- Los datos duplicados distorsionan análisis y decisiones, por lo que es esencial detectarlos y controlarlos antes de trabajar con ellos.
- Hojas de cálculo como Excel permiten resaltar, filtrar y eliminar duplicados combinando formato condicional, filtros avanzados y funciones de texto.
- En bases de datos SQL, SELECT DISTINCT y alternativas como GROUP BY ayudan a obtener resultados sin filas repetidas sin modificar los datos originales.
- Gestores bibliográficos y buenas prácticas de copia de seguridad y revisión previa reducen el riesgo de perder información relevante al eliminar duplicados.
Cuando trabajas con bases de datos, hojas de cálculo o sistemas de información, los datos duplicados pueden convertirse en un auténtico quebradero de cabeza. Registros repetidos, nombres escritos de mil formas distintas, fechas mal formateadas o espacios de más hacen que los análisis se vuelvan poco fiables y que pierdas tiempo revisando a mano lo que el sistema podría ayudarte a limpiar en segundos.
La buena noticia es que existen herramientas muy potentes para localizar, resaltar y eliminar datos repetidos tanto en Excel y Google Sheets como en bases de datos SQL o gestores bibliográficos. Entender bien cómo funcionan, en qué se diferencian y qué riesgos tienen (como borrar información que luego eches de menos) es clave para mantener tus datos en orden y poder analizarlos con tranquilidad.
Por qué aparecen datos duplicados y por qué son un problema
En la práctica, los duplicados surgen por errores humanos, importaciones repetidas o sistemas poco coordinados. Formularios que se envían dos veces, ficheros que se combinan sin limpieza previa o integraciones entre aplicaciones que no validan bien la información son el caldo de cultivo perfecto para que se te llene todo de registros repetidos.
Además de los duplicados evidentes, te encontrarás variaciones ligeras que en realidad representan el mismo dato: nombres con mayúsculas y minúsculas mezcladas, espacios extra, abreviaturas diferentes o fechas con formatos distintos que el sistema no reconoce como iguales, aunque para una persona sea obvio que se refieren a lo mismo.
El impacto no es menor: las estadísticas salen distorsionadas, se inflan los conteos de clientes o pacientes, se repiten correos en campañas de email, se duplican facturas o se sobreestima el número de pedidos. Esto puede traducirse en decisiones equivocadas, costes extra y una enorme desconfianza en la calidad de los datos.
Por eso, antes de lanzarte a hacer cuadros de mando o análisis avanzados, conviene invertir tiempo en una buenísima limpieza de datos para detectar y corregir incoherencias. Eliminar duplicados es una parte central de este proceso, pero no la única: también hay que homogeneizar texto, eliminar espacios raros y normalizar fechas.
Detectar y resaltar datos duplicados en hojas de cálculo
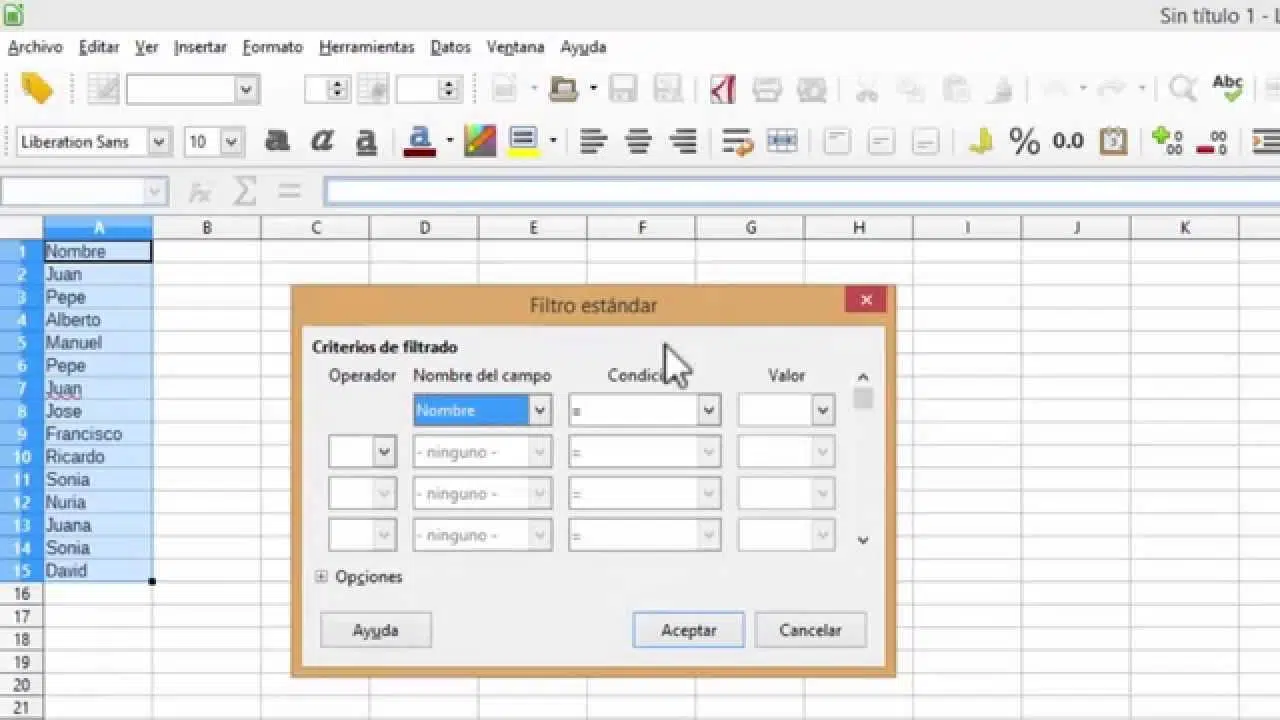
En herramientas como Excel dispones de funciones muy cómodas para localizar de un vistazo qué valores se repiten en un rango de celdas. Antes de borrar nada, es recomendable usar un formato visual que te ayude a revisar y decidir con calma qué quieres conservar.
