- Configurar CI/CD con GitHub Actions implica definir workflows YAML con jobs para linting, pruebas, build, release y despliegue automatizado.
- Los pipelines eficaces usan acciones reutilizables, matrices, caché de dependencias y gestión segura de secretos para escalar a múltiples proyectos y entornos.
- Integrar herramientas de terceros y monitorización, junto con reglas de protección de ramas, refuerza la calidad, la seguridad y la trazabilidad de cada despliegue.
Montar un flujo de CI/CD con GitHub Actions desde cero no es solo encadenar unos cuantos YAML y darle a un botón de despliegue. Es, en realidad, diseñar cómo tu equipo integra, prueba y publica el código, cómo se reduce el riesgo de errores y cómo se automatiza todo lo posible para que nadie tenga que estar un viernes por la tarde pendiente de un deploy manual.
A lo largo de esta guía vas a ver paso a paso cómo entender los conceptos clave de CI, entrega continua y despliegue continuo, cómo se estructura un workflow en GitHub Actions, cómo construir pipelines reales (con tests, linting, build, releases y despliegues) y cómo aplicar buenas prácticas avanzadas, integraciones con otros servicios y medidas de seguridad, basado en ejemplos prácticos y enfoques reutilizables que se usan en proyectos de verdad.
Qué es CI/CD y por qué merece la pena montarlo bien
La integración continua (CI) consiste en integrar los cambios de código en la rama principal con la máxima frecuencia posible, validándolos automáticamente mediante compilaciones y pruebas. La idea es detectar errores de integración cuanto antes, en lugar de encontrarse con un caos monumental el día que se intenta fusionar todo para una versión.
La entrega continua (continuous delivery) lleva esa idea un paso más allá: cada cambio que pasa las pruebas se prepara automáticamente para ser desplegado en un entorno de pruebas o incluso en producción. El lanzamiento suele requerir una acción manual (por ejemplo, pulsar un botón en el workflow o aprobar una pull request), pero el proceso técnico está automatizado.
El despliegue continuo (continuous deployment) es el nivel máximo de automatización: si el código pasa todas las fases del pipeline (tests unitarios, integraciones, seguridad, rendimiento, etc.), se publica directamente en producción sin intervención humana. Solo un fallo en el pipeline frena el despliegue.
En la práctica, un buen pipeline CI/CD reduce el tiempo de comercialización, mejora la calidad, disminuye la dependencia de tareas manuales frágiles y hace que los equipos se centren en crear funcionalidad, no en pelearse con despliegues. Además, permite ciclos de desarrollo mucho más rápidos y seguros.
Cómo funciona GitHub Actions en un pipeline CI/CD
GitHub Actions es la plataforma de automatización integrada en GitHub que te permite definir flujos de trabajo (workflows) en archivos YAML dentro del repositorio. Cada workflow se activa por uno o varios eventos (push, pull_request, schedule, workflow_dispatch…) y ejecuta uno o varios jobs en máquinas virtuales (runners) que pueden ser de GitHub o autoservidas.
Los componentes clave de un workflow YAML son los siguientes: la clave name asigna un nombre descriptivo al workflow; la clave on define los disparadores (push, pull_request, workflow_dispatch para ejecuciones manuales, schedule para CRON, etc.); la clave jobs agrupa uno o varios trabajos que pueden correr en paralelo o en secuencia.
Dentro de cada job se especifica el runner con runs-on (por ejemplo, ubuntu-latest) y una lista de steps, donde cada paso puede usar una acción predefinida con uses (como actions/checkout o actions/setup-node) o ejecutar comandos de shell con run. También se usan env para variables de entorno, with para parámetros de acciones, secrets para credenciales cifradas y if para ejecutar pasos condicionalmente.
Las acciones (actions) son bloques reutilizables de lógica que automatizan tareas concretas: instalar dependencias, desplegar a un proveedor cloud, gestionar versiones, enviar notificaciones, etc. Muchas están disponibles en GitHub Marketplace y permiten integrar herramientas como Jest, Cypress, SonarCloud, Kinsta, AWS, Azure, Google Cloud, Slack o herramientas de seguridad.
