- ONNX Runtime ejecuta modelos ONNX con aceleración (TensorRT, OpenVINO, DirectML) en múltiples plataformas.
- Permite inferencia rápida y eficiente en CPU/GPU/NPU, en local, edge y nube con APIs en varios lenguajes.
- Ejemplo práctico: WinUI 3 en Windows con DirectML y ResNet50; también uso sencillo en Python.

La pregunta de moda en desarrollo de IA aplicada es qué papel juega ONNX Runtime al llevar modelos a producción. En pocas palabras, ONNX Runtime es el motor de inferencia optimizado para modelos en formato ONNX, pensado para funcionar en distintos sistemas y sacar partido del hardware disponible (CPU, GPU o NPU). A lo largo de este artículo vas a ver para qué sirve, cómo se usa en Python y .NET, y un ejemplo paso a paso con WinUI 3 en Windows acelerado con DirectML.
Si vienes de entrenar con PyTorch o TensorFlow y quieres un despliegue ágil y eficiente, ONNX te permite exportar el modelo y ONNX Runtime se encarga de ejecutarlo rápido y con bajo consumo de memoria. Privacidad, latencia baja y coste contenido son ventajas claras cuando haces inferencia en local o en el edge sin depender de la nube.
¿Qué es ONNX Runtime?
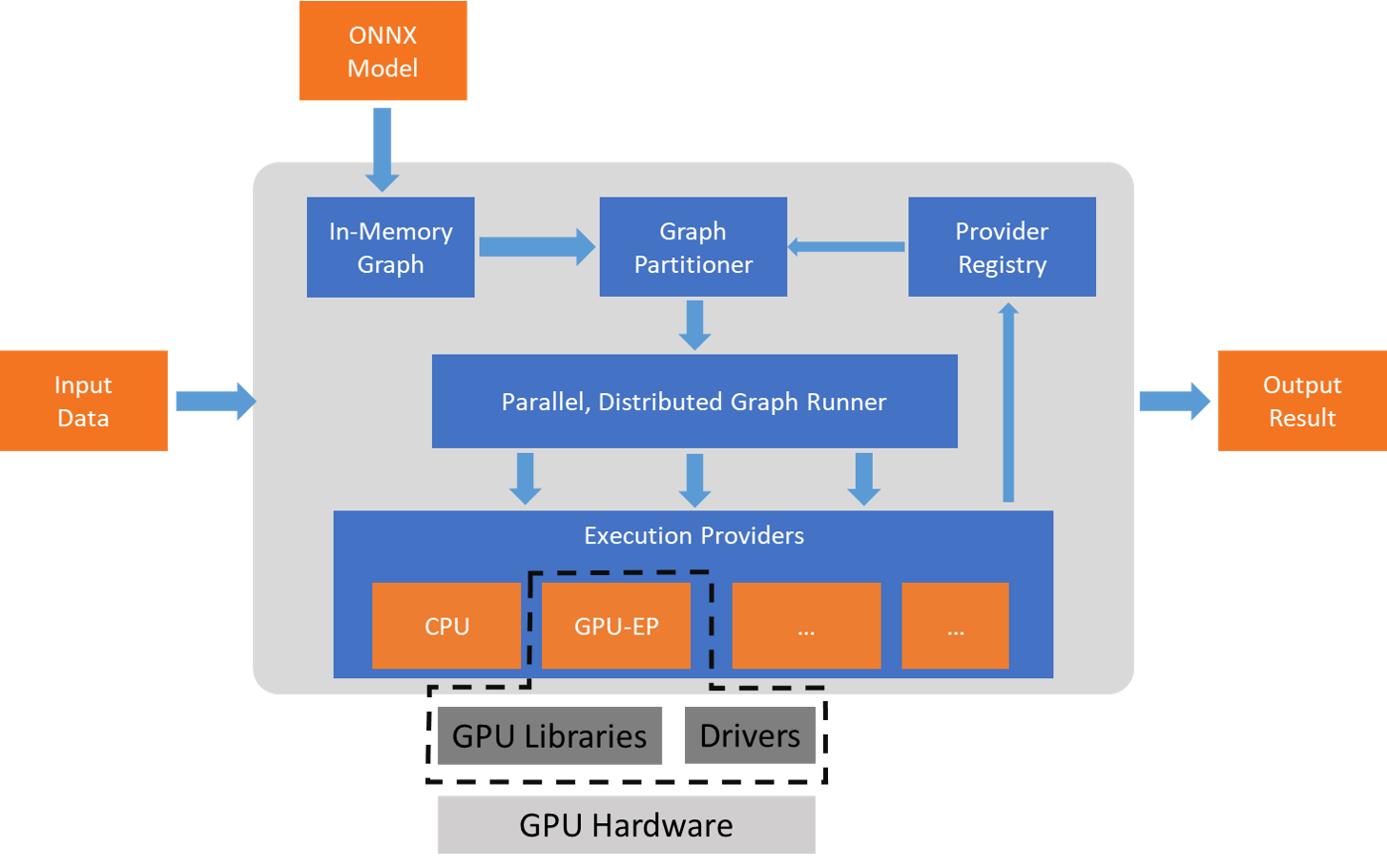
ONNX Runtime es un acelerador de modelos de Machine Learning multiplataforma, con APIs en C, C++, Python, C#, Java y JavaScript (incluido Node.js). Está preparado para Linux, Windows y macOS, y además se integra con web, móvil y entornos perimetrales. Su diseño admite tanto redes neuronales profundas como modelos tradicionales de ML y se puede extender con proveedores de ejecución (Execution Providers) específicos de hardware.
