- OpenClaw es un agente de IA local-first que se ejecuta siempre activo en tu PC, usando el contexto de archivos, correo y aplicaciones sin enviar datos a la nube.
- NVIDIA ofrece una guía para configurarlo en Windows mediante WSL, apoyándose en LM Studio u Ollama y en la aceleración CUDA de las GPUs RTX.
- La elección del modelo LLM depende de la VRAM: desde qwen3-4B-Thinking-2507 en 8–12 GB hasta gpt-oss-120b en sistemas DGX Spark con hasta 128 GB.
- La alianza con VirusTotal y el ecosistema de skills de ClawHub permiten ampliar funciones manteniendo un alto nivel de seguridad y control de datos.

La inteligencia artificial se ha colado en nuestro día a día a una velocidad brutal: la usamos para trabajar, estudiar, crear contenido y automatizar tareas de todo tipo. Hasta hace nada, lo normal era depender de servicios en la nube como ChatGPT o Gemini, pero cada vez más gente quiere llevar esa potencia directamente a su propio ordenador, sin depender de servidores externos ni ceder datos sensibles.
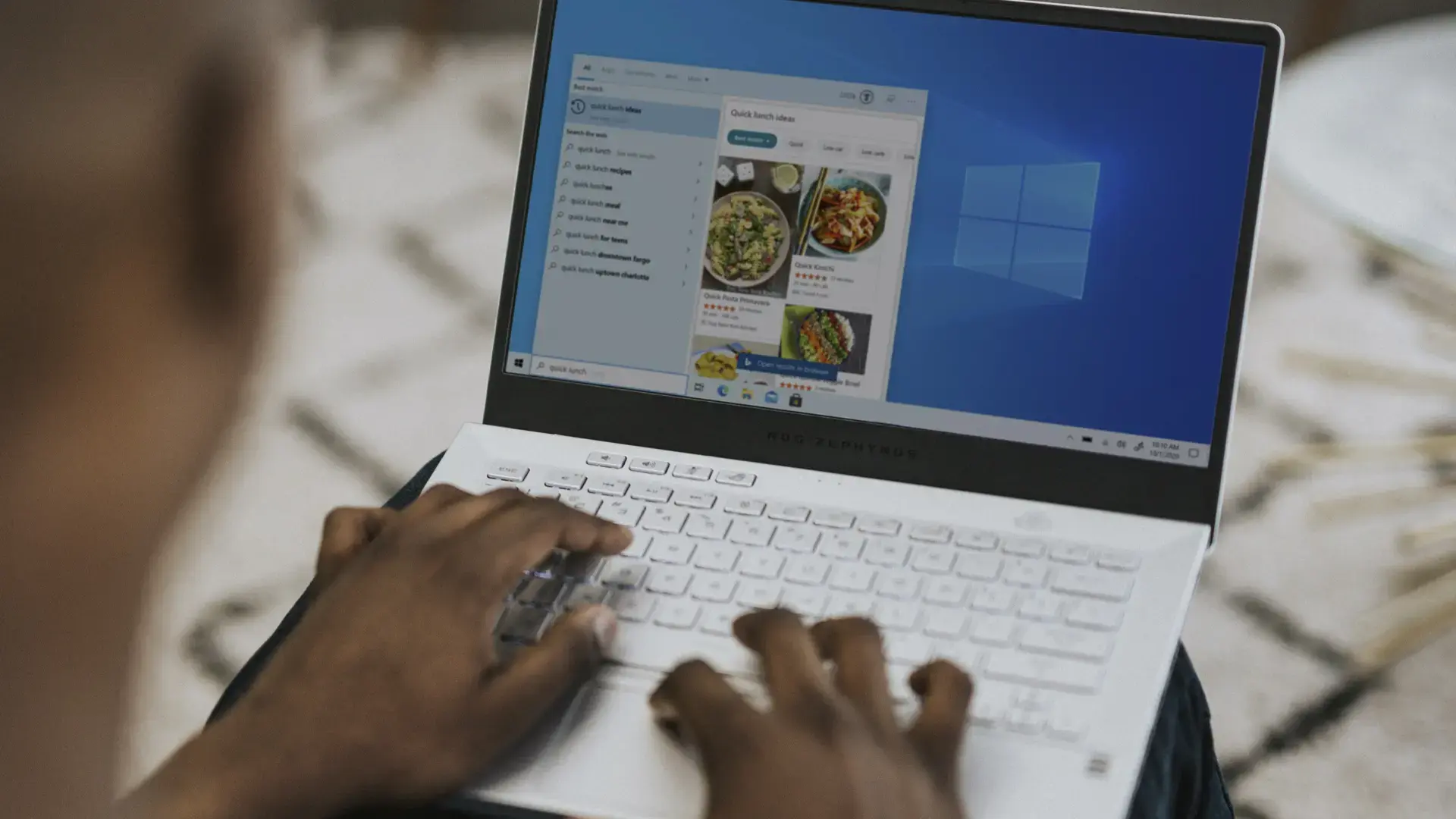
En ese contexto aparece OpenClaw, un agente de IA local-first que está dando muchísimo que hablar. No es solo “otro chatbot”: es un sistema pensado para estar siempre activo en tu PC, leer el contexto de tus archivos, correo y aplicaciones, y ejecutar acciones por ti. Y lo mejor es que, gracias a las GPUs NVIDIA RTX y a la guía oficial que ha publicado NVIDIA, hoy es posible ejecutarlo completamente en local aprovechando los Tensor Cores de tu gráfica para obtener un rendimiento muy serio sin salir de casa.
Qué es exactamente OpenClaw y por qué importa tanto
OpenClaw se define como un agente de IA total, diseñado para tomar decisiones y realizar tareas de manera autónoma con un objetivo claro: hacer por ti todo aquello que normalmente harías tú frente al ordenador. No se limita a responder preguntas como haría un chatbot clásico, sino que puede conectar con tus aplicaciones, leer documentos, cruzar información y ejecutar acciones sin que tengas que estar encima constantemente.