Los runners son las máquinas donde realmente se ejecuta el pipeline. GitHub ofrece runners hospedados (Ubuntu, Windows, macOS) pero también puedes montar runners propios si necesitas más control o acceso a recursos internos. Cada job se lanza en un entorno nuevo, lo que reduce conflictos entre ejecuciones y facilita la gestión de dependencias.
Primeros pasos: estructura básica de un workflow CI/CD
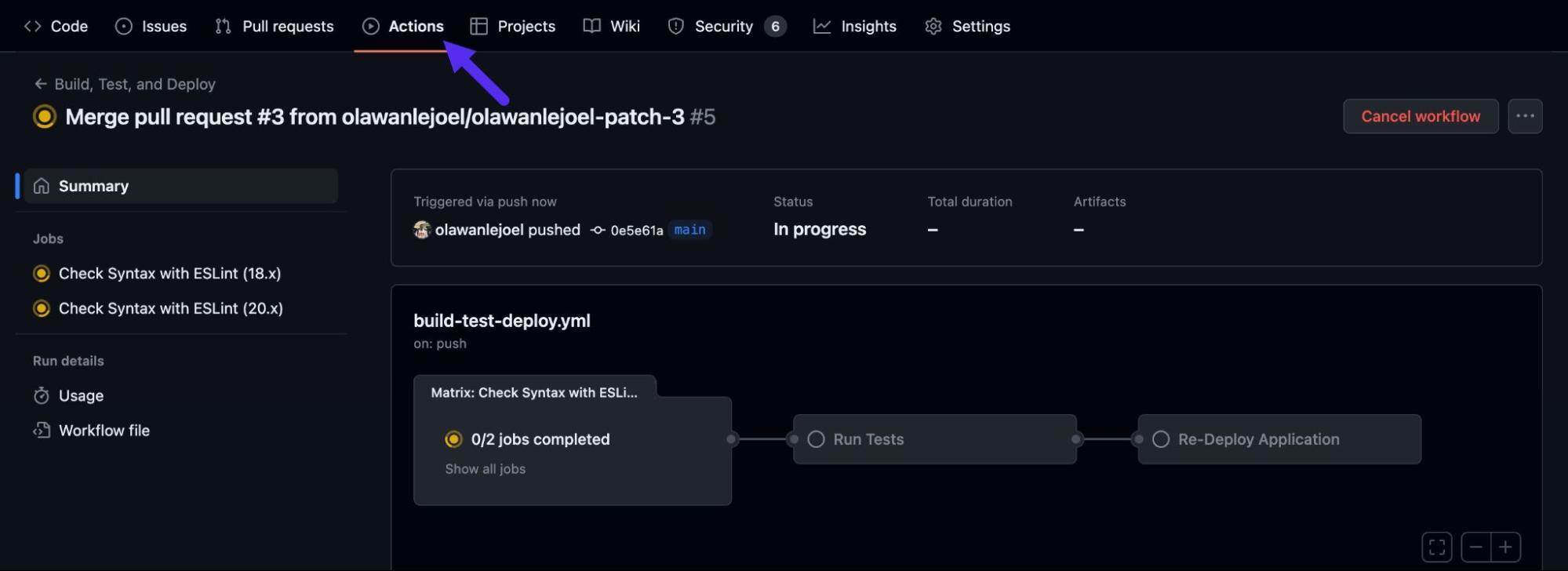
Todo arranca creando el directorio .github/workflows en la raíz del repositorio y añadiendo un archivo YAML, por ejemplo ci.yml o build-test-deploy.yml. La convención de nombres no es estricta, pero ayuda que describa la función del workflow.
Un workflow típico para integración continua se activa con push y pull_request sobre la rama principal. Algo así como: ejecutar tests y linters cada vez que se sube código o se abre/modifica una PR contra main, bloqueando el merge si algo falla.
