- gdbserver actúa como agente remoto de GDB para controlar procesos en otra máquina vía TCP o serie.
- Para depurar en remoto es clave compilar con símbolos, usar el gdb adecuado y configurar bien rutas de símbolos y fuentes.
- gdbserver ofrece modo proceso único y modo multi, integrándose también con WinDbg y con QEMU para depurar kernels.
- Opciones como --debug, sysroot y límites de tamaño de valores ayudan a diagnosticar problemas y estabilizar las sesiones.
Si programas en C o C++ en Linux y nunca has tocado gdbserver, estás dejando pasar una de las herramientas más útiles para depurar procesos en remoto, ya sea en un servidor, en un sistema embebido o incluso dentro de una máquina virtual o WSL. Lejos de ser algo “mágico” o reservado a expertos, gdbserver es simplemente un pequeño programa que se encarga de hablar con gdb y controlar la ejecución del proceso objetivo.
La idea clave es muy sencilla: en la máquina donde se ejecuta el binario que quieres depurar (el target) arrancas gdbserver; en tu equipo de trabajo (el host) arrancas gdb o incluso WinDbg con soporte para el protocolo gdb. Ambos se conectan por TCP o por un puerto serie y a partir de ahí puedes establecer puntos de ruptura, inspeccionar variables, ver la pila o seguir la ejecución paso a paso como si el programa estuviera corriendo en tu propia máquina.
Qué es gdbserver y cuándo tiene sentido usarlo
gdbserver es un “agente” de depuración remota para GNU gdb. Su función es muy concreta: se ejecuta en la máquina donde corre el programa a analizar, controla ese proceso (o procesos) y se comunica con un cliente gdb situado en otra máquina (o en la misma) a través de una conexión remota.
En el día a día, gdbserver se usa en dos escenarios típicos: depurar software que corre en entornos embebidos (routers, placas con Linux recortado, dispositivos IoT, etc.) y depurar procesos en máquinas Linux remotas, donde no es cómodo o directamente no es posible tener gdb “gordo” con todas las librerías y símbolos.
A nivel práctico, gdbserver se ocupa de tareas como leer y escribir registros y memoria del proceso, controlar la ejecución (continuar, pausar, paso a paso), gestionar puntos de ruptura y enviar todos esos datos a gdb mediante el protocolo remoto de GDB. Esta filosofía es muy parecida a la de herramientas como OpenOCD, que hacen de puente entre gdb y un hardware externo, con la diferencia de que gdbserver se ejecuta en el propio sistema donde corre el binario.
Si vienes de entornos Windows también es interesante saber que depuradores como WinDbg pueden hablar con un gdbserver en Linux, de modo que puedes depurar procesos de usuario en Linux desde WinDbg usando el soporte de depuración remota vía protocolo gdb que Microsoft ha incorporado en versiones recientes.
Requisitos básicos para depurar con gdb y gdbserver
Antes de lanzarte a depurar en remoto necesitas tener claro el binomio host/target. El target es la máquina donde corre el programa a depurar y donde se ejecutará gdbserver; el host es la máquina desde la que vas a manejar gdb (o WinDbg) y donde tendrás el código fuente y, preferiblemente, los símbolos de depuración.
El punto de partida imprescindible es compilar el binario con símbolos. En GCC o g++ esto se consigue con el flag -g, y suele ser recomendable además desactivar optimizaciones (por ejemplo con -O0) para que el depurador pueda mostrar variables, macros y estructura del código de manera más fiel. Para macros concretas puedes usar niveles de depuración más altos, como -g3.
En el lado del host necesitarás una versión de gdb compatible con la arquitectura objetivo. Para depurar un sistema embebido MIPS, ARM u otra arquitectura, hay que usar el gdb de la toolchain cruzada correspondiente (por ejemplo arm-none-eabi-gdb o gdb-multiarch) y, si hace falta, configurar la arquitectura y endianness con comandos como set arch y set endian.
En cuanto a la conexión, gdbserver admite dos tipos principales: un enlace serie (muy habitual en hardware embebido, a través de UART) y TCP/IP, que es lo más cómodo cuando el target está en la misma red o es una máquina Linux accesible por red. En ambos casos, desde gdb se usa el comando target remote para conectarse al endpoint exposado por gdbserver.