Entre esos proveedores están TensorRT en GPU NVIDIA, OpenVINO en hardware Intel y DirectML en Windows. Esta capa de abstracción permite que el mismo modelo ONNX aproveche la aceleración disponible del dispositivo, manteniendo una interfaz estable. Servicios a gran escala como Bing, Office y Azure AI ya lo usan, con mejoras observadas de hasta 2× en CPU en ciertos escenarios, gracias a optimizaciones de grafos, fusión de operadores y gestión eficiente de memoria.
ONNX: el formato estándar de modelos
ONNX (Open Neural Network Exchange) es un estándar abierto para representar modelos entrenados. Permite exportar desde PyTorch, TensorFlow/Keras, scikit-learn, TFLite, MXNet, Chainer o MATLAB y ejecutar en cualquier parte con motores como ONNX Runtime. Un modelo ONNX incluye la estructura de la red, los pesos entrenados y la descripción de entradas/salidas, lo que habilita la interoperabilidad entre frameworks y hardware.
Este enfoque acelera el paso de investigación a producción: entrenas donde prefieras y despliegas donde más convenga (nube, on-prem, edge). ONNX también facilita optimizar el tamaño y rendimiento mediante técnicas como la cuantificación posterior al entrenamiento, muy útil en dispositivos embebidos o IoT.
Si necesitas inspeccionar un modelo, herramientas como Netron ayudan a visualizar el grafo y las capas. Y si trabajas con detección de objetos, modelos como YOLO de Ultralytics se exportan bien a ONNX para luego ejecutar con ONNX Runtime, OpenVINO u otros motores, ganando portabilidad sin quedar atado a un único ecosistema.
Paquetes y uso de ONNX Runtime en Python
Para Python, ONNX Runtime ofrece paquetes en PyPI tanto para CPU como para GPU. Antes de instalar, revisa los requisitos del sistema para elegir la build correcta. Con pip, la instalación es directa y te permite arrancar rápido con inferencia local o remota.
Instalación rápida:
pip install onnxruntime # build para CPU
pip install onnxruntime-gpu # build con aceleración GPU (según plataforma)Una vez instalado, cargar el modelo y consultar metadatos es sencillo. La sesión de inferencia expone métodos para leer entradas y salidas esperadas, así como metadatos del propio modelo, lo que ayuda a validar formas y tipos antes de invocar session.run.
Ejemplo de sesión:
import onnxruntime as ort
session = ort.InferenceSession("ruta/al/modelo.onnx")
# Metadatos y firmas
meta = session.get_modelmeta()
first_input_name = session.get_inputs().name
first_output_name = session.get_outputs().name
# Inferencia (todas las salidas o sólo algunas)
results_all = session.run([], {first_input_name: indata})
results_some = session.run(, {first_input_name: indata})La documentación que acompaña al modelo suele indicar el preprocesado necesario y los formatos de entrada. Asegúrate de respetar escalados, normalizaciones y dimensiones de tensores, o de lo contrario la inferencia fallará o dará resultados incoherentes.