La clave está en su enfoque local-first: OpenClaw “vive” en tu propio PC, se ejecuta en segundo plano y mantiene un contexto persistente de tus conversaciones, correos, ficheros y herramientas. De este modo, puede recordar lo que hablabas ayer, entender proyectos en marcha y relacionar información procedente tanto de internet como de tu almacenamiento local.
Este proyecto, creado inicialmente por Peter Steinberger, ha pasado por varios nombres (Clawbot, Molbot) hasta consolidarse como OpenClaw. A pesar de que ha terminado siendo adquirido por OpenAI, su esencia sigue siendo la misma: código abierto, uso gratuito y fuerte enfoque en la comunidad, con miles de usuarios construyendo skills y ampliando sus capacidades.
Una de las cosas que más llama la atención es el crecimiento de su ecosistema: ClawHub, el repositorio central de skills de la comunidad, supera ya las 5.700 extensiones, y el proyecto ha alcanzado la cifra récord de unas 150.000 estrellas en GitHub en solo unas semanas, algo al alcance de muy pocos proyectos de software.
Para reforzar la seguridad de todo este ecosistema, OpenClaw cuenta con una alianza estratégica con VirusTotal, la conocida empresa malagueña propiedad de Google. Gracias a esta colaboración, las skills de la comunidad se analizan automáticamente para detectar código potencialmente malicioso antes de que puedan causar problemas en el equipo de los usuarios.
Por qué los agentes de IA son el siguiente paso tras ChatGPT
Cuando se habla de agentes de IA, se hace referencia a sistemas capaces de actuar de forma autónoma, tomar decisiones y ejecutar tareas sin que el usuario tenga que dar cada paso de forma manual. Es decir, van un paso más allá que un simple modelo conversacional que solo responde a lo que se le pregunta.