Formas de arrancar gdbserver: proceso único y modo multi
gdbserver puede funcionar de dos maneras principales cuando hablamos de depuración en modo usuario: asociado directamente a un solo proceso o como un “servidor de procesos” que permite listar y adjuntar a diferentes procesos del sistema.
En el modo de un solo proceso lanzas gdbserver indicando el host:puerto y el programa a ejecutar. En un ejemplo sencillo en una máquina Linux de escritorio podrías hacer algo así:
Comando: gdbserver localhost:3333 foo
Con ese comando gdbserver arranca el binario foo y se queda escuchando en el puerto 3333. Hasta que no se conecta un gdb remoto, el programa permanece detenido; cuando gdb se conecta con target remote localhost:3333, el proceso empieza a ser controlado por el depurador.
En el modo multi-proceso (servidor de procesos) se utiliza la opción --multi. En este caso, gdbserver no lanza directamente ningún programa, sino que se limita a escuchar conexiones entrantes y permite que el cliente (gdb o WinDbg) gestione qué proceso crear o a cuál adjuntarse:
Comando: gdbserver --multi localhost:1234
Cuando se trabaja con WinDbg en Linux, este modo multi es especialmente interesante, porque desde el propio WinDbg se puede listar procesos del sistema remoto, ver PID, usuario y línea de comandos, y adjuntar al que interese, de forma parecida a como se hace con el servidor de procesos dbgsrv.exe en Windows.
Depuración remota con gdbserver y gdb paso a paso
Vamos a bajar esto a tierra con un ejemplo muy típico: depurar una aplicación sencilla en la misma máquina (host y target coinciden) usando gdbserver para simular el escenario remoto.
Primero escribes y compilas un pequeño programa, por ejemplo un bucle tonto que imprime un contador:
Comando: gcc -g foo.c -o foo
La clave aquí es el flag -g, que mete en el binario la información de depuración necesaria para que gdb pueda mostrar líneas de código, nombres de variables, tipos, etc. En un entorno “real” de cross-compiling, esta compilación la harías con la toolchain cruzada y luego copiarías tanto el binario como sus dependencias al target.
El siguiente paso es arrancar gdbserver en el target. Si host y target son la misma máquina, basta con:
Comando: gdbserver localhost:3333 foo
Verás un mensaje similar a “Process foo created; pid = XXXX; Listening on port 3333”. Eso indica que gdbserver ha creado el proceso y está esperando que gdb se conecte. Si estás en un sistema donde se requiere más privilegios (por ejemplo para adjuntar a procesos del sistema), puede que necesites lanzar el comando con sudo, pero siempre conviene ser prudente con dar permisos de root al depurador.
En el host, inicias gdb indicando el ejecutable local (el mismo que se está ejecutando en el target, o una copia idéntica con símbolos):
Comando: gdb foo
Ya dentro de gdb, estableces la conexión remota con:
Comando: target remote localhost:3333
En ese momento, gdb carga los símbolos del binario local, se sincroniza con gdbserver y pasa a controlar el proceso que está realmente corriendo bajo gdbserver. A partir de ahí el flujo es el habitual: comandos como break para poner puntos de ruptura, continue, step, next, print para inspeccionar variables, backtrace para ver la pila, etc.
Conexión a procesos ya en ejecución con gdbserver
No siempre quieres lanzar el programa desde cero; muchas veces te interesa adjuntarte a un proceso que ya está corriendo (por ejemplo un httpd de un router, un demonio del sistema o un servicio en producción).
El patrón típico es usar la opción --attach de gdbserver, pasando el puerto donde escuchará y el PID del proceso objetivo. Por ejemplo, en un router donde has copiado un gdbserver compilado para su arquitectura podrías hacer:
Comando: gdbserver localhost:3333 --attach <pid_de_httpd>
En el lado del host usarás una versión de gdb que soporte la arquitectura del router, por ejemplo gdb-multiarch, configurando antes la arquitectura y el endianness:
Comando: set arch mips
set endian big
Después indicas el archivo local que contiene los símbolos del binario remoto (por ejemplo file httpd) y, si es necesario, le dices a gdb dónde se ejecuta realmente el binario en el target con set remote exec-file /usr/bin/httpd. Finalmente, igual que antes, conectas con:
Comando: target remote 192.168.0.1:3333
Una vez adjuntado, puedes poner puntos de ruptura en funciones concretas (por ejemplo break checkFirmware), continuar la ejecución y dejar que el flujo normal del programa (subir un firmware desde la interfaz web, por ejemplo) dispare el punto de ruptura.