Ejemplo completo de flujo:
// Selección y visualización
FileOpenPicker picker = new() { ViewMode = PickerViewMode.Thumbnail };
picker.FileTypeFilter.Add(".jpg");
picker.FileTypeFilter.Add(".jpeg");
picker.FileTypeFilter.Add(".png");
picker.FileTypeFilter.Add(".gif");
InitializeWithWindow.Initialize(picker, WinRT.Interop.WindowNative.GetWindowHandle(this));
StorageFile file = await picker.PickSingleFileAsync();
if (file == null) return;
var bitmap = new BitmapImage();
bitmap.SetSource(await file.OpenAsync(Windows.Storage.FileAccessMode.Read));
myImage.Source = bitmap;
// Preprocesado con ImageSharp
using var fileStream = await file.OpenStreamForReadAsync();
IImageFormat format = SixLabors.ImageSharp.Image.DetectFormat(fileStream);
using Image<Rgb24> image = SixLabors.ImageSharp.Image.Load<Rgb24>(fileStream);
image.Mutate(x => x.Resize(new ResizeOptions
{
Size = new SixLabors.ImageSharp.Size(224, 224),
Mode = ResizeMode.Crop
}));
var mean = new[] { 0.485f, 0.456f, 0.406f };
var std = new[] { 0.229f, 0.224f, 0.225f };
DenseTensor<float> input = new(new[] { 1, 3, 224, 224 });
image.ProcessPixelRows(accessor =>
{
for (int y = 0; y < accessor.Height; y++)
{
Span<Rgb24> row = accessor.GetRowSpan(y);
for (int x = 0; x < accessor.Width; x++)
{
input = ((row.R / 255f) - mean) / std;
input = ((row.G / 255f) - mean) / std;
input = ((row.B / 255f) - mean) / std;
}
}
});
// OrtValue desde memoria (evita copias)
using var inputOrt = OrtValue.CreateTensorValueFromMemory(
OrtMemoryInfo.DefaultInstance, input.Buffer, new long[] { 1, 3, 224, 224 });
var inputs = new Dictionary<string, OrtValue> { { "data", inputOrt } };
if (_inferenceSession == null) InitModel();
using var runOptions = new RunOptions();
using var results = _inferenceSession.Run(runOptions, inputs, _inferenceSession.OutputNames);
// Postprocesado: softmax y Top-10
var logits = results.GetTensorDataAsSpan<float>().ToArray();
float sum = logits.Sum(v => (float)Math.Exp(v));
var softmax = logits.Select(v => (float)Math.Exp(v) / sum).ToArray();Los índices de salida corresponden a etiquetas del conjunto de entrenamiento (por ejemplo, ImageNet). Puedes mapearlos con una LabelMap (un array de strings en el mismo orden que las clases del modelo) y extraer el Top 10 con mayor confianza para mostrarlos en el TextBlock.
Postprocesado y etiquetas:
var top10 = softmax
.Select((score, idx) => new Prediction { Label = LabelMap.Labels, Confidence = score })
.OrderByDescending(p => p.Confidence)
.Take(10);
featuresTextBlock.Text = "Top 10 predictions for ResNet50 v2..." + Environment.NewLine;
featuresTextBlock.Text += "-------------------------------------" + Environment.NewLine;
foreach (var p in top10)
{
featuresTextBlock.Text += $"Label: {p.Label}, Confidence: {p.Confidence}" + Environment.NewLine;
}
internal class Prediction
{
public object Label { get; set; }
public float Confidence { get; set; }
}
public static class LabelMap
{
public static readonly string[] Labels = new[]
{
// Lista completa de etiquetas (p.ej., ImageNet) en orden; omitada por brevedad
"tench", "goldfish", "great white shark", /* ... */ "toilet paper"
};
}Con esto, al pulsar «Select photo», el modelo se inicializa (si no lo estaba), se procesa la imagen y aparecen las predicciones más probables con sus confianzas. Este patrón puedes adaptarlo a otros modelos ONNX y tareas (detección, segmentación, texto, etc.).
Ejecución en Azure y MLOps
Si necesitas escalar, Azure Machine Learning permite desplegar modelos ONNX como puntos de conexión REST, gestionando versiones, monitorización y ciclo de vida MLOps. Así puedes llevar a la nube lo que ejecutas en local, manteniendo el mismo artefacto de modelo y beneficiándote de aceleradores en servidor.
