- Selecciona la estrategia según tu objetivo: mostrar únicos, resumir o eliminar.
- Access facilita la detección con asistente; SQL aporta control total.
- Para datos con variaciones, la deduplicación difusa mejora la precisión.
- Antes de borrar, verifica y respáldate para evitar pérdidas irreversibles.

Si trabajas con bases de datos de Microsoft Access, tarde o temprano te toparás con registros repetidos. Estos duplicados aparecen cuando varios usuarios introducen datos a la vez o cuando el diseño, por ejemplo una correcta relación entre tablas en Access, no impide repeticiones. Entender cómo detectarlos y qué hacer con ellos (ocultarlos, mostrarlos una sola vez, consolidarlos o borrarlos) es clave para mantener la calidad de la información.
No existe un único método universal: depende de si buscas duplicados exactos, si necesitas tolerancia a errores (nombres con faltas o variantes), o si lo que quieres es limpiar la tabla de forma segura. Access ofrece un asistente para encontrar duplicados, consultas SQL como DISTINCT y GROUP BY, y la posibilidad de eliminar en bloque con consultas de eliminación. Para casos complicados, hay herramientas especializadas de deduplicación con búsqueda difusa.
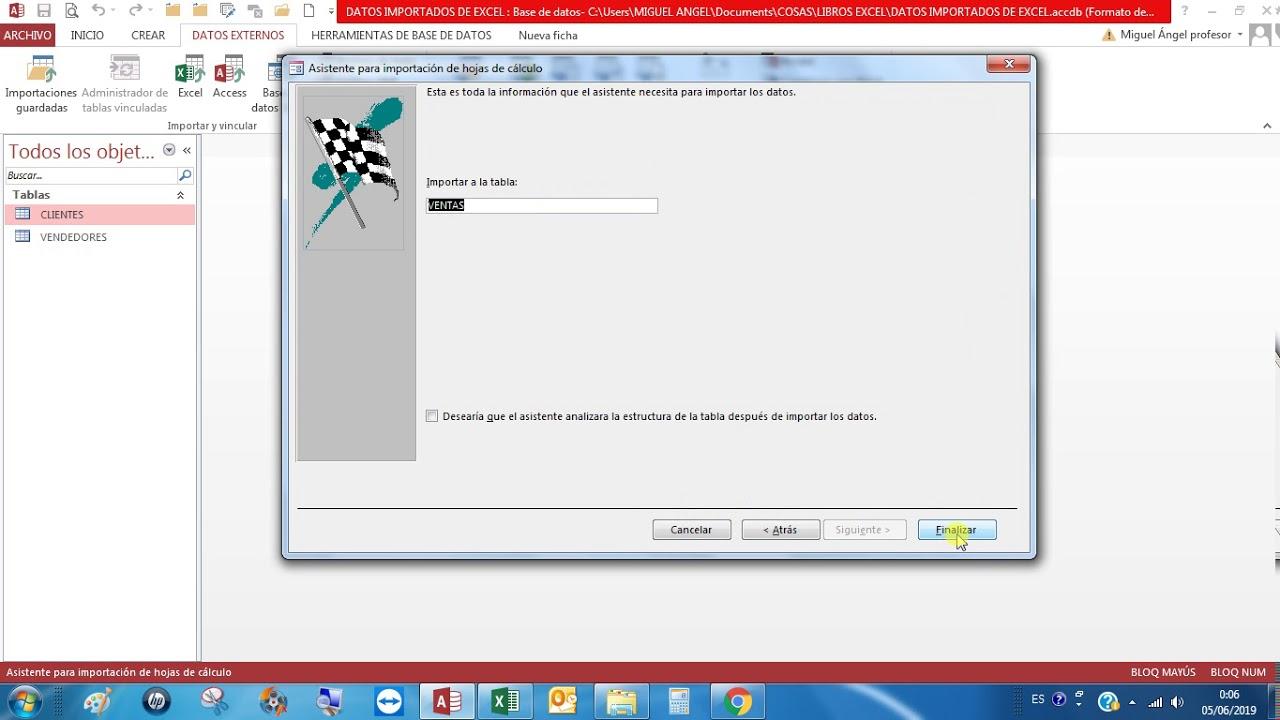
Localizar duplicados con el Asistente de Access
La vía más directa para usuarios de Access es el Asistente para consultas de duplicados. Este asistente genera por ti una consulta de selección que identifica registros con valores coincidentes en los campos que elijas, de modo que puedes revisar el resultado antes de tomar decisiones.
