- Análisis detallado de las métricas de rendimiento de almacenamiento, diferenciando entre IOPS, latencia y tasa de transferencia.
- Metodologías y herramientas avanzadas para el diagnóstico de discos en entornos GNU/Linux y Microsoft Windows.
- Estrategias para identificar cuellos de botella de entrada y salida en sistemas físicos y máquinas virtuales en la nube.

Cuando montamos un PC o configuramos un servidor, solemos obsesionarnos con la velocidad de lectura y escritura secuencial, pero la realidad es que esa cifra es solo la punta del iceberg. Para saber si un disco realmente vuela o si se queda corto, tenemos que mirar bajo el capó y analizar los IOPS y la latencia, que son los valores que determinan cómo se comporta el almacenamiento en el día a día, especialmente con tareas pesadas o bases de datos.
Mucha gente se lleva un chasco al comprar un SSD basándose solo en la publicidad, ya que los fabricantes suelen usar benchmarks sintéticos que no se parecen en nada al uso real. Por eso, es fundamental aprender a usar herramientas de diagnóstico que nos permitan entender si nuestro hardware está rindiendo como debería o si hay algún cuello de botella invisible que nos está ralentizando el sistema.

Conceptos Fundamentales: IOPS, Latencia y Rendimiento
Para no liarnos, empecemos por lo básico. Los IOPS (Input/Output Operations Per Second) representan la cantidad de operaciones de entrada y salida que el disco puede procesar en un solo segundo. Mientras que un disco mecánico antiguo se queda en unos pocos cientos, un SSD moderno puede alcanzar decenas de miles, lo que marca la diferencia al abrir aplicaciones o gestionar miles de archivos pequeños.
Luego tenemos la latencia, que básicamente es el tiempo de respuesta. Es el lapso que transcurre desde que una aplicación pide un dato hasta que el SSD lo entrega. En el mundo de los SSD, buscamos que este valor sea lo más bajo posible, idealmente en el rango de los microsegundos o milisegundos muy bajos, ya que una latencia alta se traduce directamente en micro-tirones o lentitud al responder.
Finalmente, el rendimiento o tasa de transferencia se mide en MB/s o GB/s y se refiere al volumen de datos movidos. Es importante entender que IOPS y rendimiento están ligados por el tamaño del bloque: si mueves bloques muy grandes, los IOPS bajan pero el rendimiento en MB/s sube, mientras que con bloques pequeños ocurre lo contrario.

Herramientas y Métricas en GNU/Linux
En el ecosistema Linux tenemos un arsenal increíble para monitorizar el disco. Una de las herramientas más clásas es iostat, que nos permite ver las transferencias por segundo (tps) y el porcentaje de espera de CPU (%iowait). Ojo con el iowait, porque puede ser traicionero: si cambias la CPU por una más potente, el porcentaje de espera podría subir aunque el disco siga tardando lo mismo, simplemente porque el procesador termina sus tareas más rápido y pasa más tiempo esperando al almacenamiento, algo común al optimizar el rendimiento de Ubuntu.
Para quienes buscan precisión quirúrgica, fio (Flexible IO) es la herramienta reina. Permite simular cargas de trabajo reales, ya sean lecturas aleatorias o escrituras secuenciales, definiendo el tamaño del bloque (por ejemplo, 4k) y la profundidad de la cola. Esto es vital para testear bases de datos, que son extremadamente sensibles a la latencia y requieren que las escrituras se completen en menos de 5 ms.
Si lo que necesitas es algo parecido a un ping pero para el disco, ioping es la opción ideal. Nos permite medir la latencia de I/O en tiempo real sobre un directorio o un dispositivo de bloque, facilitando la detección de picos de retraso sin necesidad de ejecutar benchmarks complejos y prolongados.
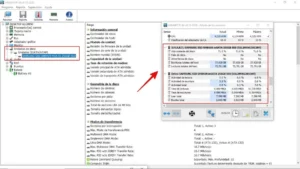
- hdparm: Útil para lecturas rápidas y para desactivar la caché de escritura si queremos medir el rendimiento real del hardware.
- dd: Muy común para pruebas rápidas de escritura, aunque hoy en día se queda corto al ser un proceso de un solo hilo.
- LVM y dmsetup: Imprescindibles para identificar a qué disco físico corresponde cada volumen lógico en configuraciones complejas.
Evaluación de Rendimiento en Windows 11
En Windows, el panorama es diferente pero igual de potente. Para los que prefieren una interfaz visual y no quieren complicarse la vida con la consola, existen gestores de particiones como el software de AOMEI, que incluye un modo sencillo y un modo pro para analizar la velocidad de lectura y escritura de forma intuitiva, permitiendo exportar los resultados en texto o capturas, ideal para quienes buscan optimizar un SSD en Windows 11.
Para los usuarios más avanzados o perfiles técnicos, Microsoft ofrece DiskSpd. Es una herramienta de línea de comandos extremadamente flexible que permite configurar la duración del estrés, el tiempo de calentamiento y el tamaño del archivo de prueba. Al ejecutarlo, podemos analizar la latencia y el rendimiento medio, desactivando la caché de hardware y software para evitar que los resultados estén inflados por la memoria RAM.
Al interpretar los datos de DiskSpd, es clave fijarse en el Total IO y las tablas de latencia. Si vemos que la latencia sube drásticamente al aumentar la profundidad de la cola, significa que el dispositivo está llegando a su límite de saturación, independientemente de que la tasa de transferencia en MB/s parezca aceptable, lo cual podría indicar que es momento de solucionar el uso de disco al 100% en Windows 11.

Diagnóstico de Cuellos de Botella en la Nube (Azure y VMs)
Cuando trabajamos con máquinas virtuales, el rendimiento no solo depende del disco, sino de la SKU de la VM. Es muy común encontrar situaciones donde tenemos un disco ultra rápido (como un SSD Premium), pero la máquina virtual tiene un límite de ancho de banda inferior. En estos casos, el cuello de botella no es el almacenamiento, sino la capacidad de procesamiento de la propia instancia, afectando incluso al rendimiento gráfico en máquinas virtuales.
Para solucionar esto en Linux, se recomienda observar la relación entre la carga promedio y el uso de CPU. Si la carga es alta pero la CPU está descansando, es la señal clara de que los procesos están bloqueados esperando que el disco responda. Herramientas como PerfInsights en Azure ayudan a automatizar este análisis, clasificando los hallazgos según su impacto en el sistema.
Es fundamental establecer una línea de base de rendimiento antes de realizar cambios. Por ejemplo, si redimensionamos una VM de 2 a 8 núcleos y la carga promedio baja drásticamente, confirmamos que el problema era la capacidad de cómputo y no el hardware de almacenamiento. En la nube, la latencia puede variar según el tipo de disco: los Ultra Disk ofrecen latencias de tres dígitos (microsegundos), mientras que los HDD estándar pueden llegar a los dos dígitos en milisegundos.
Tanto en entornos locales como en la nube, la clave está en no confiar en una sola métrica. La combinación de IOPS, tiempo de respuesta y throughput es la única manera de obtener una radiografía real de la salud de nuestro SSD, permitiéndonos optimizar la configuración de aplicaciones críticas como MySQL o MariaDB ajustando, por ejemplo, el tamaño de página de InnoDB para que coincida con el sector del disco.

Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.