- GAIA ejecuta LLM de forma local en Windows con soporte híbrido NPU+iGPU en Ryzen AI.
- Usa Lemonade SDK y RAG (LlamaIndex) para respuestas contextualizadas y precisas.
- Dos instaladores: híbrido (Ryzen AI 300) y genérico con Ollama para cualquier PC.

La inteligencia artificial generativa está viviendo un momento dulce y, con ella, la necesidad de correr modelos de lenguaje grandes en casa se ha disparado; en este contexto, AMD GAIA aparece como una vía sencilla para ejecutar LLM de manera local, sin depender de la nube y reforzando la privacidad de tus datos. Esta propuesta de código abierto está pensada para Windows, funciona en equipos generales y, cuando hay hardware Ryzen AI, saca partido de la NPU e incluso de la iGPU para acelerar la inferencia.
Si te preocupa qué envías a servidores externos o te hartan las esperas, este proyecto te va a sonar a música celestial, porque GAIA ofrece menor latencia, mayor control y un rendimiento muy optimizado en portátiles con AMD Ryzen AI 300 Series. Además, se apoya en el SDK Lemonade para exponer un servicio web compatible con la API de OpenAI, integra un pipeline RAG para contextualizar las respuestas y trae agentes listos para trabajar desde el minuto uno.
¿Qué es AMD GAIA y qué propone exactamente?
GAIA es un desarrollo de código abierto orientado a instalar y ejecutar aplicaciones de IA generativa directamente en tu PC con Windows. Está pensado para que cualquiera pueda poner a funcionar LLMs —como familias tipo Llama y derivados— sin configurar una infraestructura compleja ni enviar información sensible a la nube.
Su gran baza es que aprovecha al máximo la Unidad de Procesamiento Neuronal (NPU) de los Ryzen AI y, en modo híbrido, combina esa NPU con la GPU integrada (iGPU) para repartir cargas y acelerar aún más la inferencia. En equipos compatibles, la NPU de Ryzen AI 300 aporta hasta 50 TOPS, lo que se traduce en fluidez y eficiencia energética en tareas de lenguaje natural.
Al mismo tiempo, el proyecto contempla una vía universal: un instalador genérico que funciona en cualquier PC con Windows, independientemente de que sea AMD o no. Ese modo utiliza Ollama como backend para ejecutar los modelos, de forma que puedes probar GAIA incluso si tu equipo no cuenta con hardware acelerador específico.
Para enriquecer las respuestas, GAIA incorpora un enfoque de Generación Aumentada por Recuperación (RAG); esto permite recuperar información relevante, razonar con contexto adicional, planificar y desplegar herramientas externas dentro de una experiencia de chat realmente interactiva. Hoy el proyecto trae cuatro agentes de serie y hay más en camino con ayuda de la comunidad.

Arquitectura técnica: Lemonade SDK, RAG y componentes de GAIA
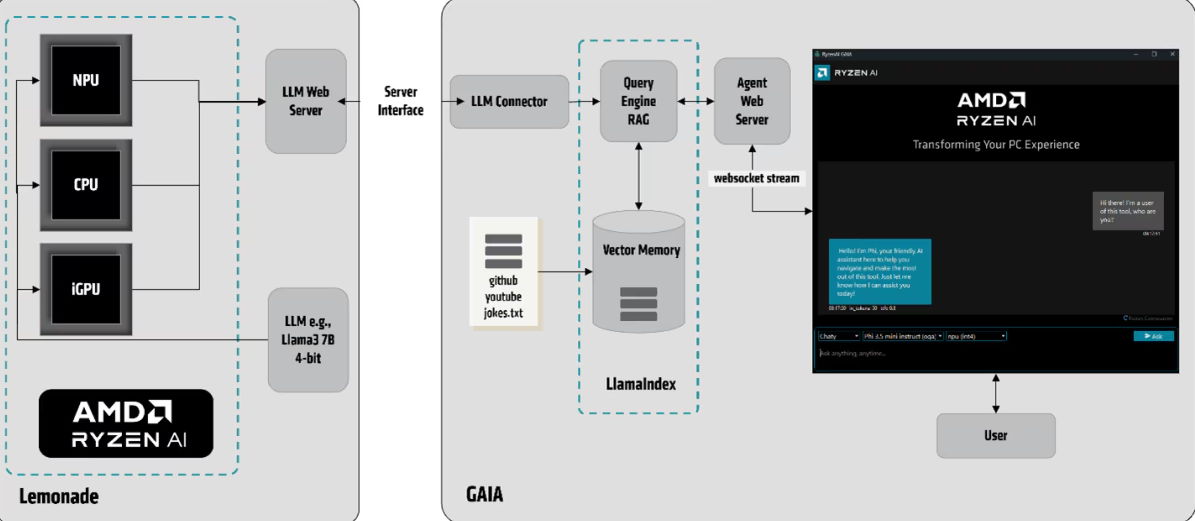
La base técnica se apoya en el SDK Lemonade (TurnkeyML/ONNX), que proporciona utilidades para tareas específicas de LLM: prompting, medición de precisión y servicio sobre múltiples runtimes (por ejemplo, Hugging Face u ONNX Runtime GenAI API) y distintos hardwares (CPU, iGPU y NPU).