A diferencia de ChatGPT o Gemini, que suelen ejecutarse en la nube y actúan como asistentes conversacionales clásicos, un agente de IA como OpenClaw se integra de lleno con tu sistema: accede a tus archivos locales, monitoriza correos, consulta tu calendario y puede disparar acciones en diferentes aplicaciones.
Esta diferencia hace que la privacidad y el control de datos cobren un protagonismo absoluto. Al ejecutarse de forma local, los datos no tienen por qué salir de tu PC, algo especialmente interesante para profesionales que manejan información sensible, empresas reguladas o cualquier persona que no quiera mandar medio disco duro a servidores externos.
Además, el hecho de que OpenClaw esté pensado como agente siempre activo permite flujos de trabajo continuos: puede ir revisando tu bandeja de entrada, actualizando proyectos o generando resúmenes sin que tengas que pedírselo cada vez, actuando casi como un asistente personal digital de toda la vida, pero con esteroides.

Qué puede hacer OpenClaw en tu ordenador
La lista de usos reales de OpenClaw es larga, pero hay algunas funciones que destacan claramente. En el día a día, uno de los puntos fuertes es la automatización del correo electrónico: el agente puede leer hilos previos, entender el contexto de una conversación y generar respuestas o borradores que respeten tu tono y tus criterios habituales.
También es muy potente a la hora de gestionar agendas y calendarios. OpenClaw puede revisar invitaciones, sugerir huecos para reuniones, recordarte citas importantes y reorganizar eventos en función de tus prioridades o de cambios repentinos en tu planificación.
En el ámbito profesional, destaca su capacidad para la gestión de proyectos. El agente puede monitorizar documentos, actas de reuniones, tareas pendientes y fechas clave, y a partir de ahí ir recordándote hitos, proponiendo próximos pasos o incluso generando resúmenes de estado para enviar al equipo.
Otro uso muy interesante es la investigación combinada: OpenClaw puede realizar búsquedas en la web y, al mismo tiempo, cruzar esos datos con informes, PDFs, hojas de cálculo y notas que tengas guardadas en tu PC. En la práctica, esto equivale a tener un sistema de RAG (Generación Aumentada por Recuperación) totalmente local, donde las respuestas se adaptan por completo a tu propio repositorio de información privada.
Además, el sistema es extensible mediante skills creadas por la comunidad, que amplían desde integraciones con herramientas específicas hasta flujos de trabajo muy complejos. Eso sí, se recomienda encarecidamente usar skills verificadas y bien revisadas para evitar problemas de seguridad o fuga de datos.
Seguridad, privacidad y recomendaciones de uso
Para que OpenClaw pueda funcionar de forma efectiva necesita acceso amplio a tus datos: correos, ficheros locales, aplicaciones conectadas, etc. Esto abre la puerta a una productividad espectacular, pero también supone un riesgo claro si se configura sin cuidado o se instalan skills maliciosas.
Por ese motivo, muchos expertos recomiendan no ejecutar OpenClaw directamente en tu equipo principal si en él almacenas información extremadamente sensible. En su lugar, puede ser buena idea optar por una máquina secundaria, un PC dedicado o incluso una máquina virtual suficientemente potente, donde puedas darle permisos amplios sin miedo a exponer tus datos más delicados.
La integración con VirusTotal juega aquí un papel vital: las más de 5.700 skills disponibles en ClawHub se someten a análisis automatizados para detectar software malicioso o comportamientos sospechosos. Aun así, la responsabilidad última recae en el usuario, que debería limitarse a instalar skills de autores fiables y con buena reputación.
En términos de coste, la cosa es sencilla: OpenClaw es gratuito y de código abierto. No hay licencias de pago por el propio agente, aunque obviamente necesitarás un equipo con una GPU competente y, si lo deseas, hardware de gama alta para poder exprimir modelos de lenguaje más grandes.
