- Compatibilidad multilenguaje y formatos de salida para digitalización eficiente.
- Integración sencilla con Python (Pytesseract) y ecosistema .NET.
- IronOCR aporta preprocesado y API de alto nivel sobre Tesseract.
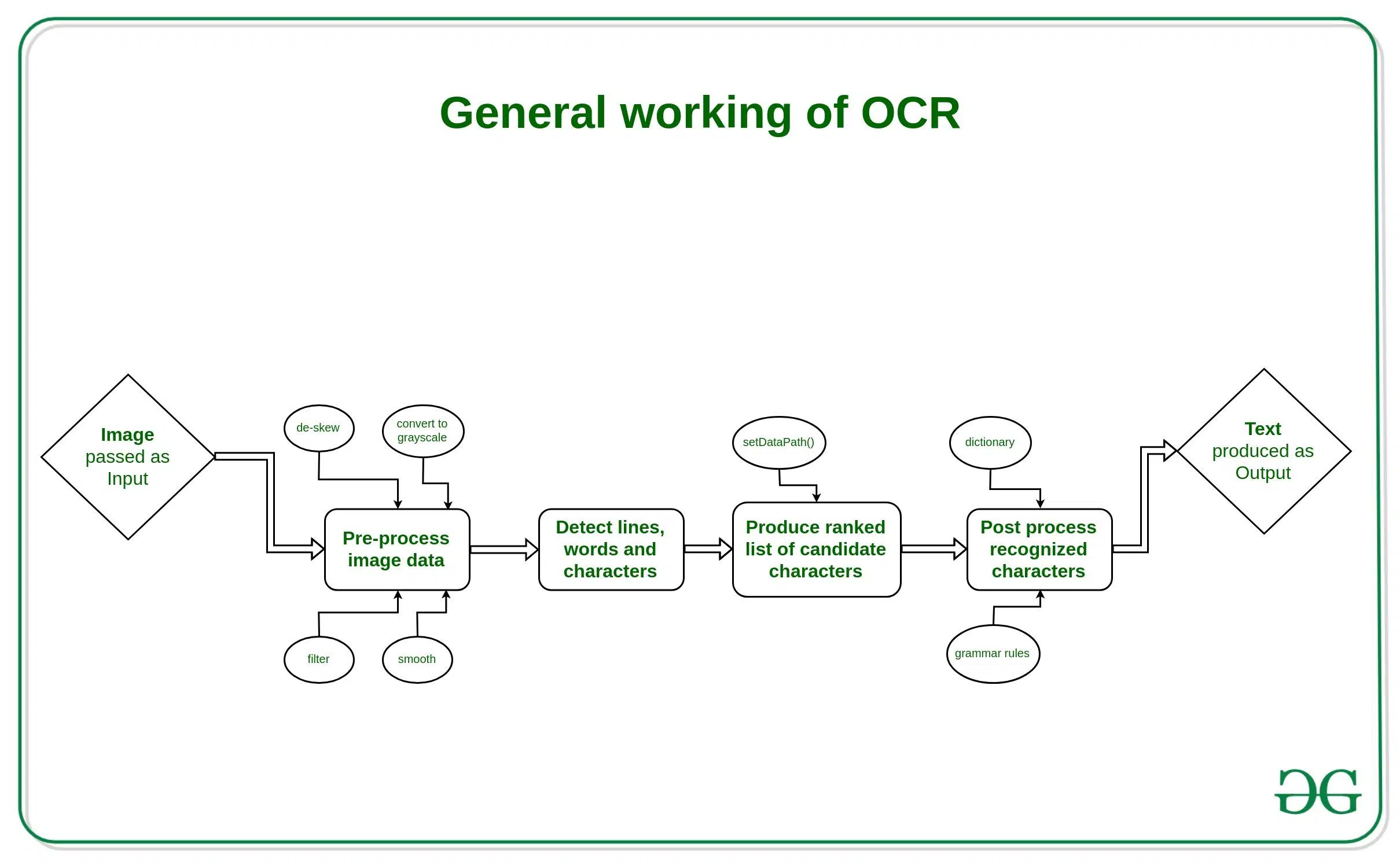
Si te interesa convertir imágenes o PDFs en texto editable sin pelearte con herramientas complejas, o extraer texto de imágenes en Windows 11, la buena noticia es que hoy en día Tesseract OCR es una solución potente, gratuita y muy flexible. En esta guía práctica repasamos qué es, cómo instalarlo en Windows, cómo validarlo desde la consola, y cómo integrarlo tanto con Python (vía Pytesseract) como con .NET, además de una alternativa muy extendida en ese ecosistema: IronOCR.
