss:120b.
Instalar y usar GPT-OSS en Windows con LM Studio
Si te apetece un entorno algo más completo y con más parámetros ajustables, puedes probar LM Studio. Es otra herramienta que permite descargar, gestionar y ejecutar modelos de IA en local y también está disponible para Windows, macOS y Linux. Podríamos decir que Ollama es más minimalista y directo, mientras que LM Studio ofrece una interfaz más vistosa y muchas opciones extra.
En cuanto a requisitos, LM Studio para Windows recomienda una CPU de 64 bits con soporte AVX2, 16 GB de RAM para trabajar cómodo con modelos de 7-8B, y una GPU si quieres acelerar todo el proceso. Con 8 GB de RAM todavía puedes jugar con modelos pequeños de 3-4B y contextos cortos, pero para algo del tamaño de gpt-oss-20b es mejor ir sobrado.
En el apartado de almacenamiento, cada modelo puede ocupar entre 2 y más de 20 GB, aunque hay variantes de gpt-oss-20b que se van bastante más arriba dependiendo de cómo estén cuantizados. Lo ideal es reservar al menos 100 GB de espacio libre si piensas descargar varios modelos y trastear con diferentes versiones.
Para instalar LM Studio, entras en su web oficial, eliges la versión de Windows y descargas el ejecutable (suele rondar los 500-600 MB). Haces doble clic, seleccionas la carpeta de destino (requiere alrededor de 1,7 GB de espacio para la propia aplicación) y pulsas en instalar. Cuando termine, verás su interfaz principal lista para trabajar.
El siguiente paso es ir al icono de la lupa en la barra lateral izquierda, que abre el buscador de modelos. Desde ahí puedes explorar todos los modelos compatibles con ejecución local, entre los que se encuentra GPT-OSS en su variante 20b.
En el listado, localiza gpt-oss-20b (puede aparecer como openai/gpt-oss-20b u otra ruta similar) y pulsa en Download. LM Studio empezará a descargar el modelo; de nuevo, el tiempo depende de tu conexión y del tamaño concreto de la versión que hayas elegido.
Cuando la descarga termine, dirígete a la sección de “Chats” en la columna izquierda. Ahí verás un desplegable llamado algo como “Select a model to load”. Elige gpt-oss-20b y se abrirá una pantalla de configuración inicial con varios deslizadores y opciones.
Los dos parámetros más importantes aquí son la longitud del contexto y la cantidad de capas que se descargan en GPU. El contexto marca cuántos tokens (palabras y trocitos de palabra, para entendernos) puede recordar el modelo dentro de una conversación. Cuanto más lo subes, más memoria consume y más cálculo por token hace, lo que significa mayor uso de RAM/VRAM y posibles errores si tu hardware va justo.
La opción de “descarga a GPU” define cuántas capas del modelo se ejecutan directamente en la tarjeta gráfica. Cuantas más capas cargues en GPU, más rápido generará texto, pero también más VRAM absorberá. Si te pasas de la raya y agotas la VRAM, el rendimiento se hundirá o el modelo ni siquiera arrancará, así que lo sensato es ir subiendo poco a poco hasta encontrar el punto dulce.
Una vez afinados estos detalles, pulsas en “Cargar modelo” (Load model) y LM Studio abrirá un chat muy parecido a ChatGPT, donde ya puedes escribir tus preguntas, pegar textos para que te los resuma o pedirle que te ayude con código.
Descargar GPT-OSS desde Hugging Face o GitHub y otras formas de uso
Aunque lo más cómodo para la mayoría de usuarios de Windows es tirar de Ollama o LM Studio, OpenAI también ofrece descargas directas de GPT-OSS en repositorios como Hugging Face y GitHub. Esto está pensado sobre todo para desarrolladores y usuarios avanzados que quieren un control completo sobre la integración.
