- Grok 4.20 introduce una arquitectura de cuatro agentes especializados que colaboran en tiempo real para reducir alucinaciones y mejorar el razonamiento.
- El modelo se entrena en el superclúster Colossus con 200.000 GPUs, maneja contextos de hasta 2M de tokens y soporta texto, imagen y vídeo.
- Ha demostrado rendimiento sólido en trading con dinero real, investigación matemática y tareas complejas de ingeniería y programación.
- Su acceso se limita a planes de pago de X y futura API, posicionándose como opción avanzada frente a modelos tradicionales de un solo agente.
Si llevas tiempo trasteando con modelos de IA, seguro que has oído hablar de Grok 4.20 y del revuelo que está montando. No es solo “otra versión más”: xAI ha metido en la mesa una arquitectura de cuatro agentes colaborando en paralelo que cambia bastante la forma en la que un modelo grande se enfrenta a problemas complejos.
En las siguientes líneas vas a encontrar una explicación muy completa y sin rodeos de qué es Grok 4.20, cómo funciona su sistema de 4 agentes, qué rendimiento real está mostrando y para qué te puede servir, tanto si eres desarrollador como si solo quieres una IA para investigar, programar o hacer trading con cabeza.
Qué es Grok 4.20 y por qué está dando tanto que hablar

Grok 4.20 es la versión beta más reciente del modelo principal de xAI, lanzada de forma limitada a mediados de febrero de 2026 para usuarios de pago del ecosistema X. No lo vas a encontrar abierto a todo el mundo: de momento solo aparece para quienes tienen SuperGrok (unos 30 dólares al mes) o X Premium+, y el anuncio oficial en el blog de x.ai todavía no se ha publicado.
El propio Elon Musk ha ido adelantando detalles en X, asegurando que Grok 4.20 ya responde correctamente a preguntas de ingeniería abiertas y que deja claramente atrás a la versión Grok 4.1 de finales de 2025. En varias ocasiones también ha insinuado que está por encima de modelos punteros como GPT-5.1 o Gemini 3 Pro en tareas de análisis complejo y trading automático, algo que xAI respalda con resultados de pruebas internas.
Más allá del marketing, lo que hace especial a este modelo es que no se limita a ser “más grande”: Grok 4.20 introduce un esquema interno de cuatro agentes especializados (4 Agents) que colaboran en tiempo real. Cada vez que envías una consulta, no responde un único cerebro, sino un pequeño “equipo” de IAs que discute entre sí antes de devolverte nada.
A nivel de infraestructura, Grok 4.20 se apoya en el superclúster Colossus con 200.000 GPUs, emplea técnicas avanzadas de aprendizaje por refuerzo ya en la fase de preentrenamiento y se estima que ronda los 3 billones de parámetros, aunque xAI no ha hecho pública la cifra exacta. Todo esto se traduce en una enorme capacidad de cálculo y razonamiento.
Otro punto clave es el contexto: Grok 4.20 trabaja con una ventana mínima de 256.000 tokens y puede llegar hasta los 2 millones de tokens en ciertas variantes de API. Esto le permite tragar sin despeinarse códigos muy largos, documentación corporativa completa o grandes volúmenes de texto e información histórica.