Cómo lanzarlo y configurarlo paso a paso, sin tecnicismos innecesarios: abre la pestaña Crear y entra en Asistente para consultas. En el cuadro de diálogo, elige Asistente para consultas de buscar duplicados y confirma para continuar.
A continuación, selecciona la tabla (o consulta) donde sospechas duplicados, por ejemplo una tabla en Access creada y pulsa Siguiente. El asistente te pedirá los campos que deben coincidir entre sí para considerar que un registro está repetido; por ejemplo, nombre y fecha de nacimiento en un fichero de personas, o número de cliente en una tabla de pedidos.
Podrás además elegir campos adicionales que quieras ver en la salida (no influyen en la comparación, pero te ayudan a inspeccionar los resultados). Para terminar, Access te propondrá un nombre de consulta o podrás fijar el tuyo; pulsa Finalizar para ejecutarla y revisar el listado de coincidencias.
Una vez tengas la consulta de duplicados, puedes usarla como base para editar, consolidar o eliminar. Si lo que buscas es cruzar varias tablas y detectar duplicados entre ellas, crea antes una consulta de unión que combine los datos y, sobre ese resultado, ejecuta de nuevo la búsqueda de duplicados.
SQL en Access: mostrar, ocultar o depurar duplicados
Cuando necesitas más control (o automatizar), las consultas SQL de Access son tus aliadas, por ejemplo al actualizar registros en Access. Con unas pocas sentencias puedes listar solo valores únicos, resumir repeticiones o identificar las filas que sobran para tratarlas. Veamos los casos más habituales.
Mostrar cada combinación única una sola vez con DISTINCT. Útil para informes donde no quieres ver repeticiones idénticas de un valor, por ejemplo, la lista de artículos distintos pedidos por cada cliente:
SELECT DISTINCT customer_id, article_no FROM customer_articles ORDER BY customer_id, article_no;
Si además quieres generar una tabla limpia sin duplicados, combínalo con INTO para crear una nueva tabla a partir del resultado:
SELECT DISTINCT customer_id, article_no INTO table_new FROM customer_articles ORDER BY customer_id, article_no;
Resumir y “ocultar” duplicados con GROUP BY. Cuando tu objetivo es agrupar y obtener métricas (conteo de repeticiones, sumas, etc. y campos calculados en Access), tira de GROUP BY. Por ejemplo, cuántas veces se ha vendido cada artículo y el total de ingresos asociado:
SELECT article_no, COUNT(*) AS veces, SUM(revenue) AS ingresos FROM invoice_articles GROUP BY article_no ORDER BY veces DESC, article_no;
Detectar duplicados exactos por comparación de filas. Si necesitas identificar pares o grupos de registros que comparten el mismo valor en uno o varios campos y preparar su eliminación, puedes usar un auto-join (autounión) de la tabla contra sí misma, cuidando de no emparejar una fila consigo misma:
SELECT t1.id, t1.name, t2.id AS id_duplicado, t2.name AS name_duplicado
FROM tablename AS t1, tablename AS t2
WHERE t1.name = t2.name
AND t1.id <> t2.id
AND t1.id = (
SELECT MAX(id)
FROM tablename AS tx
WHERE tx.name = t1.name
);
Observa dos detalles: hace falta una clave (id) que identifique de forma única cada fila y se usa MAX(id) para fijar cuál es el registro “principal” de cada grupo; los demás se consideran candidatos a borrado.