Para automatizar tareas periódicas (copias de seguridad, limpiezas, chequeos de seguridad, etc.) se puede usar el evento schedule con sintaxis CRON. Por ejemplo, 0 0 * * * para ejecutar a medianoche (UTC) o 0 8 * * 1 para lanzar un job todos los lunes a las 8:00.
La sintaxis CRON tiene cinco campos: minuto, hora, día del mes, mes y día de la semana, con valores que admiten comodines como * (cualquiera), rangos (1-5), listas (1,15,30) o pasos (*/5). Esto permite definir horarios muy precisos para los jobs programados.
A nivel de jobs, una buena práctica inicial es separar al menos tres tareas: una para comprobaciones de estilo y calidad (por ejemplo ESLint), otra para ejecutar tests y otra para el despliegue, de forma que cada una dependa de la anterior mediante needs. Así te aseguras de que solo se despliega si tanto lint como tests han ido bien.
Ejemplo sencillo de CI con Node, Jest, ESLint y Prettier
Imagina una aplicación React con TypeScript que ya trae configurados Jest, ESLint y Prettier. Puedes usar un template base para no perder tiempo en la configuración inicial y centrarte en el pipeline. Desde GitHub Actions vas a automatizar lo que harías a mano: instalar dependencias, pasar el linter, formatear y ejecutar tests.
Un workflow de CI básico podría activarse en cada push y pull_request a la rama principal (o master). Dentro habría un job test que se ejecuta en ubuntu-latest y hace lo siguiente: checkout del repositorio con actions/checkout, configuración de Node con actions/setup-node, instalación de dependencias con npm ci, ejecución de npm run lint, luego npm run prettier y por último npm run test o un comando más específico como npm run test:unit:coverage.
La clave está en que todo esto sea automático y rápido: cada vez que alguien abre una PR o empuja cambios, el workflow se dispara, valida el código y, si algo falla, GitHub marca la PR con checks rojos. Hasta que no se solucionen los problemas, no se debe fusionar la rama, lo que evita errores tontos en main.
Para mejorar el rendimiento del pipeline conviene aprovechar el caché de dependencias (por ejemplo, usando el parámetro cache: ‘npm’ de setup-node) y generar artifacts con actions/upload-artifact cuando quieras compartir resultados entre jobs (por ejemplo, informes de cobertura o builds intermedias).
Otra mejora muy habitual es usar una estrategia de matriz (matrix) para probar en varias versiones de Node (por ejemplo, 18.x y 20.x) o en sistemas operativos distintos. Así aseguras compatibilidad sin tener que escribir workflows duplicados.
Construir una canalización de CI completa
En un pipeline de CI bien montado no basta con lanzar unos cuantos tests sueltos. Lo habitual es combinar varios niveles de pruebas: unitarias, de integración y, cuando sea viable, pruebas end-to-end (E2E) automatizadas.
Los casos de prueba deben cubrir escenarios normales y casos límite para detectar no solo errores obvios sino condiciones raras de borde. Conviene revisar y actualizar el conjunto de pruebas conforme la aplicación crece, de lo contrario acabas con un suite desfasado que ya no protege lo que debería.
GitHub Actions permite ejecutar pruebas en paralelo mediante jobs independientes o matrices, reduciendo notablemente el tiempo total del pipeline. Por ejemplo, un job para pruebas unitarias, otro para pruebas de integración y otro para E2E, todos arrancando en paralelo tras superar el lint.
La configuración de notificaciones es otro punto importante. Puedes integrar el pipeline con Slack, Microsoft Teams o servicios similares para avisar cuando una build falla o se completa un despliegue. Así el equipo se entera al momento y puede reaccionar rápido sin estar refrescando la pestaña de Actions.
Algunas buenas prácticas de CI que merece la pena aplicar son: revisar periódicamente tiempos de compilación y tasas de éxito para detectar cuellos de botella; optimizar el uso de cachés y dependencias; mantener estándares de código con linters y revisiones; y documentar bien el pipeline para que cualquiera del equipo sepa cómo funciona y cómo depurarlo.
