- Kdump reserva un kernel de captura vía kexec para volcar
vmcoretras un pánico. - Configura bien crashkernel y la ruta de volcado para evitar fallos y duplicidades.
- Secure Boot y la falta de hueco contiguo son los errores más comunes al cargar kdump.
- Usa crash con
vmlinuxcon símbolos para un análisis profundo y fiable.

Cuando el sistema Linux sufre un cuelgue por pánico de kernel (ver diferencias entre kernel panic y system crash), la única pista fiable suele ser un volcado de memoria del núcleo. Configurar kdump y analizar vmcore con crash puede marcar la diferencia entre adivinar y diagnosticar con precisión qué ha pasado, sobre todo si el registro no deja rastro.
En esta guía práctica integro lo esencial de las mejores fuentes técnicas sobre el tema para que tengas una hoja de ruta clara: qué es kdump, cómo configurarlo sin tropiezos comunes, cómo resolver errores típicos (Secure Boot, crashkernel, rutas de guardado) y cómo sacar partido a crash para investigar el vmcore. Si te cuelga el sistema varias veces al día, aquí tienes un plan de acción realista y detallado para poner orden.
Qué son kdump y crash, y por qué importan
La funcionalidad kdump habilita un mecanismo de volcado de información del kernel ante un fallo catastrófico. Kdump reserva memoria para un segundo kernel de captura que se arranca mediante la llamada al sistema kexec cuando el kernel principal entra en pánico, y desde ahí vuelca la memoria del sistema detenido a disco.
En muchas imágenes de distribuciones empresariales, el sistema viene parcial o totalmente preparado para generar crash dumps dependiendo de la fecha de la imagen. Aun así, conviene verificar y completar la configuración para asegurar que el volcado se produce y se guarda en el lugar correcto.
La herramienta crash de Red Hat es el estándar de facto para el análisis de volcados de kernel. Crash permite inspeccionar volcados obtenidos con kdump, makedumpfile, diskdump y otros, e incluso puede trabajar sobre sistemas en ejecución usando /dev/mem o, en derivados de Red Hat, /dev/crash. Resulta más potente que usar gdb sobre /proc/kcore por las limitaciones de acceso a las estructuras internas del kernel y los requisitos del binario adecuado.
Red Hat recomienda, especialmente en entornos críticos, que los administradores actualicen y prueben periódicamente kexec-tools dentro del ciclo normal de actualización del kernel, y con más motivo cuando se estrenan nuevas funcionalidades del kernel. Esta práctica reduce sorpresas cuando más te juegas la disponibilidad del sistema.
Configuración correcta y rutas de volcado
Antes de nada, entiende qué ficheros vas a obtener. En un volcado típico, verás al menos vmcore con la memoria del kernel y archivos auxiliares como vmcore-dmesg.txt o kexec-dmesg.log, útiles para reconstruir el contexto de llamadas y mensajes previos al colapso.
Es clave definir bien dónde se guarda el volcado. Un caso típico en sistemas que montan el destino de volcado en /var/crash es terminar, sin querer, con rutas anidadas del estilo /var/crash/var/crash. Esto ocurre cuando el sistema de archivos se monta en /var/crash y además en /etc/kdump.conf se establece path /var/crash. El resultado es que el volcado cae en esa ruta duplicada.
La solución es directa: si el punto de montaje del volcado ya es /var/crash, define en kdump.conf path / en lugar de path /var/crash. Así evitas el anidamiento y tus volcados aparecerán en el directorio esperado. Comprueba con un filtro del archivo de configuración (ignorando comentarios y líneas en blanco) que las opciones activas concuerdan con el montaje real del destino.