Más allá de instalar y dar al botón, verás cómo preparar el entorno, dónde añadir la ruta del ejecutable, qué hacer si aparece el típico error TesseractNotFoundError en Python, y cómo procesar textos en varios idiomas (español, inglés, francés, portugués, e incluso paquetes como Math) dentro de aplicaciones. El objetivo es que termines con un flujo de OCR estable y listo para producción, cubriendo desde la línea de comandos hasta el uso en C# con bibliotecas específicas.
¿Qué es Tesseract OCR?
Tesseract es un motor OCR de código abierto, publicado bajo licencia Apache 2.0. Nació en los años 80 en Hewlett‑Packard y hoy lo mantiene la comunidad con un fuerte impulso de Google. Su misión es clara: analizar píxeles de una imagen (TIFF, PNG, JPEG, entre otros) para detectar caracteres, palabras y líneas, y volcar el contenido como texto legible por máquina.
Se puede usar desde la línea de comandos con total libertad, lo que facilita automatizaciones y scripts. Además, admite multitud de idiomas y puede entrenarse para nuevas fuentes o alfabetos, por lo que es habitual en digitalización de documentos, procesamiento de facturas, archivística o accesibilidad.
Descargar e instalar Tesseract en Windows
En Windows, el camino más directo es usar un instalador precompilado. La fuente principal es el repositorio oficial en GitHub (tesseract-ocr/tesseract), donde encontrarás binarios firmados y versiones recientes.
Dentro de los instaladores disponibles, es habitual ver paquetes como tesseract-ocr-w64-setup-5.3.0.20221222.exe (64 bits). Descárgalo y ejecútalo; el asistente te guiará por la configuración paso a paso, incluyendo idioma del instalador y paquetes lingüísticos.
Idioma del instalador y datos de idiomas
Durante la instalación, el wizard te pedirá seleccionar los datos de idioma. Por defecto suele venir inglés, pero puedes añadir paquetes adicionales como español, francés o incluso módulos especializados como Math si los necesitas. Esta selección marca qué modelos se copian al directorio de datos (tessdata).
Licencia, usuarios y componentes
Tesseract se distribuye con Apache License 2.0, así que podrás usarlo y redistribuirlo con flexibilidad. El instalador te pedirá aceptar la licencia, elegir si lo instalas para un solo usuario o para todos, y marcar componentes. Por defecto vienen seleccionados elementos útiles como ScrollView, herramientas de entrenamiento, atajos y datos de idioma.
Ruta de instalación y carpeta del menú Inicio
El asistente te permitirá elegir la carpeta de destino. Anota esa ruta, la necesitarás para la variable de entorno. Después podrás nombrar la carpeta del menú Inicio donde se crean los accesos directos. Al finalizar, pulsa Instalar y, una vez concluya, Finalizar para cerrar.
Añadir Tesseract a la variable de entorno en Windows
Para ejecutar el comando tesseract desde cualquier ventana de cmd o PowerShell, conviene añadir la carpeta de instalación al Path del sistema. Así Windows sabrá dónde encontrar el ejecutable sin rutas absolutas.
Ve al buscador del menú Inicio y escribe “variables de entorno” o “configuración avanzada del sistema”. En la ventana de Propiedades del sistema, entra en la pestaña Avanzadas y pulsa Variables de entorno.
En el bloque Variables del sistema, selecciona Path, clic en Editar y luego en Nuevo. Pega la ruta donde se instaló Tesseract (por ejemplo, C:\Program Files\Tesseract-OCR) y confirma con Aceptar en todas las ventanas.
Comprobar la instalación desde la consola
Abre cmd o PowerShell y ejecuta: tesseract. Si todo está en orden, verás el mensaje de uso, la versión instalada y el listado de opciones admitidas por la utilidad. Este test confirma que el Path está correcto y que el binario responde.
Instalar Tesseract en macOS
En macOS puedes instalar la utilidad desde gestores de paquetes. Con Homebrew, ejecuta brew install tesseract. Si utilizas MacPorts, la orden equivalente es sudo port install tesseract. Ambas rutas descargan y registran el ejecutable para usarlo desde Terminal.
Diferencias entre Tesseract y Pytesseract
Conviene separar conceptos: Tesseract es el motor OCR, el binario que hace el reconocimiento. Pytesseract es un wrapper para Python que llama a ese motor y formatea el resultado para tus scripts. Si vas a trabajar en Python, necesitas tener Tesseract instalado en el sistema y Pytesseract en tu entorno.