Uso de gdbserver con WinDbg en Linux
En los últimos años Microsoft ha añadido soporte para depuración de procesos Linux en WinDbg usando precisamente gdbserver como backend. Esta funcionalidad está pensada para escenarios donde trabajas en Windows pero el código corre en Linux (incluyendo WSL).
Para depurar un proceso Linux concreto con WinDbg usando gdbserver, el flujo sería algo así: primero localizas el proceso objetivo en la máquina Linux con un comando como ps -A (por ejemplo un python3 que está corriendo), luego lanzas gdbserver en el target:
Comando: gdbserver localhost:1234 python3
Si el entorno lo requiere, quizá tengas que usar sudo gdbserver ..., con las mismas precauciones de seguridad de siempre. Una vez que gdbserver indica que está “Listening on port 1234”, en WinDbg vas a “Archivo / Conectar al depurador remoto” y especificas una cadena de conexión de tipo:
Comando: gdb:server=localhost,port=1234
WinDbg usa un pequeño “driver” de protocolo gdb para hablar con gdbserver y, una vez establecida la conexión, se queda detenido en el punto de arranque del proceso. Desde ahí puedes usar sus ventanas de pila, módulos, memoria, puntos de ruptura, así como comandos como k para ver la pila o lm para listar módulos (teniendo en cuenta que algunos comandos esperan formato PE y no ELF, por lo que pueden mostrar datos raros en ciertos casos).
Servidor de procesos gdbserver y WinDbg
Además del caso de proceso único, WinDbg puede conectarse a un gdbserver que actúe como servidor de procesos para trabajar de forma más parecida a como lo hace con procesos Windows remotos. En este modo, gdbserver se lanza con --multi y sin proceso asociado:
Comando: sudo gdbserver --multi localhost:1234
Desde WinDbg eliges “Archivo / Conectar al servidor de procesos” y vuelves a usar la cadena de conexión gdb:server=localhost,port=1234. Cuando la conexión está activa, puedes listar los procesos Linux disponibles y adjuntarte al que quieras o incluso lanzar un nuevo proceso.
Hay que tener presente un detalle sutil: WinDbg distingue entre “servidor de procesos” y “destino único” en función de si gdbserver está ya asociado a un proceso cuando se conecta. Si dejaste gdbserver adjuntado a un proceso, cerraste WinDbg y luego intentas reconectar, es posible que no lo detecte como servidor de procesos y tengas que reiniciar gdbserver.
Para finalizar una sesión servidores de procesos, suele bastar con pulsar CTRL+D en la consola donde corre gdbserver y detener la depuración desde WinDbg. En algunos casos extremos, si hay problemas de sincronización, puede hacer falta cerrar completamente el depurador y relanzar gdbserver desde cero.
Gestión de símbolos y código fuente en depuración remota
Una de las claves para que la depuración remota sea cómoda es tener bien resuelta la parte de símbolos y fuentes. Sin símbolos, navegar por la pila o poner puntos de ruptura en funciones concretas se convierte en una tortura.
En escenarios gdb + gdbserver clásicos, lo ideal es conservar en el host una copia del ejecutable con símbolos (no strippeado) y el árbol de fuentes. gdb no necesita que el binario remoto contenga los símbolos; basta con que el archivo local que cargues con file coincida con el ejecutable remoto a nivel de offsets.
En el mundo WinDbg y depuración de Linux han aparecido además servicios como DebugInfoD, que exponen símbolos y fuentes a través de HTTP. WinDbg puede usar rutas especiales del tipo DebugInfoD*https://debuginfod.elfutils.org tanto en .sympath como en .srcpath para descargar bajo demanda símbolos DWARF y código fuente de binarios ELF de Linux.