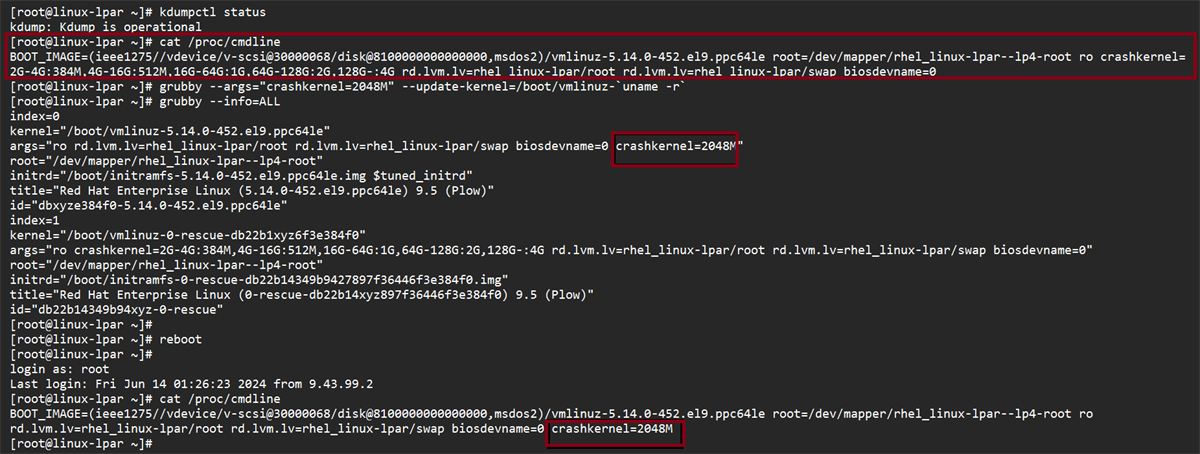
En distribuciones con GRUB, la reserva de memoria para el kernel de captura se establece con el parámetro crashkernel= en la línea de arranque. Es frecuente probar valores como crashkernel=128M, 256M, 512M o auto, y regenerar la configuración con grub2-mkconfig o update-grub según la familia de la distro. Aun así, reservar memoria no garantiza, por sí solo, que el servicio arranque si hay otros bloqueos.
En entornos Ubuntu/Debian, una secuencia típica es instalar el paquete linux-crashdump, habilitar el servicio kdump-tools y ajustar /etc/default/grub con el parámetro crashkernel= antes de update-grub. El comando kdump-config show te indica el estado: directorio de volcados (/var/crash), enlaces a vmlinuz e initrd del kernel de captura, la dirección reservada y si está listo para hacer kdump. Si ves “current state: Not ready to kdump” o “no kexec command recorded”, falta carga efectiva del kernel de captura.
Otro detalle básico para el análisis: crash necesita un binario de kernel con símbolos. El fichero adecuado para análisis es vmlinux (no comprimido, con debug symbols), mientras que vmlinuz es la versión comprimida cargada al arrancar. Sin el binario correcto, crash puede quejarse de que no encuentra el kernel arrancado y pedirá el “namelist” adecuado. Instala paquetes -dbg/-debuginfo de tu kernel para asegurar la mejor experiencia de análisis.
Problemas frecuentes, cómo resolverlos y análisis con crash
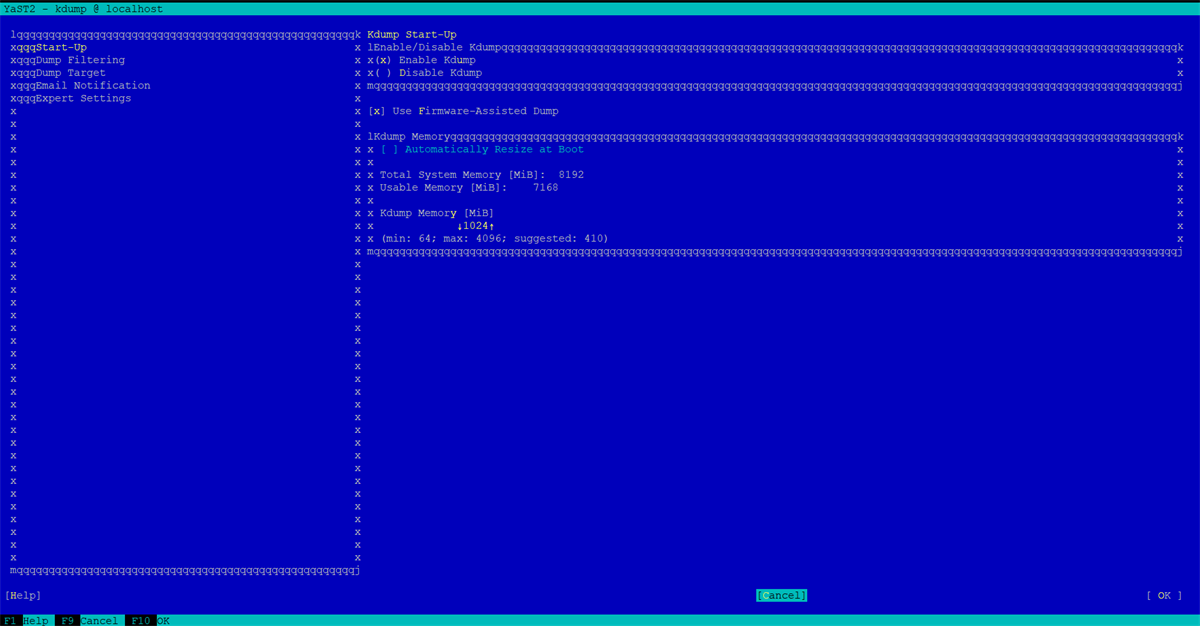
Si tras reiniciar ejecutas systemctl status kdump.service y ves que falla, lo primero es leer con calma los mensajes. Un caso real muy habitual muestra: “Secure Boot is enabled. Using kexec file based syscall” seguido de “failed to load kdump kernel”. Con Secure Boot activo, el sistema obliga a usar la variante “file-based” de kexec, que puede fallar si el kernel de captura o su initrd no están firmados como espera el firmware.