En Hugging Face encontrarás las distintas variantes de gpt-oss-20b y gpt-oss-120b, con versiones adaptadas y optimizadas por la comunidad para diferentes tipos de hardware y librerías. Cada una puede variar en tamaño (hay builds de 20b que van desde unos 11 GB hasta más de 40 GB) y en rendimiento, según el tipo de cuantización que usen.
El otro punto de descarga oficial es GitHub, donde OpenAI publica los recursos necesarios para trabajar con GPT-OSS, ejemplos de uso, scripts y documentación para integrarlo en proyectos. Desde ahí puedes preparar entornos específicos, contenedores o pipelines personalizados si quieres montar algo más serio que un simple chat local.
Además de la ejecución en PC, también hay opciones para probar GPT-OSS en móviles Android e iOS usando aplicaciones de terceros. Aunque OpenAI no recomienda ninguna en concreta, una opción popular es PocketPal AI, que permite añadir modelos desde Hugging Face y ejecutarlos localmente en algunos teléfonos de gama media-alta.
El procedimiento suele consistir en instalar la app, entrar en la sección de modelos, elegir “Add from Hugging Face”, buscar gpt-oss o gpt-oss-20b y descargar la versión que mejor encaje con el almacenamiento y la memoria de tu dispositivo. Eso sí, en móviles el equilibrio entre peso del modelo y rendimiento es bastante delicado, y no es raro que te toque elegir variantes más pequeñas para que todo vaya fluido.
Qué puedes hacer con GPT-OSS en tu PC con Windows
Una vez que tengas GPT-OSS instalado y funcionando con Ollama o LM Studio, se abre un abanico enorme de usos prácticos que puedes explotar en tu día a día con la tranquilidad de que todo se queda en tu ordenador.
Por el lado del texto, es perfecto para redactar artículos, resúmenes, correos, guiones y publicaciones para redes sociales. Puedes darle un documento largo en PDF o en texto plano y pedirle que te saque las ideas clave, que lo adapte a un público distinto, que mejore el tono o que sintetice las conclusiones en unas pocas líneas.
También es muy útil como asistente de estudio y trabajo: explicarte conceptos, generar esquemas de temas, crear tarjetas de repaso, corregir redacciones o plantear ejercicios de práctica. Si lo combinas con la capacidad de analizar archivos que arrastras a la ventana del programa, tienes un aliado potente para manejar informes, trabajos académicos o documentación técnica.
En el terreno del desarrollo, GPT-OSS sirve como compañero de programación offline. Puede revisar fragmentos de código, señalar errores, sugerir refactors, generar funciones de apoyo o explicar qué hace un script línea por línea. No sustituye a un IDE ni a un depurador, pero sí te ahorra mucho tiempo de búsqueda y te da ideas cuando te atascas.
Además, gracias a las APIs locales que exponen herramientas como Ollama, puedes integrar GPT-OSS en tus propias aplicaciones, automatizar tareas o crear pequeños asistentes personalizados que respondan a tus propios datos sin necesidad de depender de servicios externos.
La principal limitación es que el modelo no tiene acceso a información en tiempo real. Todo lo que sabe viene de su entrenamiento previo, por lo que no es la mejor opción para consultar noticias de última hora, cambios legales muy recientes o datos que varían constantemente. Para eso seguirás necesitando un modelo conectado a la red o una búsqueda tradicional.
A nivel de rendimiento, es normal que notes que GPT-OSS es más lento que un ChatGPT alojado en un centro de datos lleno de GPUs. Cuanto más largo sea el contexto y más compleja la tarea, más se hará de rogar la respuesta, especialmente si tu GPU o tu RAM van justas. Cerrar navegadores con muchas pestañas o programas pesados mientras usas el modelo ayuda a que todo vaya más suelto.
Con todo esto, GPT-OSS se convierte en una especie de “copiloto” que vive en tu propio PC con Windows: gratis, privado, altamente personalizable y disponible incluso sin conexión. Con un poco de paciencia para la instalación inicial y algunos ajustes de hardware, tienes a mano un asistente muy capaz para escribir, programar, estudiar y experimentar con IA generativa sin salir de tu escritorio.
Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.