Arquitectura de 4 agentes: cómo piensa realmente Grok 4.20

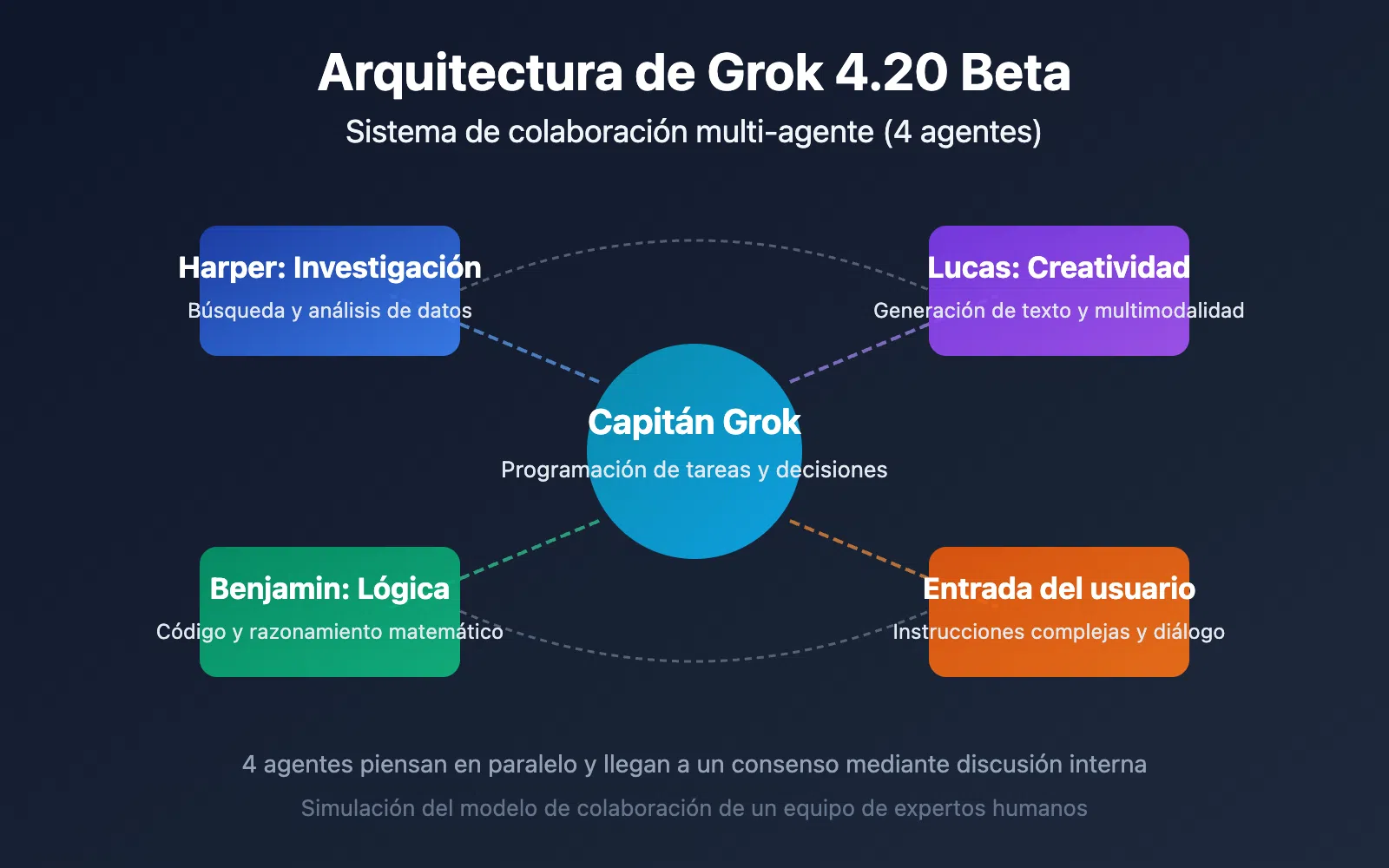
El sello de identidad de Grok 4.20 es su arquitectura multiagente 4 Agents. En lugar de un único modelo que lo hace todo, aquí tenemos cuatro agentes con funciones distintas que cooperan y se corrigen entre sí antes de generarte la salida.
Los cuatro agentes que intervienen en cada interacción son los siguientes, cada uno con un rol muy claro dentro del sistema de Grok 4.20:
- Grok (Capitán): actúa como coordinador y sintetizador. Es quien interpreta la petición, la descompone en subtareas, reparte el trabajo entre los otros agentes y monta la respuesta final.
- Harper: está centrado en búsqueda de información y verificación de hechos. Se conecta a datos en tiempo real, especialmente al Firehose de X, para obtener contenido fresco y comprobar la veracidad de lo que se está generando.