Qué revisar en ese escenario: confirma que el kernel de captura y su initrd son adecuados para Secure Boot, que el paquete kexec-tools está actualizado y que no hay módulos críticos sin firma en el initrd de kdump. Si tu flujo de seguridad lo permite, desactivar Secure Boot temporalmente para aislar el problema ayuda a distinguir si la raíz del fallo es la firma o la reserva de memoria.
En Ubuntu/Debian, otro error ilustrativo al cargar kdump es: “Could not find a free area of memory of 0x943c000 bytes… locate_hole failed”. Esto indica que no se encuentra un hueco contiguo de memoria del tamaño requerido para el kernel de captura. Las causas típicas son fragmentación de memoria, reserva insuficiente o conflictos con el layout actual.
Remedios prácticos para el “locate_hole failed” y similares:
- Reduce o ajusta la reserva: prueba con
crashkernel=256Msi estabas con 512M o viceversa; en algunos equipos, valores intermedios funcionan mejor queauto. - Arranca con menos parámetros que fragmenten la memoria al inicio, y asegúrate de regenerar GRUB tras los cambios (
grub2-mkconfigoupdate-grub). - Comprueba que los enlaces de
/var/lib/kdump/vmlinuzeinitrd.imgapuntan al kernel de captura correcto y que existe su initrd de kdump. - En equipos con dispositivos o IOMMU exigentes, valores de crashkernel con segmentos (por ejemplo, esquemas reservados por zona) pueden ayudar; si tu distro documenta perfiles predefinidos, pruébalos antes de inventar uno.
Si el servicio reporta “kdump: Starting kdump: ” y “Main process exited, status=1/FAILURE”, vuelve a lo básico: ¿se cargó realmente el kernel de captura? Ejecuta kdumpctl start o kdump-config load según tu sistema y examina la salida completa. Los mensajes sobre initrd creado, enlaces simbólicos y, acto seguido, un fallo de reserva de memoria, apuntan a la misma raíz: falta hueco contiguo del tamaño solicitado.
Recuerda además que el entorno gráfico (KDE, GNOME, etc.) no pinta nada en esta película: kdump opera a nivel de kernel y arranque. Si alguien te pregunta “cómo hacerlo funcionar en KDE”, la respuesta es que la DE no es el factor, sino el firmware (Secure Boot), el gestor de arranque, la reserva de memoria y el correcto empaquetado del kernel/initrd de captura.