En un ejemplo concreto con WSL, donde el código de usuario está bajo C:\Users\Bob\, podrías decirle a WinDbg:
Comando: .sympath C:\Users\Bob\
.srcpath C:\Users\Bob\
Y si además quieres tirar de DebugInfoD para binarios del sistema:
Comando: .sympath+ DebugInfoD*https://debuginfod.elfutils.org
.srcpath+ DebugInfoD*https://debuginfod.elfutils.org
Con esta configuración, cuando inspecciones la pila o entres en funciones de la libc, WinDbg podrá intentar descargar los símbolos DWARF correspondientes y, si el servidor también expone el código, mostrar el fuente con bastante detalle, aunque internamente la cadena de herramientas de Windows no trate ELF y DWARF de forma tan “nativa” como PE y PDB.
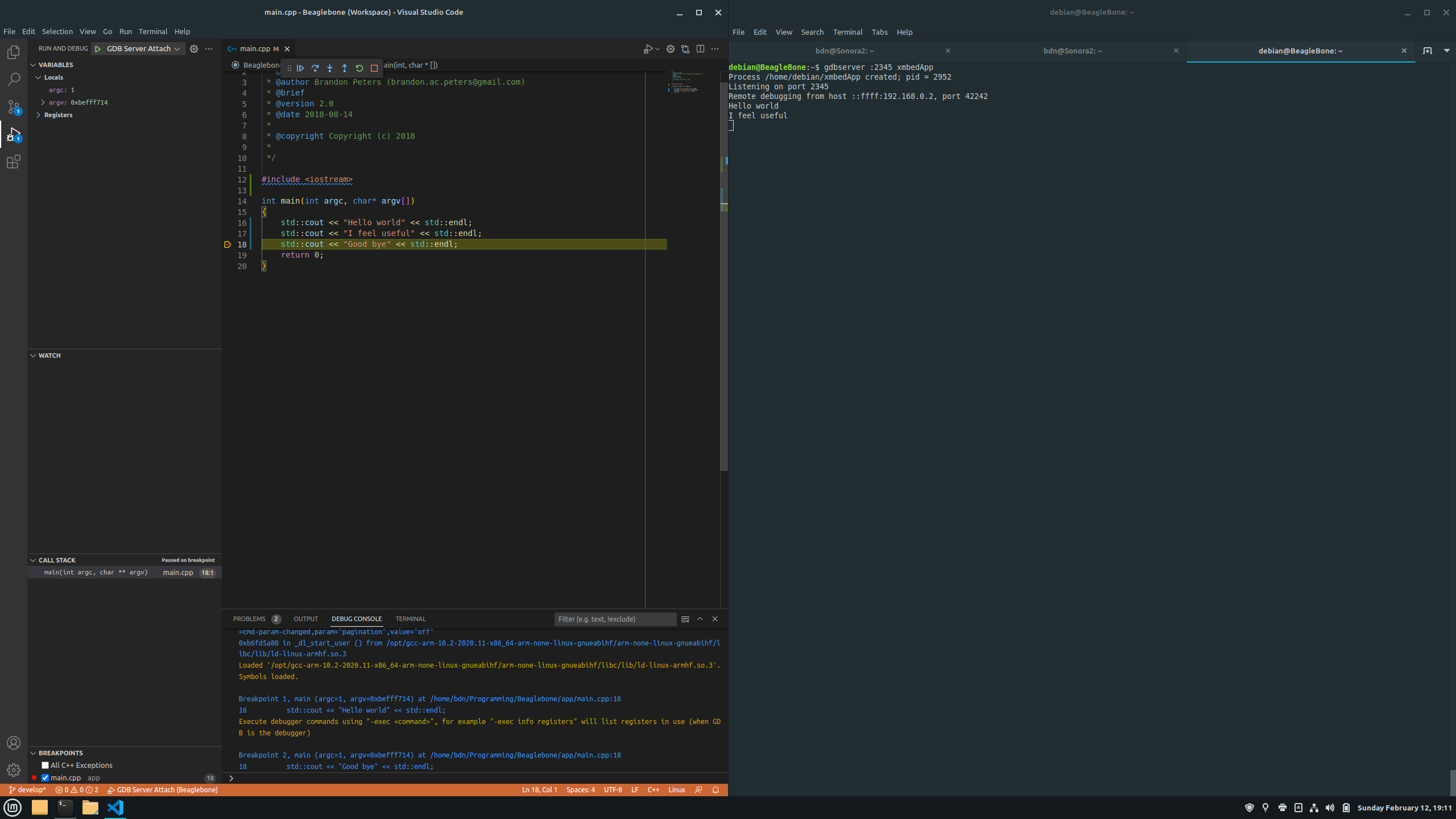
Ejemplo práctico: depurar un programa C++ con gdbserver y WinDbg
Un ejemplo ilustrativo es una pequeña aplicación C++ que escribe un saludo en pantalla, compilada en WSL con símbolos de depuración. Imagina un programa que reserva un std::array<wchar_t, 50> y copia en él un mensaje más largo, provocando que el texto se trunque y aparezcan caracteres ???? al final.