En este esquema, Lemonade expone un servicio web de LLM con una API REST compatible con OpenAI, y GAIA consume dicho servicio para orquestar la experiencia. Dentro de GAIA encontramos tres bloques clave que encajan como un guante con el pipeline RAG:
- LLM Connector: puentea la Web API del servicio NPU con el pipeline RAG basado en LlamaIndex, gestionando las llamadas y el formateo de prompts.
- Pipeline RAG con LlamaIndex: incluye el motor de consultas y una memoria vectorial, responsable de procesar y almacenar contexto relevante de fuentes externas.
- Agent Web Server: conecta con la interfaz de GAIA vía WebSocket, permitiendo interacción en tiempo real con el usuario.
El flujo de trabajo es claro y potencia la precisión: tu consulta se vectoriza, se recupera el contexto relevante de índices locales, ese contexto se inyecta en el prompt del LLM y, finalmente, la respuesta se envía por streaming a la UI. Así, cada petición llega enriquecida al modelo y mejora la calidad de las respuestas.
Instaladores y modos de funcionamiento
GAIA se ofrece en dos variantes para adaptarse a tu hardware y a tus necesidades: instalador híbrido y instalador genérico. La idea es que puedas usarlo tanto en un portátil con Ryzen AI de última generación como en un PC Windows estándar.
- Modo Híbrido (Ryzen AI 300 Series): combina NPU + iGPU para maximizar el rendimiento y la eficiencia. En cargas de inferencia, cada unidad ejecuta lo que mejor se le da (por ejemplo, operaciones cuantizadas y kernels específicos), logrando respuestas más rápidas y con menor consumo.
- Modo Genérico (cualquier PC con Windows): es la vía universal. Utiliza Ollama como backend para servir los LLMs y facilita que cualquiera pueda arrancar GAIA sin requisitos de hardware especiales.
Un detalle práctico: ambos modos utilizan el servicio web de LLM expuesto por Lemonade y se comunican con la aplicación mediante una API REST compatible con OpenAI. Esto hace que integrar GAIA en tus flujos (o migrar desde herramientas previas) sea francamente sencillo.
Requisitos del sistema y compatibilidad
Para el modo híbrido, necesitarás un equipo con procesadores AMD Ryzen AI 300 Series, además de contar con los controladores apropiados para la iGPU Radeon (por ejemplo, 890M) y la NPU. Este modo es el que desbloquea el máximo rendimiento y menor latencia.
En cuanto a memoria, se recomiendan 16 GB de RAM como mínimo, siendo 32 GB una cifra más holgada cuando trabajas con contextos largos o modelos más exigentes. A nivel de sistema operativo, el foco está en Windows 11 (Home/Pro), aunque el instalador estándar es compatible también con Windows 10/11.
Si no cumples esos requisitos, no pasa nada: puedes instalar GAIA en modo genérico y experimentar con LLM locales usando tu CPU/GPU y Ollama de backend. La diferencia estará en el rendimiento frente a la opción híbrida.
Instalación paso a paso
El proceso de puesta en marcha es directo. Descarga el instalador desde el repositorio oficial de GitHub y elige la versión que encaja con tu equipo (híbrida para Ryzen AI 300, genérica para el resto).
Una vez tengas el archivo, descomprime y ejecuta el .exe. Si Windows muestra un aviso de seguridad (SmartScreen), ve a “Más información” y pulsa “Ejecutar de todos modos”. La instalación suele tardar entre 5 y 10 minutos, dependiendo de tu conexión.
Al terminar, verás dos accesos directos en el escritorio: GAIA-GUI y GAIA-CLI. La primera ejecución puede tardar un poco más, porque se descargarán los modelos necesarios y dependencias. En algunos casos, el asistente te pedirá un token de Hugging Face para bajar ciertos LLMs.
Si quieres moverte por consola, abre GAIA-CLI y ejecuta «gaia-cli -h» para ver las opciones disponibles. La CLI da control fino de parámetros (modelo, cuantización, contexto, etc.) y permite automatizar pruebas o integrarlo con scripts.
Interfaz gráfica (GUI) y línea de comandos (CLI)
La GUI está pensada para usuarios que prefieren ir rápidos y sin complicaciones: abre GAIA-GUI y comienza a chatear con los agentes, cargar documentos, indexar repositorios y aprovechar el RAG con un par de clics.
En la CLI, encontrarás flexibilidad total. Puedes seleccionar modelos, ajustar la cuantización o definir tamaños de contexto de forma explícita. Es ideal para evaluar rendimiento, comparar parámetros y orquestar GAIA dentro de pipelines de desarrollo.
Además, gracias a que el servicio LLM es compatible con la API de OpenAI, integrar GAIA en herramientas existentes o probar prompts que ya usabas en otros servicios es cuestión de adaptar un endpoint y poco más.
Agentes disponibles y tecnología RAG
Hoy GAIA incluye cuatro agentes orientados a usos distintos, y el equipo —junto con la comunidad— está desarrollando más. Cada agente explota el pipeline RAG para recuperar contexto de índices vectoriales locales y mejorar la respuesta del LLM.