Una forma muy habitual de empezar es mediante el formato condicional para resaltar valores que aparecen más de una vez. De esta manera, no cambias el contenido de las celdas, simplemente las marcas para poder analizarlas.
El flujo típico consiste en seleccionar primero las celdas a revisar y luego aplicar una regla de formato condicional que marque los duplicados con un color de fondo o tipo de letra distinto. Esto te permite identificar patrones: por ejemplo, ver si una persona aparece varias veces en una lista de clientes o si determinados códigos de producto se han registrado más de una vez.
Además, puedes combinar este resalte automático con filtros en la propia hoja de cálculo para ver solo filas afectadas por duplicados y revisarlas una a una. Así ganas control y reduces el riesgo de borrar información importante por accidente.
Eliminar valores duplicados en Excel de forma segura
Cuando tengas claro qué repeticiones sobran, Excel incluye una función específica llamada “Quitar duplicados” que borra de manera permanente las filas repetidas. Aquí es donde hay que andar con pies de plomo, porque lo que elimines no se recupera fácilmente si no has guardado una copia.
Antes de ejecutar esta herramienta, es muy recomendable copiar el rango de datos original a otra hoja o archivo de respaldo. Así, si la limpieza produce un resultado que no esperabas, podrás revisar qué has quitado y recuperar información sin dramas.
El procedimiento se basa en seleccionar el rango de celdas que quieres depurar y luego indicar en qué columnas se deben comparar los valores para decidir si una fila es duplicada. Si marcas varias columnas, solo se considerará duplicada la fila cuya combinación completa coincida con otra fila, lo que es muy útil cuando trabajas con datos complejos.
Al confirmar la operación, Excel elimina las filas sobrantes y te muestra un resumen con cuántos duplicados se han borrado y cuántos registros únicos quedan. Este pequeño informe te ayuda a validar si los resultados encajan con lo que esperabas al empezar la limpieza.
Conviene tener presente que no es lo mismo filtrar valores únicos que eliminar duplicados. Al filtrar, las filas repetidas simplemente se ocultan temporalmente, pero siguen ahí; al quitar duplicados, las borras del todo. Por eso, empezar con un filtro de únicos o con formato condicional es una estrategia más prudente.
Criterios para considerar que un valor es duplicado
Cuando las herramientas de hoja de cálculo comparan duplicados, lo hacen basándose en lo que se ve exactamente en la celda, no en el valor subyacente interpretado. Esto tiene algunas consecuencias curiosas que necesitas conocer para no llevarte sorpresas.
Por ejemplo, dos fechas que representan el mismo día pueden no considerarse duplicadas si una está escrita como “08/03/2006” y otra como “8 de marzo de 2006”, ya que el contenido de texto es diferente aunque el significado sea idéntico. Lo mismo puede ocurrir con nombres y cadenas con espacios o mayúsculas distintos.
De manera similar, un número almacenado como texto y el mismo número en formato numérico pueden tratarse como valores diferentes. Por eso es tan importante normalizar formatos antes de lanzarse a eliminar filas repetidas en bloque.