Tras compilar con algo como:
Comando: g++ DisplayGreeting.cpp -g -o DisplayGreeting
Arrancas gdbserver contra ese binario:
Comando: gdbserver localhost:1234 DisplayGreeting
En WinDbg te conectas con la cadena gdb:server=localhost,port=1234 y, una vez establecida la sesión y configuradas rutas de símbolos y fuentes, estableces un punto de ruptura en DisplayGreeting!main, puedes usar dx greeting para inspeccionar el array local y ver su tamaño (50 posiciones), y comprobar visualmente en la pestaña de memoria o en la vista de variables cómo el saludo se queda cortado.
La gracia de este ejemplo es que demuestra que, incluso sin un soporte completo de todos los formatos ELF/DWARF en WinDbg, se pueden recorrer pilas, inspeccionar tipos, poner breakpoints por nombre de función y navegar por el código C++ de forma razonablemente cómoda usando gdbserver como backend remoto.
Depuración de kernel de Linux con qemu y gdb
gdbserver no solo se usa en modo usuario; también hay escenarios muy potentes en modo kernel, especialmente cuando combinas QEMU con soporte de depuración. Aunque aquí el papel de “gdbserver” lo hace la propia opción de QEMU, el enfoque es idéntico: un extremo ejecuta el sistema a depurar y abre un puerto gdb; el otro extremo es gdb o un depurador que hable el protocolo remoto.
Para poder depurar el kernel necesitas compilarlo con opciones específicas de depuración: activar la generación de información de depuración (CONFIG_DEBUG_INFO), los scripts de GDB para kernel (CONFIG_GDB_SCRIPTS) y el propio modo de depuración de kernel (CONFIG_DEBUG_KERNEL). También es importante desactivar opciones que eliminen símbolos en el enlazado, como “Strip assembler-generated symbols during link”.
Tras compilar obtendrás un binario vmlinux “not stripped”, que es el que vas a usar desde gdb. Además, necesitas un initramfs básico, que puedes generar con un comando tipo:
Comando: mkinitramfs -o ramdisk.img
Luego arrancas QEMU con parámetros de depuración. Un ejemplo típico incluye la opción -gdb tcp::1234 para abrir un endpoint remoto compatible con gdb, y -S para que la máquina virtual arranque pausada desde el principio. También indicas el kernel con -kernel vmlinux, el -initrd ramdisk.img, la memoria con -m 512 y sueles redirigir la consola a ttyS0 para manejar todo desde el terminal.
Con QEMU detenido esperando a gdb, desde la máquina host arrancas gdb apuntando a vmlinux y conectas con target remote localhost:1234. A partir de ahí puedes poner breakpoints tempranos, por ejemplo un hb start_kernel, y controlar la ejecución con comandos como c (continuar) y CTRL+C para pausar de nuevo.
Cambios recientes y matices en gdb y gdbserver
En distribuciones modernas como Red Hat Enterprise Linux 8 hay una serie de cambios en gdb y gdbserver que conviene tener en mente, sobre todo si vienes de versiones anteriores o tienes scripts que analizan la salida del depurador.