Uso básico con Python y solución a TesseractNotFoundError
Uno de los errores más comunes cuando empiezas en Python es TesseractNotFoundError. Sucede cuando Pytesseract no localiza el ejecutable del motor, generalmente porque no está en el Path o la ruta no se ha configurado en el script.
Para evitarlo en Windows, puedes fijar la ruta explícita en tu código señalando el ejecutable. Ejemplo mínimo con Pytesseract:
import pytesseract
from PIL import Image
# Ajusta esta ruta a tu instalación real en Windows
pytesseract.pytesseract.tesseract_cmd = r'C:\\Program Files\\Tesseract-OCR\\tesseract.exe'
texto = pytesseract.image_to_string(Image.open('mi_imagen.png'), lang='spa')
print(texto)Además, asegúrate de que el paquete de idioma que necesitas está disponible (por ejemplo, spa para español). Si no, instala ese traineddata en el directorio tessdata correcto. Con esto se resuelven la mayoría de incidencias al empezar con Python.
OCR en varios idiomas: conceptos y práctica
En proyectos con documentación multilingüe (facturas, contratos o archivos históricos), Tesseract permite combinar idiomas para mejorar la detección cuando conviven textos heterogéneos. La clave es disponer de los archivos .traineddata adecuados dentro de tessdata.
Cuando el contenido mezcla, por ejemplo, inglés, español y francés, puedes indicarlo al motor para que considere simultáneamente varios alfabetos y patrones. Esto también aplica a bibliotecas de más alto nivel como IronOCR en .NET.
Crear un proyecto en Visual Studio y usar Tesseract.NET
Si trabajas en el entorno Microsoft, abre Visual Studio y crea una Aplicación de Consola (o la plantilla que prefieras). Dale nombre al proyecto, elige la versión de .NET y, con la solución creada, ya puedes gestionar paquetes con NuGet.
Instala Tesseract en tu equipo (como hemos explicado) y dentro del proyecto añade el paquete Tesseract o Tesseract.NET desde el Administrador de Paquetes NuGet. Esto añade el wrapper para interactuar con el motor desde C#.
Un ejemplo para leer una imagen con varios idiomas podría tener esta forma, indicando la ruta a tessdata y la lista de idiomas:
using System;
using System.Drawing;
using Tesseract;
class Program
{
static void Main()
{
// Ruta a los archivos de datos de idioma (.traineddata)
string tessDataPath = @"./tessdata";
// Imagen a procesar
string imagePath = @"ruta_a_tu_imagen.png";
using (var img = Pix.LoadFromFile(imagePath))
using (var engine = new TesseractEngine(tessDataPath, "eng+spa+fra", EngineMode.Default))
using (var page = engine.Process(img))
{
string text = page.GetText();
Console.WriteLine("Recognized Text:");
Console.WriteLine(text);
}
}
}Asegúrate de que en la carpeta tessdata existen los .traineddata para cada idioma que declares. Un conjunto habitual para pruebas es eng+spa+fra, pero puedes ampliarlo según tus necesidades.
IronOCR: biblioteca .NET basada en Tesseract
En el ecosistema .NET hay una opción orientada a productividad llamada IronOCR, que se apoya en Tesseract pero ofrece una API de alto nivel, documentación extensa y utilidades de preprocesado. Se instala desde NuGet en Visual Studio con el buscador de paquetes.
Su uso básico para leer el texto de una imagen es muy directo. Ejemplo simple:
using IronOcr;
var ocr = new IronTesseract();
string texto = ocr.Read(@"test-files/redacted-employmentapp.png").Text;
Console.WriteLine(texto);Si prefieres mayor control sobre la entrada (múltiples imágenes, ajustes, etc.), puedes construir un OcrInput y pasarlo al motor. Ejemplo con patrón using:
using IronOcr;
var Ocr = new IronTesseract();
using (var Input = new OcrInput())
{
Input.AddImage("test-files/redacted-employmentapp.png");
var Result = Ocr.Read(Input);
Console.WriteLine(Result.Text);
}Una ventaja clave es que IronOCR admite más de 120 idiomas, integra detección automática y suma utilidades de limpieza de imagen, reducción de ruido o corrección de artefactos que, en la práctica, mejoran la precisión sobre documentos difíciles.