Si se usa con cabeza y se configura en un entorno bien aislado, OpenClaw ofrece una combinación muy potente de privacidad, control local y automatización avanzada, algo difícil de encontrar en servicios puramente basados en la nube.
NVIDIA RTX y OpenClaw: la guía para ejecutarlo en local
NVIDIA ha publicado una guía oficial muy detallada explicando cómo poner en marcha OpenClaw de forma totalmente local en ordenadores equipados con GPUs GeForce RTX, NVIDIA RTX profesionales y sistemas DGX Spark. Esta documentación describe todo el proceso, desde la configuración del entorno en Windows hasta la elección de modelos y herramientas de inferencia.
La propuesta se basa en aprovechar el Subsistema de Windows para Linux (WSL), que permite ejecutar un entorno Linux dentro de Windows con acceso acelerado a la GPU. Gracias a los controladores y a la pila CUDA de NVIDIA, las aplicaciones de IA pueden utilizar directamente los Tensor Cores de las RTX para acelerar de forma masiva el cálculo.
En la práctica, esto significa que OpenClaw puede apoyarse en gestores de modelos como LM Studio u Ollama para cargar y servir LLMs en tu máquina, mientras se beneficia de optimizaciones específicas como Llama.cpp o integraciones CUDA. El resultado es una inferencia mucho más rápida, con latencias reducidas y un uso eficiente de la memoria de la GPU.
Según la propia guía de NVIDIA, este enfoque permite escalar desde PCs de escritorio relativamente modestos con una RTX de gama media hasta estaciones DGX Spark con memoria masiva, capaces de ejecutar modelos gigantes de más de 100.000 millones de parámetros con soltura.
Además, una vez configurado, el agente se puede controlar desde aplicaciones de mensajería como Discord, WhatsApp o Telegram, actuando como un asistente que responde y ejecuta tareas a través de conversaciones, algo muy cómodo si pasas el día entre chats y canales.
Modelos recomendados según la VRAM de tu GPU
Uno de los puntos clave a la hora de ejecutar OpenClaw en local es la memoria de vídeo (VRAM) de la tarjeta gráfica. Dependiendo de cuánta VRAM tengas disponible, podrás usar modelos más pequeños o mucho más grandes y capaces. NVIDIA ofrece recomendaciones concretas para que la experiencia sea fluida y estable.
Para el rango de 8 a 12 GB de VRAM, típico de muchas GPUs GeForce RTX de gama media, se sugiere utilizar modelos alrededor de los 4.000 millones de parámetros. Un ejemplo es qwen3-4B-Thinking-2507, que combina un tamaño razonable con buenas capacidades de razonamiento y tiempos de respuesta rápidos.
Si tu GPU cuenta con 16 GB de VRAM, el abanico se amplía a modelos más grandes como gpt-oss-20b. Este tipo de modelo proporciona una comprensión más profunda del contexto, mejor manejo de textos largos y respuestas más matizadas, ideal para quien usa OpenClaw a nivel profesional con muchos documentos y correos complejos.
Cuando hablamos de tarjetas o sistemas con 24 a 48 GB de VRAM, entran en juego pesos pesados como Nemotron-3-Nano-30B-A3B. Aquí ya estamos en una liga donde el modelo puede manejar tareas de razonamiento mucho más sofisticadas, contextos enormes y múltiples flujos de trabajo simultáneos sin ahogarse.
En la parte más alta del espectro, los sistemas DGX Spark con 96 a 128 GB de memoria permiten cargar modelos de tamaño extremo, como gpt-oss-120b. Estos modelos de más de 100B parámetros están pensados para entornos empresariales exigentes, laboratorios de investigación o equipos que necesitan capacidades de lenguaje de vanguardia para varios proyectos y usuarios a la vez.
En todos los casos, los Tensor Cores de las RTX juegan un papel fundamental: su arquitectura está optimizada para las operaciones de precisión mixta usadas en redes neuronales, lo que se traduce en inferencias mucho más rápidas y eficientes que si se ejecutara todo en CPU.