- Benjamin: es el experto en matemáticas, código y lógica formal. Se encarga de demostrar, calcular, revisar algoritmos y asegurar que los razonamientos técnicos cuadren.
- Lucas: se orienta a la creatividad, el estilo y la experiencia de usuario. Refina la redacción, propone enfoques originales y busca que la salida sea clara y agradable de leer.
La gracia de este diseño no es solo ponerles nombre, sino que el sistema fomenta una “fricción productiva” entre los agentes. En lugar de generar la respuesta a la primera, estos cuatro componentes discuten internamente, comparan resultados, detectan incoherencias y pulen el contenido.
En la práctica, el flujo de trabajo se puede entender en cuatro fases. Primero, en la fase de descomposición de la tarea, Grok Capitán analiza tu consulta, separa los subproblemas (datos a buscar, cálculos que hacer, tono y estructura del texto, etc.) y activa a Harper, Benjamin y Lucas.
Después llega la etapa de pensamiento en paralelo. Mientras Harper rastrea datos y verifica información, Benjamin realiza el razonamiento crítico y los cálculos necesarios, y Lucas propone formas de presentar y estructurar el resultado, todos trabajando al mismo tiempo.
La tercera parte es una discusión interna con revisión cruzada. Si, por ejemplo, los números de Benjamin no encajan con lo que ha encontrado Harper en fuentes en vivo, los agentes se cuestionan, revisan los pasos y corrigen los fallos. Este bucle se repite varias veces hasta que la solución encaja desde todos los ángulos.
Finalmente, en la fase de síntesis y respuesta, el capitán Grok recopila las conclusiones de todos, resuelve discrepancias y genera el texto final que ves tú. El resultado pretende parecerse más a lo que haría un equipo de expertos reunidos debatiendo un tema que a un único modelo soltando una respuesta de golpe.
Desde un enfoque técnico, esta arquitectura busca sobre todo reducir de forma drástica las alucinaciones. Los modelos tradicionales, al trabajar solos, tienden a “inventar con seguridad” cuando no saben algo. Al forzar que cuatro agentes se supervisen mutuamente, Grok 4.20 consigue frenar buena parte de esos errores de inventiva, según las pruebas que ha mostrado xAI.
Especificaciones técnicas y capacidades clave de Grok 4.20
Más allá de la parte conceptual, Grok 4.20 viene con unas especificaciones técnicas de primer nivel que lo colocan entre los modelos más potentes disponibles a día de hoy, aunque todavía esté limitado a una beta.
Para empezar, está desarrollado íntegramente por xAI, la empresa de Elon Musk, sobre el ya mencionado superclúster Colossus con 200.000 GPUs. Ese músculo de hardware permite entrenar modelos gigantes aplicando aprendizaje por refuerzo a escala masiva en el propio preentrenamiento, algo poco habitual y que, según xAI, multiplica por seis la eficiencia computacional.
En cuanto al tamaño del modelo, todo apunta a que nos movemos en torno a los 3 billones de parámetros, posicionándolo en la liga alta de los modelos de propósito general actuales. Aunque la cifra no es oficial, la compañía reconoce que se trata de la versión más grande y sofisticada de la serie Grok hasta la fecha.
La ventana de contexto es otro de los puntos donde Grok 4.20 aprieta fuerte. La mayoría de usuarios dispone de un mínimo de 256.000 tokens, que ya es enorme, y hay variantes de API que extienden esa capacidad hasta los 2 millones de tokens. Esto lo hace especialmente útil para proyectos en los que haya que digerir mucha información de golpe.
Además, Grok 4.20 se ha diseñado como un sistema multimodal desde el inicio. Soporta entrada de texto, imágenes y vídeo de forma unificada, e integra herramientas como Grok Imagine para la generación y edición creativa de contenido visual, lo que facilita montar flujos donde análisis y creación se hagan sin salir del mismo entorno.