Antes de hacer una limpieza agresiva, merece la pena filtrar primero por valores únicos o usar formato condicional para confirmar que el criterio de comparación está funcionando como tú crees. Ajustar estas reglas de juego al principio evita perder datos válidos o dejar duplicados camuflados.
Funciones de texto en hojas de cálculo para limpiar datos sucios
Una grandísima parte de los problemas con los duplicados no viene de que se repita exactamente el mismo valor, sino de que el mismo dato está escrito de formas ligeramente distintas. Ahí es donde entran en juego las funciones de texto de Excel o Google Sheets para homogeneizar y preparar el terreno antes de quitar repeticiones.
Es muy habitual encontrarse con columnas donde unos nombres están en mayúsculas, otros en minúsculas y otros mezclados al azar. Para unificar, dispones de funciones que convierten todo a minúsculas, todo a mayúsculas o solo ponen en mayúscula la primera letra de cada palabra. Con esto consigues que “ANA PÉREZ”, “ana pérez” y “Ana Pérez” se traten del mismo modo.
También son frecuentes los textos con espacios de más, tanto dentro de la cadena como al principio o al final. Una función especializada puede eliminar los espacios sobrantes y dejar solo un espacio normal entre palabras, de forma que se acaben los “ Juan García ” o similares que rompen las comparaciones.
Para datos que vienen muy pegados, como códigos combinados o nombres y apellidos en la misma celda, es útil recurrir a funciones de extracción y unión. Puedes extraer una parte del texto indicando desde qué posición y cuántos caracteres quieres sacar o unir varias cadenas en una sola para reconstruir campos más coherentes.
En el caso de las fechas, si te llegan como texto con distintos estilos, es buena idea transformarlas en un formato estándar de fecha basado en año, mes y día. De esta manera, las hojas de cálculo las tratan como fechas reales, puedes ordenarlas correctamente y las comparaciones dejan de depender del aspecto visual de la celda.
Filtrar valores únicos y eliminar duplicados en hojas de cálculo
Además de las herramientas de formato y las funciones de texto, tanto Excel como Google Sheets permiten filtrar rápidamente para ver solo los valores únicos de una columna o de un conjunto de columnas. Esta es una forma muy efectiva de revisar resultados antes de tomar decisiones irreversibles.
En algunos entornos, puedes usar opciones avanzadas de filtrado para indicar que solo quieres mostrar filas con valores únicos en una o varias columnas determinadas. Este filtrado no borra datos, simplemente esconde temporalmente las repeticiones, lo que lo convierte en un paso intermedio muy prudente.
Una vez comprobado que la vista de únicos es la que te interesa, dispones de comandos específicos para quitar duplicados directamente desde los menús de datos. Normalmente, se accede a algo tipo “Datos > Quitar duplicados”, donde eliges en qué columnas basar la comparación.
Otra opción es usar formato condicional para resaltar tanto los duplicados como los valores únicos, según te interese. Así puedes, por ejemplo, marcar en un color llamativo las filas que solo aparecen una vez y analizar si son registros atípicos, errores de carga o simplemente casos poco frecuentes que hay que conservar.
Si trabajas con listas desplegables o validaciones de datos, tiene mucho sentido limpiarlas también. A través de menús de validación puedes definir listas cerradas que evitan que se introduzcan variaciones tipográficas, reduciendo de raíz la aparición de falsos duplicados que en realidad solo son errores de escritura.
Limpieza de duplicados en bases de datos SQL con SELECT DISTINCT
Cuando pasamos del mundo de las hojas de cálculo al de las bases de datos, el enfoque cambia un poco. En SQL, una de las primeras herramientas para gestionar información repetida es el operador DISTINCT, que se utiliza junto al comando SELECT para devolver filas sin duplicados en los resultados de una consulta.
La idea es sencilla: al construir una sentencia SELECT, puedes añadir la palabra clave DISTINCT para indicar que solo quieres una aparición de cada combinación de valores en las columnas seleccionadas. De esta forma, si una misma fila lógica se repite varias veces en la tabla, la consulta te devolverá una única línea.
Hay que tener claro que SELECT DISTINCT no borra nada de la base de datos: solo afecta al resultado que ves al ejecutar la consulta. La información original sigue tal cual en las tablas, lo cual es perfecto para análisis exploratorios en los que no quieres modificar datos todavía.
En cuanto a la sintaxis, el patrón general consiste en combinar SELECT DISTINCT con la lista de columnas que te interesan, seguido de la cláusula FROM para indicar la tabla y, opcionalmente, una cláusula WHERE para filtrar por condiciones específicas. Así puedes pedir, por ejemplo, clientes únicos solo de un país o productos distintos de una determinada categoría.