WSL, LM Studio, Ollama y el stack técnico que hay detrás
La base técnica que propone NVIDIA para sacar partido a OpenClaw en Windows se apoya en WSL (Windows Subsystem for Linux). Este componente permite arrancar una distribución Linux liviana dentro de Windows, con acceso directo a la GPU a través de los controladores NVIDIA y la pila CUDA.
Sobre ese entorno Linux se instalan herramientas como LM Studio u Ollama, que actúan como servidores de modelos de lenguaje. En la práctica, estas utilidades se encargan de descargar, cuantizar y ejecutar LLMs, ofreciendo una API o interfaz local que OpenClaw puede usar para “pensar” y responder.
Muchas de estas soluciones utilizan internamente proyectos como Llama.cpp, fuertemente optimizados para ejecutar modelos de forma eficiente en GPU, con soporte para diferentes formatos, cuantizaciones y tamaños de contexto. Gracias a estas optimizaciones, es posible conseguir latencias de milisegundos incluso en equipos domésticos bien configurados.
Desde el punto de vista del usuario, el flujo suele ser bastante directo: configuras WSL, instalas el stack de NVIDIA (drivers, CUDA), montas LM Studio u Ollama, descargas el modelo recomendado para tu VRAM y, por último, conectas OpenClaw a ese servidor local para que lo use como motor de IA.
A partir de ahí, OpenClaw puede ejecutarse como un servicio que permanece activo y se comunica contigo mediante su propia interfaz o integraciones con plataformas de mensajería y aplicaciones de escritorio, según cómo lo tengas configurado.
Ventajas prácticas de ejecutar OpenClaw en local con RTX
Más allá de la teoría, las ventajas de correr OpenClaw directamente sobre una GPU NVIDIA RTX se notan en el día a día. La primera es la latencia reducida: al no depender de la nube, las peticiones no tienen que viajar por internet, y la inferencia se hace en tu equipo con la máxima aceleración posible, pudiendo además aplicar técnicas para mejorar el rendimiento del sistema.
La segunda gran ventaja es la privacidad. Toda la información sensible —correos, documentos internos, datos de clientes, informes confidenciales— puede quedarse en tu máquina, ya que el agente no necesita enviar nada a servidores externos para trabajar, algo clave para quienes tienen requisitos legales o de cumplimiento normativo estrictos.
También está el factor de control y personalización. Al ser un sistema abierto ejecutado en tu propio hardware, puedes ajustar qué modelos usas, cómo se cuantizan, qué contexto manejan y cómo se integran con tus herramientas. No dependes de las limitaciones de una API ajena ni de cambios unilaterales de terceros.
Por último, si ya cuentas con una RTX decente, el coste marginal de montar OpenClaw en local es muy bajo, sobre todo comparado con suscripciones mensuales a servicios cloud o consumo intensivo de APIs de pago para LLMs de gran tamaño.
Todo esto hace que la combinación de OpenClaw + NVIDIA RTX sea una opción muy atractiva para usuarios avanzados, desarrolladores, freelancers y empresas que quieran apostar por agentes de IA potentes manteniendo el control máximo sobre sus datos.
Visto todo lo anterior, OpenClaw se sitúa como uno de los agentes de IA locales más prometedores del momento: combina un enfoque local-first orientado a la privacidad, una comunidad muy activa que aporta miles de skills, integración con herramientas clave como LM Studio u Ollama y un soporte técnico explícito por parte de NVIDIA para ejecutarlo completamente en local sobre GPUs RTX y sistemas DGX Spark. Con la guía oficial para escoger el modelo ideal según tu VRAM, la alianza con VirusTotal para reforzar la seguridad y la posibilidad de usarlo como asistente persistente que se conecta a tu correo, calendario, proyectos y chats, se convierte en una solución muy potente para quien quiera llevar la IA generativa y los flujos agentivos al siguiente nivel sin depender de la nube.
Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.