Un elemento diferenciador es el acceso a X Firehose, el flujo masivo de mensajes de la red X. Hablamos de unos 68 millones de tuits diarios en inglés, que Grok 4.20 puede transformar en señales de sentimiento, tendencias y contexto en tiempo (casi) real, algo muy valioso para tareas de trading, monitorización de reputación o análisis de conversación social.
Rendimiento real: trading, matemáticas e ingeniería
Más allá de benchmarks sintéticos, xAI ha enseñado varios ejemplos en los que Grok 4.20 se ha sometido a pruebas en escenarios reales, con resultados que llaman bastante la atención, especialmente en finanzas y matemáticas avanzadas.
Uno de los casos más sonados es su participación en Alpha Arena, una competición de trading con dinero real. En los primeros checkpoints de prueba, las configuraciones basadas en Grok 4.20 fueron las únicas que consiguieron obtener beneficios sostenidos, mientras que otros modelos punteros como GPT-5, Claude o Gemini terminaron en números rojos.
En esa competición, Grok 4.20 alcanzó una rentabilidad media del 12,11 %, con picos de retorno cercanos al 50 % en determinadas estrategias. Esa capacidad para moverse en los mercados no viene de la nada: se apoya justamente en la integración de datos en directo desde X, que le permite detectar cambios de sentimiento y patrones de conversación en cuestión de milisegundos y convertirlos en decisiones de trading.
Pero no todo es bolsa y criptos. En el terreno académico, el matemático Paata Ivanisvili ha utilizado una versión interna de Grok 4.20 para lograr nuevos resultados en el estudio de las funciones de Bellman, un área bastante técnica de las matemáticas. Que un modelo de lenguaje contribuya de forma tangible a avances en ese nivel da una idea de la potencia de razonamiento de Benjamin, el agente lógico de la arquitectura.
En ingeniería y desarrollo de software, Musk ha comentado públicamente que esta versión “ya empieza a contestar correctamente preguntas de ingeniería abiertas”, algo que antes se le resistía a Grok 4.1. La combinación del contexto gigantesco, la colaboración entre agentes y el refuerzo profundo permiten atacar problemas complejos de arquitectura de sistemas, depuración y diseño de algoritmos con una calidad que, según xAI, supera a los modelos anteriores de la casa.
A esto se suma que, según estimaciones difundidas por la propia compañía, la tasa de alucinaciones de Grok 4.20 habría bajado por debajo del 4 %, lo que implica menos necesidad de verificación manual, menos reescrituras y una mayor fiabilidad en uso diario, siempre con el matiz de que nadie está a cero errores.
Modos de uso: Fast, Expert, Grok 4.20 Beta y Heavy
Dentro del selector de modelos de grok.com, los usuarios con acceso encuentran varios modos pensados para escenarios distintos. No siempre compensa tirar del sistema más pesado, así que tiene sentido entender qué aporta cada opción.
El modo Fast se basa en Grok 4.1 y está orientado a lograr respuestas muy rápidas con un solo modelo. Es ideal para conversación diaria, consultas sencillas, resúmenes cortos o cualquier tarea que no requiera análisis profundo. Es el que te cubre el 80 % de lo que uno hace con un chatbot en el día a día.
Un paso por encima está Expert, una versión más profunda de la serie Grok 4.x que sigue funcionando con un solo modelo pero con cadenas de pensamiento más largas y elaboradas. Aquí el sistema se toma más tiempo para razonar, por lo que encaja bien para trabajo profesional, informes, análisis detallados o problemas técnicos no extremos.
El tercer modo es Grok 4.20 Beta como tal, con toda la arquitectura multiagente de 4 Agents activada. Es la opción recomendada para investigación compleja, programación avanzada, estrategia empresarial, análisis de inversiones o proyectos que mezclan distintos tipos de tareas en una misma petición.
Por último tenemos Heavy, que se describe como un equipo de expertos aún más grande y profundo. Está pensado para problemas extremadamente difíciles, trabajo académico de frontera o consultas en las que la prioridad absoluta sea la profundidad del razonamiento, aunque a costa de tiempos de respuesta significativamente más altos.