Eliminar duplicados exactos. Con el patrón anterior, puedes encapsular la lista de ids sobrantes en un DELETE y así limpiar dejando solo una fila por grupo:
DELETE FROM tablename
WHERE id IN (
SELECT t2.id
FROM tablename AS t1, tablename AS t2
WHERE t1.name = t2.name
AND t1.id <> t2.id
AND t1.id = (
SELECT MAX(id)
FROM tablename AS tx
WHERE tx.name = t1.name
)
);
Este enfoque es fácilmente extensible para comparar varios campos a la vez (por ejemplo, nombre, calle, código postal). Ten siempre una copia de seguridad antes de ejecutar un DELETE; más abajo verás un checklist de seguridad y cómo convertir una consulta en consulta de eliminación desde la vista de diseño.
¿Duplicados entre tablas diferentes? Si tus datos están dispersos en varias tablas o proceden de Excel, importar datos desde Excel a Access y crear primero una consulta de unión que apile filas “compatibles” es una buena práctica: podrás aplicar DISTINCT, GROUP BY o el auto-join sobre la unión resultante para descubrir solapamientos.
Duplicados difíciles: deduplicación “inteligente” con tolerancia a errores
La vida real no siempre trae duplicados exactos: hay tildes, abreviaturas, espacios de más, calles escritas de mil formas… En esos casos, necesitas una búsqueda difusa (aproximada) que acepte coincidencias parciales. Access, de serie, no trae un motor de similitud robusto; aquí entran en juego herramientas de deduplicación especializadas, como DataQualityTools.
¿Qué aportan estas herramientas? Encuentran registros que “se parecen” lo suficiente desde varios criterios (por ejemplo, nombre + dirección), permiten fijar umbrales de similitud (p. ej., 50% para la calle) y combinar campos en bloques lógicos para compararlos de forma conjunta.
Flujo típico de trabajo con una utilidad de deduplicación difusa: instala la herramienta, crea un proyecto de deduplicación dentro del bloque de funciones de “deduplicación en una tabla” y abre tu archivo de Access (o conéctate si está en un servidor). Después selecciona la base de datos y la tabla objetivo desde los desplegables de la propia herramienta.
Llega el punto clave: indicar qué columnas se comparan y cómo. En listas de direcciones, por ejemplo, puedes mapear el campo de la calle como “Street” y fijar un umbral del 50% para que solo se consideren duplicados aquellas filas donde la similitud del nombre de la vía supere esa marca. También es frecuente agrupar varias columnas (como “Nombre” + “Apellidos” + “Empresa”) para que se comparen en conjunto antes de decidir si dos registros pertenecen a la misma persona o entidad.
Tras configurar opciones avanzadas (si hacen falta), inicia la búsqueda. El resultado suele mostrarse en una tabla con los grupos detectados y una propuesta de acciones: qué filas conservar, cuáles marcar, cuáles fusionar o borrar. Las herramientas permiten rectificar la selección (por ejemplo, desmarcar una fila que no quieres eliminar) antes de exportar o aplicar cambios.
¿Cómo llevar el resultado a Access? Opciones habituales: marcar los registros elegidos con una “marca de borrado” en un campo específico de tu tabla o exportar un listado de ids. Después, en Access, ejecutas una consulta de eliminación filtrando por ese campo o por los ids marcados. Muchas herramientas ofrecen periodos de prueba para que valides la calidad de la deduplicación en tus propios datos.
Eliminar con garantías: checklist previo, consulta de eliminación y caso práctico
Antes de borrar nada conviene prepararse. Las eliminaciones no se pueden deshacer, y si hay relaciones con integridad referencial podrías borrar más de lo previsto. Revisa este checklist rápido.
– Comprueba que el archivo .accdb no es de solo lectura.
– Si se comparte, pide a otros usuarios que cierren los objetos con los que vas a trabajar para evitar bloqueos y conflictos.
– Si tienes permisos, abre la base en modo exclusivo (Archivo > Abrir > flecha junto a Abrir > Abrir en modo exclusivo).
– Haz una copia de seguridad. Es la única forma real de recuperar filas si algo sale mal.
¿Cómo crear y ejecutar una consulta de eliminación desde la vista de diseño de Access? La receta es sencilla: primero construye una consulta de selección que devuelva exactamente lo que pretendes borrar y verifícala; luego conviértela en eliminación.