- Simple Prompt Completion: interacción directa con el modelo para pruebas y evaluación de prompts; perfecto para afinar antes de desplegar.
- Chaty: el agente de chat conversacional que gestiona historial de diálogo y soporta una conversación más natural.
- Clip: integra búsqueda en YouTube y capacidades de Q&A; puede vectorizar contenido externo y usarlo como contexto.
- Joker: un generador de chistes que humaniza la experiencia y sirve para probar estilos de salida.
En combinación con RAG, los agentes pueden también usar herramientas externas, razonar y planificar tareas, lo que abre la puerta a flujos de trabajo interactivos y productivos sin salir del entorno local.
Rendimiento: NPU vs iGPU y el modo híbrido
La NPU de Ryzen AI está diseñada para cargas de inferencia de IA y brilla en eficiencia y latencia. GAIA, a partir del lanzamiento de software Ryzen AI 1.3, puede desplegar LLMs cuantizados en modo híbrido, utilizando al mismo tiempo NPU e iGPU y asignando a cada componente las operaciones que mejor domina.
¿Qué ganas con esto? Respuestas más rápidas, menor consumo y una experiencia fluida incluso con modelos más pesados o contextos más largos. Y si tu equipo no dispone de NPU, GAIA sigue siendo útil en modo genérico, con prestaciones acordes al hardware disponible.
Ventajas de ejecutar LLMs en local
El primer gran beneficio es la privacidad: no hay que enviar datos a servidores externos, algo crítico en sectores sensibles o cuando manejas información confidencial.
También destaca la baja latencia. Al no depender de la red, las respuestas llegan más rápidas y la interacción se siente inmediata, algo clave para productividad y buenas experiencias de usuario.
Por último, el rendimiento es más predecible. La optimización para NPU (y iGPU) permite aprovechar al máximo el hardware del equipo, con menor consumo energético y menos calor en sesiones largas.
Desinstalación y mantenimiento
Si necesitas desinstalar GAIA, el proceso es muy simple. Cierra todas las instancias (CLI y GUI) para evitar bloqueos de archivos antes de borrar nada.
A continuación, elimina la carpeta de GAIA en AppData y borra las carpetas de modelos almacenadas en .cache. Finalmente, quita los accesos directos del escritorio y listo.
Este método manual compensa que aún no haya un desinstalador automático. En unos minutos tendrás el sistema limpio y sin restos de modelos o índices locales.
Casos de uso e industrias donde encaja
GAIA es especialmente interesante allí donde la privacidad manda: sanidad, finanzas y entornos corporativos tienen mucho que ganar ejecutando IA en local y reduciendo exposición a terceros.
También suma en escenarios sin conexión estable: centros con conectividad limitada o sin Wi‑Fi pueden ejecutar flujos de trabajo de IA sin depender de la nube.
Para creación de contenidos, atención al cliente y asistentes internos, los agentes con RAG aportan respuestas contextualizadas y coherentes con tus fuentes locales (repositorios, documentos, vídeos, etc.).
Comparativa con otras soluciones locales
Frente a alternativas como LM Studio o ChatRTX, GAIA pone el foco en una integración profunda con el hardware AMD, en especial con las NPU de Ryzen AI, y en un pipeline RAG robusto pensado para recuperar y usar conocimiento local.
Además, el proyecto es abierto y extensible. Puedes crear tus propios agentes y casos de uso sin pelearte con cajas negras, y el soporte de API REST compatible con OpenAI allana la integración con apps existentes.
Novedades e impulso de cara a 2025
El equipo detrás de GAIA ha ido incorporando mejoras que amplían el abanico de escenarios. Entre ellas, un soporte mejorado para Tensor Cores de NVIDIA que acelera la ejecución cuando trabajas con GPUs de esa marca en determinados flujos.
También se habla de integración con plataformas en la nube como GCP y AWS para facilitar trabajos a gran escala y sincronización cuando necesitas combinar entornos local/cloud de forma controlada.
Otra línea destacada es la mejora del soporte ONNX, que incrementa la interoperabilidad entre marcos de IA y hace más fácil mover modelos entre plataformas. Incluso hay herramientas para experimentar con IA cuántica, abriendo la puerta a investigación y pruebas de vanguardia.
Licencia, comunidad y hoja de ruta
GAIA se distribuye bajo licencia MIT y su repositorio en GitHub invita a colaborar: reportar issues, proponer mejoras y crear nuevos agentes que cubran más necesidades reales.
En el horizonte, el roadmap menciona más modelos y arquitecturas soportadas, nuevos agentes para casos verticales, una posible expansión a otros sistemas operativos y mejoras continuas en la eficiencia de la NPU.
GAIA reúne lo necesario para quien quiera un setup local serio: privacidad, rendimiento y una arquitectura que se integra bien con tu flujo. Si cuentas con un portátil Ryzen AI 300 Series, el modo híbrido te dará un plus claro; y si no, el modo genérico te permite arrancar hoy mismo y crecer desde ahí.

Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.