Entrega continua: preparar builds y releases
La fase de entrega continua (CD entendida como delivery) se centra en preparar versiones listas para ser desplegadas y estudiar distintas estrategias de release, aunque el disparo del deploy sea manual. En GitHub Actions es frecuente tener un workflow llamado, por ejemplo, CD que se ejecuta solo mediante workflow_dispatch, es decir, manualmente desde la pestaña Actions.
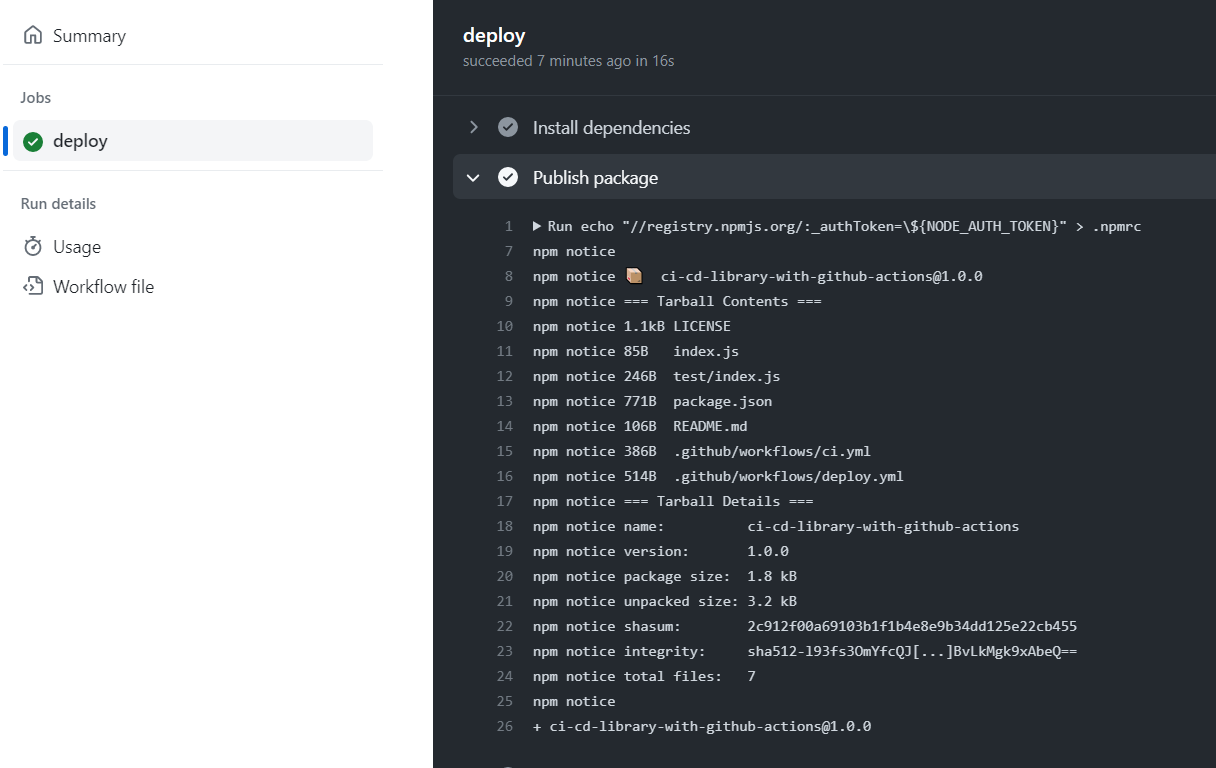
Esta fase suele reutilizar buena parte de lo que hace la CI: instalar dependencias, ejecutar tests (aunque a veces se omiten lint y formateo) y luego ejecutar la build de la aplicación. A partir de ahí, vienen los pasos específicos de release: generar artefactos, crear tags, publicar en repositorios de paquetes o contenedores, etc.