Si tienes dudas sobre cuándo usar cada modo, la regla general sería usar Fast para lo cotidiano, Expert para tareas serias de trabajo, Grok 4.20 Beta cuando quieras una mirada multiángulo y Heavy solo para los retos más duros, donde te compense esperar más.
Escenarios de uso donde Grok 4.20 brilla de verdad
La estructura de cuatro agentes convierte a Grok 4.20 en una herramienta muy flexible que se adapta bien a casos de uso donde haya muchos factores en juego y no baste con una respuesta única y plana. Hay varios terrenos donde destaca de forma clara.
En primer lugar, para programación compleja y trabajo con grandes bases de código. Benjamin se encarga de la lógica, la arquitectura y los algoritmos, Harper revisa documentación y recursos externos, y Lucas pule la legibilidad del código y los comentarios. Esto permite abordar desde refactorizaciones serias hasta el diseño de nuevos módulos sin perder contexto.
También es muy potente para análisis de estrategia de negocio y toma de decisiones. En una sola consulta puedes pedir un estudio de mercado, ideas de posicionamiento, un esquema de contenidos y métricas clave a vigilar. El sistema desglosa la tarea de forma interna, combina datos de X en tiempo real con información estática y te propone un plan coordinado.
En el ámbito académico, Grok 4.20 funciona bien como asistente para investigación avanzada. Permite integrar revisión bibliográfica, construcción de hipótesis, desarrollo de demostraciones formales y redacción de artículos largos, aprovechando la gran ventana de contexto para no perder información en el camino.
Si tu prioridad es la creación de contenido, el modelo es capaz de generar textos extensos y estructurados en los que Lucas se centra en el estilo, Harper en la precisión de los hechos y Benjamin en que la argumentación tenga sentido. De este modo se reducen los típicos errores de coherencia que surgen cuando se elaboran piezas muy largas.
Por último, para inversión y trading, Grok 4.20 puede combinar datos históricos con señales en vivo de X, análisis cuantitativos y evaluación cualitativa de riesgo. No es una varita mágica, pero sí una herramienta bastante más integrada que los modelos que no tienen acceso directo a datos de mercado en tiempo real.
Grok 4.20 frente a Perplexity y otros modelos de búsqueda
Una duda muy habitual es si compensa pagar SuperGrok principalmente para buscar información, sobre todo viendo que algunos usuarios comentan que Perplexity ha perdido fuerza en calidad de resultados y solidez del razonamiento en los últimos tiempos.
En este terreno, Grok 4.20 juega con varias ventajas claras. Para empezar, su arquitectura de 4 Agents hace que la fase de búsqueda, verificación y razonamiento estén diferenciadas y coordinadas. Harper no solo lanza una búsqueda y ya está, sino que cruza lo que encuentra con los cálculos de Benjamin y las propuestas de Lucas, bajo la supervisión de Grok Capitán.
Esa estructura reduce las probabilidades de que te devuelva un resumen aparente pero vacío, que es una crítica frecuente a muchos sistemas de búsqueda conversacional. El objetivo es ofrecer respuestas algo más profundas, más argumentadas y con menos errores de bulto, aunque por supuesto siempre conviene contrastar la información en temas delicados.
Otra diferencia importante es que Grok 4.20 tiene acceso nativo al flujo de datos de X, lo que le da una visión muy actualizada de lo que está pasando en tiempo real: tendencias, eventos, cambios de narrativa, reacciones del mercado… Ese tipo de información, combinada con el contexto largo, le permite montar análisis más ricos en temas donde lo que importa es el “ahora”.
Dicho esto, todavía estamos ante una beta controlada, sin API abierta para todo el mundo y con acceso ligado a suscripciones concretas. Además, Perplexity y otros motores siguen teniendo su propia infraestructura de indexación web, así que la elección depende también de si priorizas tener un buscador clásico reforzado con IA o una IA multiagente con datos en tiempo real integrada en X.