Instalar IronOCR con NuGet y paquetes de idioma
Para añadirlo a tu solución, abre Visual Studio y navega a Herramientas > Administrador de paquetes NuGet > Gestionar paquetes para la solución. Busca “IronOCR” y selecciona el paquete principal. Si vas a trabajar con idiomas adicionales, instala también los paquetes de lenguaje necesarios.
En proyectos multilingües, recuerda que el inglés suele estar disponible por defecto, pero para español o francés deberás añadir sus paquetes. Esto te ahorrará tiempo cuando configures la propiedad Language en el motor.
Leer varios idiomas con IronOCR (C#)
El siguiente ejemplo muestra cómo combinar tres idiomas y procesar una imagen. Es una configuración natural cuando no sabes con certeza el idioma dominante en cada documento:
using IronOcr;
class Program
{
static void Main(string[] args)
{
var Ocr = new IronTesseract();
Ocr.Language = OcrLanguage.English + OcrLanguage.Spanish + OcrLanguage.French;
var inputFile = @"ruta\\a\\tu\\imagen.png";
using (var input = new OcrInput(inputFile))
{
var result = Ocr.Read(input);
Console.WriteLine("Text:");
Console.WriteLine(result.Text);
}
}
}Además de la API sencilla, IronOCR destaca por incluir procesamiento previo de imagen (deskew, binarización, limpieza de bordes), lo que suele traducirse en más aciertos con documentos escaneados o fotos con iluminación irregular.
Ventajas y consideraciones de IronOCR frente a Tesseract “puro”
Mientras Tesseract es libre y extremadamente flexible, IronOCR ofrece una experiencia más directa en .NET, con documentación, ejemplos y funcionalidades listas para empresa. En fuentes corporativas se ha citado una precisión en torno al 99,8% en detección bajo condiciones ideales, además de soporte multihilo y mantenimiento activo.
También es más amable en la integración (apenas configuración, proyectos de ejemplo y APIs cohesivas), con soporte de más de 120 idiomas, incluidos casos complejos y multilenguaje en el mismo documento. En contrapartida, IronOCR es propietario y de pago, con licencias de por vida y opciones de soporte 24/7 para clientes.
Buenas prácticas para mejorar la precisión del OCR
Aunque el motor sea robusto, los resultados dependen mucho de la calidad de las imágenes. Procura usar resoluciones altas, evitar ruido y artefactos, alinear correctamente el documento y mejorar el contraste. Si trabajas con fotos, cuida la iluminación y corrige inclinaciones antes de pasar el OCR.
Con Tesseract “puro” puede ser necesario normalizar las imágenes o aplicar filtros previos para obtener buenos resultados. Herramientas como IronOCR ayudan automatizando gran parte de este preprocesado, lo que simplifica la entrega de textos limpios en escenarios exigentes.
Salida y formatos que puedes generar
Además del texto plano, Tesseract puede producir salidas en HTML/hOCR o PDFs con texto seleccionable. Esto abre la puerta a indexar, buscar y resaltar fragmentos dentro de documentos, o a integrarlos en flujos de archivado digital donde la capacidad de búsqueda sea clave.
Además del texto plano, Tesseract puede producir salidas en HTML/hOCR o PDFs con texto seleccionable, lo que facilita pasar PDF a Word y continuar la edición.
En integraciones personalizadas, puedes postprocesar el resultado, aplicar correcciones ortográficas o modelos NLP para enriquecer entidades, normalizar cifras y preparar el contenido para bases de datos o herramientas analíticas.
Instalación guiada en Windows: puntos finos del asistente
Si quieres un checklist rápido del wizard: elige idioma del instalador, acepta la licencia Apache 2.0, decide si la instalación es para ti o para todos los usuarios, y deja activados los componentes recomendados (ScrollView, herramientas de entrenamiento, accesos directos y datos de idioma).
Selecciona la carpeta de destino (recuerda copiarla para el Path), nombra la carpeta del menú Inicio si procede y pulsa Instalar. Al terminar, valida con “tesseract” en consola para asegurar que todo responde correctamente en tu equipo.
Instalación con paquetes precompilados y elección de idiomas
Cuando descargues desde GitHub, verás varios instaladores y builds para diferentes arquitecturas. Elige el de 64 bits si tu sistema lo soporta. En el asistente podrás marcar idiomas concretos; es buena idea instalar los que vayas a usar (español, portugués, francés, Math, etc.) para evitar búsquedas posteriores.
Si más tarde necesitas ampliar a otros idiomas, podrás añadir sus .traineddata a la carpeta tessdata. La modularidad es uno de los puntos fuertes del motor para adaptarse a distintos dominios.

Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.