Pasos guiados: en la pestaña Crear, entra en Diseño de consulta y añade la tabla afectada. Haz doble clic en el asterisco (*) si quieres ver todos los campos, y añade a la cuadrícula aquellos por los que filtrarás (por ejemplo, IdCliente y FechaPedido para localizar pedidos pendientes de un cliente que ya no está).
Introduce los criterios que correspondan (el id del cliente, fechas posteriores a cierto día, etc.) y desmarca “Mostrar” en esos campos de criterio para mantener limpia la vista. Pulsa Ejecutar para comprobar que aparecen solo los registros que quieres eliminar.
Cuando lo tengas claro, vuelve a Vista Diseño y en la pestaña Diseño pulsa Eliminar. Access convertirá la consulta en una “consulta de eliminación”: ocultará la fila Mostrar y añadirá la fila Eliminar, donde verás “De” bajo la columna del asterisco (*) y “Dónde” bajo las columnas con criterios. Ejecuta de nuevo y confirma.
Consejo adicional: si estás comparando tablas o buscando registros en una tabla que no tienen correspondencia en otra (lo contrario de un duplicado), Access dispone de asistentes para comparar y localizar elementos sin coincidencia. Es útil en tareas de conciliación de datos.
Caso práctico: “solo quiero valores únicos de un campo”. En un hilo típico aparece este problema: un usuario escribe SELECT DISTINCT IdOperador FROM TRegO WHERE IdOperador IS NOT NULL y obtiene 105 filas únicas, pero al añadir otros campos (CIF, Nombre) el resultado sube (107, 116…) porque DISTINCT se aplica a todas las columnas del SELECT. La explicación es simple: si agregas más columnas, la combinación completa debe ser única, así que dejan de agruparse como duplicadas aquellas filas que difieren en Nombre (por una coma, un espacio extra, etc.).
Soluciones claras según lo que necesites ver en pantalla: si solo quieres la lista de IdOperador únicos, mantén solo ese campo en el SELECT con DISTINCT. Si además quieres mostrar otra columna “representativa” de cada IdOperador, usa una estrategia de una fila por grupo:
-- 1) Elegir una fila estable por grupo (por ejemplo, la de mayor Id)
SELECT t.*
FROM TRegO AS t
INNER JOIN (
SELECT IdOperador, MAX(Id) AS IdMax
FROM TRegO
WHERE IdOperador IS NOT NULL
GROUP BY IdOperador
) AS g
ON t.IdOperador = g.IdOperador AND t.Id = g.IdMax;
-- 2) O devolver agregados por grupo (el primer o el menor valor alfabético)
SELECT IdOperador,
MIN(Nombre) AS NombreEjemplo,
MIN(CIF) AS CIFEjemplo
FROM TRegO
WHERE IdOperador IS NOT NULL
GROUP BY IdOperador;
La primera opción devuelve una fila completa “canónica” por IdOperador (la de Id más alto); la segunda ofrece valores agregados por grupo (por ejemplo, el alfabéticamente menor). Evita mezclar DISTINCT con columnas adicionales si lo que necesitas es una única fila por clave; optar por GROUP BY o por un subselect con MAX/MIN te dará el control que buscas.
Si la fase final es eliminar duplicados dejando una sola fila por IdOperador, combina el patrón anterior con una consulta de eliminación: identifica primero qué Id de cada grupo deseas conservar (MAX(Id) o MIN(Id)) y borra el resto con un DELETE…WHERE Id NOT IN (… conservados …), siempre con copia de seguridad previa.
A la hora de combatir duplicados en Access, conviene tener claro el objetivo: no es lo mismo “no mostrar repetidos” que “borrar registros” o “encontrar similitudes aproximadas”. El asistente acelera la detección inicial, SQL te da precisión quirúrgica (DISTINCT, GROUP BY, autouniones y DELETE), y para casos complejos con direcciones y nombres conviene una deduplicación difusa apoyada en herramientas especializadas. Con copia de seguridad, pruebas previas y un diseño de consultas cuidadoso, la limpieza de datos se vuelve un proceso fiable y repetible.

Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.