Disponibilidad, API y precios esperados
Por el momento, Grok 4.20 se ofrece en modo beta cerrada para usuarios de SuperGrok y X Premium+. Para los demás, el modelo no aparece aún en el selector o lo hace con acceso restringido, y la API pública todavía no se ha abierto, aunque es de esperar que xAI la lance en una fase posterior.
Si nos fijamos en la versión anterior, Grok 4.1, xAI fijó unos precios de API bastante agresivos dentro del sector: alrededor de 0,20 dólares por millón de tokens de entrada y 0,50 dólares por millón de tokens de salida. Estos números sirven de referencia para imaginar por dónde pueden ir los tiros con Grok 4.20.
Eso sí, hay que contar con que el nuevo sistema resulta mucho más caro computacionalmente, ya que implica tener cuatro agentes funcionando en paralelo y, en muchos casos, manteniendo varias rondas de discusión interna antes de ofrecer la respuesta. Lo normal sería que la API de Grok 4.20 tenga un coste notablemente mayor que la de Grok 4.1.
Para quienes quieran experimentar con Grok en cuanto se abra la API, plataformas de agregación como APIYI (apiyi.com) prometen integrar enseguida los modelos de xAI, ofreciendo una interfaz compatible con OpenAI. Una ventaja añadida es poder comparar fácilmente precios y rendimiento frente a GPT, Claude, Gemini y otros modelos desde un mismo punto de acceso.
En paralelo, la propia xAI mantiene documentación técnica y notas de lanzamiento en sus recursos oficiales, donde va actualizando el estado de los modelos, las novedades de investigación y los cambios en las tarifas, algo recomendable seguir de cerca si tienes pensado basar proyectos serios en Grok 4.20.
Preguntas frecuentes sobre Grok 4.20
Una comparación recurrente es la de Grok 4.20 frente a GPT-5 o Claude Opus 4. Mientras que estos últimos siguen apoyándose sobre todo en un único modelo grande con mecánicas internas de cadena de pensamiento, Grok apuesta abiertamente por la colaboración explícita de cuatro agentes especializados y por la ingesta de datos frescos de X. Eso le da ventaja en tareas que exigen varios puntos de vista y en análisis de información en tiempo real.
Otro punto que genera dudas es cómo pueden los usuarios corrientes probar Grok 4.20. De momento, la única vía es a través de los planes de pago de X, seleccionando el modelo dentro de la interfaz de Grok cuando esté disponible en tu región y cuenta. Para desarrolladores, tocará esperar a que xAI libere oficialmente la API para integrarlo en aplicaciones propias o a través de proveedores terceros.
También conviene aclarar en qué se diferencia el sistema 4 Agents de una simple orquestación multi-modelo que puedas montarte tú llamando a varias APIs. En Grok 4.20, los agentes mantienen un diálogo interno estructurado, se cuestionan, se corrigen y alcanzan un consenso antes de producir la salida. No se trata solo de juntar respuestas independientes, sino de hacer que los modelos trabajen como un equipo real.
Por último, mucha gente se pregunta para qué tipo de tareas merece la pena pagar por Grok 4.20 en lugar de quedarse con un modelo más sencillo. La respuesta corta es que cobra sentido cuando el problema es lo bastante complejo como para necesitar varias perspectivas a la vez: grandes estrategias de negocio, investigación seria, programación a gran escala, análisis de inversión con datos en tiempo real, etc. Para cosas rápidas del día a día, el modo Fast suele ser más que suficiente.
Con todo lo anterior, Grok 4.20 se coloca como una de las apuestas más ambiciosas en IA generativa actual: un sistema colaborativo de cuatro agentes, entrenado con 200.000 GPUs, capaz de manejar contextos inmensos, trabajar con texto, imágenes y vídeo, y beber directamente del flujo de datos de X. Para quienes necesitan algo más que un chatbot simpático y requieren una herramienta seria para resolver problemas complejos y cambiantes, es un modelo al que merece la pena seguirle la pista muy de cerca.

Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.