Este enfoque es muy útil cuando quieres reducir resultados a entradas no repetidas, ya sea para obtener el listado de clientes sin duplicar por pedidos múltiples, mostrar una lista de códigos de producto distintos o generar un conteo de elementos únicos en un conjunto de datos.
Diferencias entre DISTINCT y otras formas de evitar duplicados en SQL
Aunque DISTINCT y UNIQUE puedan sonar parecido, no desempeñan el mismo papel dentro del ecosistema SQL. DISTINCT actúa en consultas SELECT, afectando a las filas devueltas; UNIQUE suele estar relacionado con restricciones en la definición de las tablas, indicando que ciertos campos no pueden contener valores repetidos.
Además, en contextos con muchos datos, usar SELECT DISTINCT puede ser costoso en rendimiento, porque el motor de la base de datos tiene que comparar todas las columnas seleccionadas para determinar qué filas son iguales. En tablas grandes o con muchas columnas, esto puede volverse pesado.
Por eso, en algunos casos compensa plantearse alternativas. Una de las más comunes es usar GROUP BY para agrupar filas por una o varias columnas y aplicar funciones de agregación (como COUNT, MIN o MAX) que te permitan resumir los datos de forma eficiente.
También puedes apoyarte en cláusulas como EXISTS para comprobar si determinados valores están presentes en otra tabla, evitando unirte a filas repetidas innecesarias. O recurrir a subconsultas con SELECT, FROM y WHERE bien definidos para acotar mucho mejor qué registros quieres traer.
Cuando lo que te interesa es contar cuántos valores únicos hay en una columna, es frecuente combinar COUNT con DISTINCT, de forma que obtienes directamente el número de elementos diferentes sin necesidad de revisar cada uno de ellos manualmente.
Ejemplos prácticos: consultas de clientes y direcciones sin duplicados
Imagina que trabajas con una tabla de pedidos en la que cada fila representa una compra realizada. Es habitual que el mismo cliente aparezca varias veces si ha hecho más de un pedido. Si solo quieres ver una vez a cada cliente, SELECT DISTINCT es una herramienta muy clara.
En este escenario, construirías una consulta que seleccione las columnas de identificación de cliente (por ejemplo, su ID y su nombre) y aplicarías DISTINCT para recibir una lista con cada cliente solo una vez, aunque en la tabla original tenga diez pedidos distintos.
Algo similar ocurre si necesitas ver todas las direcciones de envío únicas a las que se han mandado productos. Si cada pedido incluye una dirección, la tabla estará llena de repeticiones; sin embargo, con DISTINCT en las columnas de dirección puedes generar un listado compacto de puntos de envío.
Cuando quieres centrarte en clientes de una zona concreta, puedes añadir una cláusula WHERE para indicar, por ejemplo, que solo te interesan los registros de un país específico. De esta forma, SELECT DISTINCT actúa sobre un subconjunto de la tabla, y no sobre la totalidad de los datos.
En el ámbito sanitario o académico, el operador también resulta muy práctico para agrupar datos de pacientes o autores que aparecen varias veces en distintos estudios o artículos, mostrando una sola entrada por cada entidad a efectos de análisis.
Gestión de referencias duplicadas en bases de datos bibliográficas
En el terreno de la documentación científica, las bases de datos bibliográficas suelen ofrecer herramientas específicas para eliminar referencias repetidas cuando realizas búsquedas en diferentes fuentes. Esto es crucial para que tus revisiones de literatura no se llenen de artículos duplicados.
En estos sistemas, suele existir un comando de tipo “Remove duplicates” dentro del menú de herramientas, que analiza el conjunto de resultados y elimina automáticamente las referencias repetidas. El sistema suele informar de cuántos elementos han sido suprimidos y cuántos quedan en el conjunto actual.
En muchas plataformas puedes configurar, desde un apartado de preferencias, que la eliminación de referencias duplicadas se haga de forma automática cada vez que realizas una nueva búsqueda. Esto ahorra bastante trabajo manual, aunque conviene revisar regularmente que el criterio de duplicidad sea el adecuado.
Además de la eliminación en bloque, estos gestores permiten seleccionar manualmente referencias concretas para decidir si quieres mantenerlas o borrarlas. Esta revisión manual es útil cuando el sistema duda si dos registros son realmente el mismo artículo o si corresponden a versiones distintas (por ejemplo, preprints y versiones definitivas).
Tras eliminar duplicados, el conjunto de resultados se actualiza y muestra el número reducido de referencias. Este control numérico ayuda a validar que la depuración ha tenido efecto y a documentar el proceso en revisiones sistemáticas o informes de búsqueda.

Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.