Volvemos a la peculiaridad de las rutas: si ves volcados en /var/crash/var/crash, revisa /etc/kdump.conf. Cuando el objetivo de volcado está montado en /var/crash y la opción path también es /var/crash, el resultado es la ruta duplicada. Establece path / y asunto resuelto.
Una vez generes el volcado (p. ej., vmcore junto con vmcore-dmesg.txt y kexec-dmesg.log), llega el momento de usar crash. Crash carga el vmcore y el binario vmlinux con símbolos y te abre un entorno de análisis rico: puedes listar procesos, pilas de llamadas, módulos, memoria, locks, etc. Es el enfoque idóneo frente a intentar gdb con /proc/kcore, que a menudo es limitado y dependiente de cómo se compiló el kernel.
Para trabajar en un sistema que no está en producción (o tras copiar los ficheros), lanza crash indicando el vmcore y el vmlinux adecuado. Sin el vmlinux correcto el análisis cojea, porque faltan símbolos para interpretar estructuras internas. Si tu distro ofrece paquetes -debuginfo o -dbg del kernel, instálalos y usa su vmlinux correspondiente a la versión del vmcore.
Es importante entender las implicaciones de seguridad. Un vmcore contiene “todo” lo que había en memoria en el momento del colapso: datos sensibles, claves, trozos de conversaciones y cualquier cosa que estuviera viva en procesos y kernel. Por eso, la ubicación y los permisos de /var/crash y de los volcados deben tratarse con el mismo mimo que otros secretos. No los dejes accesibles a usuarios que no deban verlos.
Si no necesitas un volcado total del kernel, y el objetivo es depurar un proceso concreto, una estrategia menos invasiva es generar un volcado del proceso con herramientas como gcore. Los volcados de proceso son más pequeños y manejables, y permiten aislar casos de uso (p. ej., una app concreta que se cuelga). Eso sí, el riesgo de exponer datos sensibles del proceso sigue ahí, por lo que aplica las mismas cautelas de almacenamiento y permisos.
Para cerrar el círculo de buenas prácticas operativas: en entornos de misión crítica, asegúrate de probar kdump tras actualizar kernel y kexec-tools. Es mejor descubrir que “no arranca el kernel de captura” en una ventana de mantenimiento que en medio de un incidente real. Y documenta la ruta, retención y el procedimiento de extracción/traslado seguro de vmcore para el equipo de desarrollo o soporte.
Resumen práctico de señales y acciones:
- Estado dice “Not ready to kdump” o no registra comando kexec: falta carga del kernel de captura; revisa crashkernel, initrd de kdump y vuelve a cargar con la herramienta de tu distro.
- Secure Boot activo y “kexec file based syscall”: verifica firmas y compatibilidad del kernel/initrd de captura o prueba sin Secure Boot para aislar el fallo.
- “locate_hole failed”: ajusta tamaño de
crashkernel=y reduce fragmentación en el arranque; confirma enlaces y regeneración de GRUB. - Volcados en
/var/crash/var/crash: corrigepath /enkdump.confcuando el FS está montado en/var/crash.
Cuando todo está en su sitio, el flujo ideal es: se produce el pánico, kexec arranca el kernel de captura, makedumpfile recoge la memoria y guarda el vmcore en la ruta pactada, y tú o tu equipo abrís el caso con crash y el vmlinux correspondiente. Ese es el camino más corto entre el incidente y el aprendizaje, y el que te ahorra repeticiones del fallo sin visibilidad.
Aunque cada plataforma tiene sus matices, los fundamentos no cambian: reserva memoria suficiente y contigua, respeta las exigencias de Secure Boot cuando esté activo, alinea correctamente la ruta de volcado con el punto de montaje, y lleva siempre un vmlinux con símbolos a mano para el análisis con crash. Con estas piezas encajadas, kdump deja de ser un misterio y se convierte en tu caja negra cuando el kernel decide tomar tierra sin avisar.

Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.