Un patrón muy extendido es automatizar la versión a partir del package.json o del pom.xml usando scripts o herramientas de versionado semántico. Puedes, por ejemplo, leer el número de versión actual, eliminar sufijos tipo SNAPSHOT, incrementar la versión con npm version o equivalentes y usar ese valor como tag para la release.
Para crear releases en GitHub existen acciones como ncipollo/release-action, que publican una nueva release asociada a un tag ya creado, generan notas automáticamente e incluso adjuntan artefactos del build. Después se puede preparar la siguiente versión de desarrollo añadiendo un sufijo tipo -SNAPSHOT.0 y empujando los cambios a la rama remota.
Si trabajas con múltiples lenguajes y tipos de artefacto (imágenes Docker, librerías Java o paquetes NPM), conviene diseñar workflows reutilizables que abstraigan la lógica común (build, versionado, tag, release) y deleguen en tareas específicas según el tipo de proyecto, usando condiciones if y entradas (inputs) para activar o desactivar bloques concretos.
Despliegue continuo: de GitHub a la nube
Cuando hablamos de despliegue continuo nos referimos a automatizar la publicación de los artefactos en los entornos de ejecución reales: Kubernetes, App Engine, Functions, servidores tradicionales, plataformas como Kinsta, Netlify o similares. GitHub Actions puede integrarse con prácticamente cualquier proveedor.
Un caso típico es despliegue automático a Netlify para aplicaciones estáticas o frontends. Allí basta con conectar el repositorio de GitHub, elegir la rama, el comando de build y el directorio a publicar. Una vez configurado, cada vez que se fusionan cambios en la rama principal, Netlify compila y despliega automáticamente tras pasar el workflow de CI.
Otro ejemplo interesante es usar la API de Kinsta desde un job de GitHub Actions. Se configura un paso que ejecuta un comando curl contra el endpoint de despliegue, enviando el app_id y la rama a desplegar. Las credenciales (clave de API y demás) se almacenan como secrets en GitHub y se inyectan como variables de entorno en el job.
Para proveedores cloud como AWS, Azure o Google Cloud existen acciones específicas en el Marketplace que facilitan la autenticación y el despliegue: por ejemplo, aws-actions/configure-aws-credentials para AWS, azure/login para Azure o google-github-actions/auth para GCP. Con ellas puedes desplegar en EC2, App Services, GKE, Cloud Functions, S3, etc.
En entornos más complejos es habitual separar varios workflows de deploy, uno por tipo de runtime (por ejemplo, deploy-gke.yml, deploy-gae.yml, deploy-cloud-function.yml), de modo que cada uno reciba solo los inputs relevantes y mantenga una complejidad razonable. Todos pueden compartir acciones reutilizables para configurar el proveedor, gestionar credenciales y enviar notificaciones.
Diseñar pipelines reutilizables y escalables con GitHub Actions
Cuando gestionas decenas o cientos de repositorios, copiar y pegar el mismo workflow en todos ellos es inviable. Es mucho más sostenible crear workflows reutilizables y acciones compartidas en un repositorio central, y que cada proyecto los invoque pasando simplemente parámetros de configuración.
Un patrón muy potente es separar el pipeline en tres grandes fases reutilizables: build (integración continua y análisis estático), release (generación de artefactos y versiones) y deploy (despliegue al entorno de ejecución y notificaciones). Cada fase se implementa como workflow reusable al que se le pasan inputs como el tipo de proyecto, el entorno de destino o los comandos de Task a ejecutar.
Para desacoplar la lógica del lenguaje concreto se pueden usar herramientas como Task (una alternativa sencilla a Make) que define comandos genéricos para tests, análisis o builds. El workflow llama a Task, y cada repositorio define en su taskfile.yml cómo se ejecutan esos comandos según sea Node, Java, etc.