El flujo típico es empaquetar inferencia con ONNX Runtime dentro de un contenedor, exponer un endpoint y orquestar actualizaciones, métricas y alertas. Este enfoque unifica desarrollo y operación del modelo a gran escala.
Aceleración y compatibilidad con hardware
ONNX Runtime destaca por su arquitectura de Execution Providers: con TensorRT exprime GPU NVIDIA; con OpenVINO optimiza CPUs/VPUs Intel; y con DirectML acelera en Windows sobre GPUs y NPUs de distintos fabricantes. También existen integraciones con Vitis AI para ejecutar modelos en FPGAs de Xilinx (p.ej., U250), ampliando el alcance a configuraciones especializadas.
Esta flexibilidad facilita que un mismo modelo ONNX rinda bien en cloud, edge, web y móvil, con el motor ajustando operadores y memoria a cada plataforma. El resultado es menor latencia y mejor throughput sin cambiar tu código de alto nivel.
IA en local: privacidad, coste y control
Ejecutar IA en local con ONNX Runtime aporta privacidad (no compartes datos), latencia mínima y coste predecible (sin consumo de API en nube). Es especialmente valioso en sanidad, industria o escenarios con conectividad limitada, y se integra bien con .NET (incluso VB.NET) o Python según tu stack.
Para modelos avanzados, una GPU acelera mucho, pero ONNX Runtime también está optimizado para CPU. La clave es respetar el preprocesado del modelo y, si procede, aplicar cuantificación para reducir tamaño y memoria manteniendo una precisión adecuada.
Conversión y buenas prácticas
Convertir modelos a ONNX desde PyTorch suele hacerse con torch.onnx.export y desde TensorFlow con tf2onnx. Asegura que el tensor de ejemplo (dummy input) tenga la forma correcta y que las operaciones del grafo estén soportadas por el opset objetivo.
Despues de convertir, valida el modelo consultando entradas/salidas con ONNX Runtime y ejecuta casos de prueba. Si hay capas personalizadas, puede que necesites adaptaciones o sustituir por operadores soportados; la compatibilidad entre opsets y versiones es importante para evitar sorpresas.
Aplicaciones y casos de uso
En visión por computador, ONNX facilita clasificación, detección y segmentación en dispositivos diversos, desde servidores hasta edge e IoT. La reducción de tamaño mediante cuantificación y las optimizaciones de inferencia lo hacen ideal para tiempo real (p. ej., robots de fábrica o inspección de calidad).
En sanidad, modelos ONNX en wearables y sistemas de monitorización pueden preprocesar señales (como ECG) y extraer características en local, preservando privacidad. Para ciudades inteligentes, cámaras con ONNX identifican vehículos en tiempo real sin depender de la nube, optimizando tráfico y recursos.
Recursos y contenidos destacados
ONNX Runtime impulsa la IA en Windows, Office, Azure Cognitive Services y Bing, y en miles de proyectos globales. Hay materiales divulgativos que profundizan en ONNX, su relación con opsets, aceleración por hardware y casos reales como la búsqueda semántica de imágenes de Bing.
Un ejemplo de programa divulgativo marca estos hitos: Presentación de ONNX, Introducción a ONNX, Demostración: conversión desde CoreML, ONNX Runtime, Versiones y opsets, Aceleración de hardware, Caso práctico. Este tipo de contenidos ilustra cómo pasar de modelo a despliegue optimizado.
Para descargar modelos listos, el ONNX Model Zoo ofrece clasificadores de imagen, detectores y modelos de NLP. Si algo no convierte a la primera, suele ser útil abrir incidencia en el repositorio del convertidor correspondiente y revisar las operaciones no soportadas.
Como nota final, también existen integraciones específicas como la de Vitis AI (Xilinx) con ONNX Runtime para FPGAs U250, ampliando el abanico de despliegue en hardware programable para casos de alto rendimiento y baja latencia.
ONNX Runtime se ha posicionado como una pieza clave para ejecutar modelos de IA con rapidez, versatilidad y eficiencia en casi cualquier entorno. Si trabajas con Python o .NET, en local o en Azure, y necesitas compatibilidad con CPU, GPU, NPU o incluso FPGA, la combinación ONNX + ONNX Runtime te permite entrenar donde quieras y desplegar donde más convenga, con un camino de optimizaciones probado en producción y una comunidad activa que impulsa su evolución.

Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.