Por un lado, gdbserver arranca ahora los procesos “inferiores” usando un shell, igual que hace gdb, lo que permite expansión de variables y sustituciones en la línea de comandos. Si por cualquier motivo necesitas desactivar ese comportamiento, hay ajustes específicos documentados en la versión de RHEL 8 para volver al modo anterior.
Se han eliminado o cambiado también varias cosas: el soporte de depuración para programas Java compilados con gcj, el modo de compatibilidad HP-UX XDB, comandos como set remotebaud (sustituidos por set serial baud) o la compatibilidad con cierto formato antiguo de stabs. Además, la numeración de hilos ya no es global, sino por “inferior”, y aparece como inferior_num.thread_num, con variables de conveniencia nuevas como $_gthread para referirse al identificador global.
Otra novedad relevante es el ajuste max-value-size, que limita la cantidad de memoria que gdb puede reservar para mostrar el contenido de un valor. Por defecto son 64 KiB, de modo que intentos de imprimir arrays enormes o estructuras mastodónticas pueden dar como resultado un aviso de “valor demasiado grande” en lugar de escupir toda la memoria en pantalla.
También se ha ajustado cómo maneja gdb el sysroot. Ahora el valor por defecto es target:, lo que significa que para procesos remotos intentará primero buscar bibliotecas y símbolos en el sistema de destino. Si quieres que priorice los símbolos locales, conviene ejecutar set sysroot con la ruta que te interesa antes de hacer target remote.
En cuanto al historial de comandos, la variable de entorno utilizada ahora es GDBHISTSIZE en lugar de HISTSIZE, de manera que puedes afinar cuánto tiempo quieres que se conserven los comandos que has ido tecleando en sesiones de depuración sin interferir con el comportamiento del resto de aplicaciones que usan la librería de lectura de línea.
Consejos de flujo de trabajo y resolución de problemas con gdbserver
De cara a tener un flujo de trabajo cómodo, hay algunos patrones que suelen funcionar muy bien cuando desarrollas para sistemas embebidos o servidores remotos. Lo primero es automatizar al máximo la compilación con símbolos y el despliegue del binario al target, de modo que siempre sepas qué versión del ejecutable se está corriendo y tengas la copia con símbolos a mano en el host.
En entornos con muchos núcleos de crash, merece la pena aprender a usar gdb en modo batch, con flags como --batch, --ex y -x para lanzar comandos automáticamente sobre una lista de cores y procesar sus backtraces desde scripts (por ejemplo en Python). Así puedes filtrar rápidamente problemas repetidos, agrupar fallos por stack trace, etc.
Cuando algo va mal con la conexión remota, la opción --debug de gdbserver es tu mejor amiga. Si arrancas, por ejemplo, un servidor de procesos con:
Comando: gdbserver --debug --multi localhost:1234
La consola de gdbserver mostrará trazas detalladas de lo que está ocurriendo a nivel del protocolo remoto, paquetes que llegan, errores de formato, problemas de desconexión, etc. Esto es muy útil cuando tu gdb se desconecta de repente, un proceso se muere nada más poner un breakpoint o tu GUI de depuración envía algo que gdbserver no entiende bien.
En contextos como el de un router TP-Link donde adjuntas gdbserver a un proceso crítico como httpd, es relativamente común que al poner ciertos puntos de interrupción se produzcan condiciones de carrera o watchdogs que maten el proceso cuando se queda “parado” demasiado tiempo en el depurador. En esas situaciones puede ser necesario ajustar qué señales se detienen, qué hilos se controlan y, si existe, tocar la configuración del propio sistema (tiempos de timeout, watchdogs de hardware) para permitir sesiones de depuración más largas.
Usar gdbserver bien supone combinar varias piezas: compilar con símbolos adecuados, elegir el gdb correcto para la arquitectura, configurar rutas de símbolos y fuentes, entender los dos modos principales de gdbserver (proceso único y multi) y no tener miedo a tirar del modo --debug cuando la conexión no se comporta como esperas. Con esa base, depurar desde tu PC aplicaciones que corren en un Linux remoto, un router o una máquina virtual con kernel personalizado se convierte en algo bastante rutinario y, sobre todo, tremendamente útil.
Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.