Además, es habitual incluir acciones de soporte reutilizables para tareas transversales: configurar Gradle o Java, preparar Node, autenticar con Google Cloud, crear releases de Git, gestionar información de build o enviar notificaciones a Slack. Estas acciones viven en .github/actions y se usan desde múltiples workflows.
Una regla de diseño muy útil es que los repositorios de aplicaciones solo utilicen workflows reutilizables (no acciones de bajo nivel directamente). Así se centraliza la lógica compleja en el repositorio de pipelines, facilitando el mantenimiento y permitiendo evolucionar los workflows manteniendo compatibilidad hacia atrás.
Control de calidad, seguridad y cumplimiento en GitHub Actions
Un pipeline moderno no se limita a compilar y pasar tests. Debe incorporar también controles de seguridad, calidad de código y cumplimiento de estándares. GitHub ofrece varias capacidades nativas, como code scanning y secret scanning, además de integraciones con herramientas externas.
La gestión de secretos es crítica. Nunca se deben escribir claves, tokens o contraseñas directamente en los YAML. En su lugar, se almacenan como secrets a nivel de repositorio u organización. Los workflows pueden referenciarlos con la sintaxis ${{ secrets.NOMBRE_DEL_SECRET }} y utilizarlos como variables de entorno.
Es recomendable revisar y ajustar periódicamente los permisos de acceso a secretos, ramas protegidas y entornos. Por ejemplo, limitar qué ramas pueden hacer deploy a producción, exigir revisiones obligatorias de PR y requerir que los checks de estado (CI y tests) pasen antes de permitir un merge.
Para reforzar la calidad del código se pueden añadir pasos de análisis estático y seguridad: linters de estilo, herramientas como PMD, Checkstyle o SpotBugs para Java, ESLint para JavaScript/TypeScript, y escáneres de vulnerabilidades de dependencias. Estas herramientas se integran sin dificultad como nuevos steps del job de CI.
En proyectos con requisitos fuertes de cumplimiento es habitual registrar artefactos de auditoría: guardar logs de despliegue, notificar a canales específicos de Slack cuando hay un deploy a producción, o archivar informes de cobertura y escaneos de seguridad como artifacts para poder consultarlos a posteriori.
Monitorización, logs y solución de problemas
GitHub Actions ofrece registros muy detallados de cada ejecución de workflow: puedes ver qué pasos se han ejecutado, cuánto tiempo han tardado, qué comandos se han lanzado y qué salida han generado. Cuando algo falla, esos logs son el punto de partida para entender qué ha pasado.
Para diagnósticos más avanzados es posible integrar los workflows con herramientas de monitorización y logging como Datadog, New Relic o Splunk. De este modo puedes correlacionar la ejecución de pipelines con métricas de infraestructura, rendimiento de la aplicación o logs detallados de producción.
Los errores típicos en pipelines CI/CD suelen venir de dependencias mal resueltas, versiones de herramientas incompatibles, permisos insuficientes para acceder a recursos externos o errores lógicos en scripts. Una buena práctica es dar nombres descriptivos a los steps y utilizar mensajes claros de error para facilitar la depuración.
También ayuda mucho mantener el pipeline modular: si se separan bien las fases (check, build, deploy) y los jobs, es más fácil localizar en qué punto exacto se ha roto algo. A partir de ahí, puedes re-ejecutar solo el job o el workflow fallido tras realizar los ajustes necesarios.
Si además combinas esta observabilidad con notificaciones en tiempo real (por ejemplo, avisos de builds fallidas en canales de Slack específicos), el equipo puede reaccionar al instante y reducir el tiempo medio de resolución de incidencias relacionadas con el pipeline.
Diseñar y mantener un flujo de CI/CD robusto con GitHub Actions implica combinar conceptos de integración continua, entrega y despliegue, una buena arquitectura de workflows reutilizables, integraciones con proveedores externos, seguridad bien gestionada y monitorización. Una vez montado, el esfuerzo merece la pena: tendrás builds más rápidas, menos errores en producción, despliegues trazables y un proceso de desarrollo mucho más agradable para todo el equipo.

Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.