- ZFS integra RAID, gestor de volúmenes y sistema de archivos con alta integridad de datos, snapshots y replicación integrada.
- mdadm ofrece un RAID por software clásico, sencillo y muy probado, que se complementa bien con LVM y sistemas de archivos tradicionales.
- El rendimiento y la fiabilidad dependen mucho del diseño del array, el tipo de discos y el uso de funciones como O_DIRECT o la caché de escritura.
- La elección entre ZFS y mdadm debe basarse en necesidades reales de rendimiento, recursos de hardware, facilidad de gestión y estrategia de copias de seguridad.
Cuando te planteas montar un servidor de almacenamiento serio en Linux, tarde o temprano aparece la duda: ¿apuesto por ZFS o tiro de mdadm con LVM y RAID tradicional? A simple vista parecen dos formas de hacer lo mismo, pero en realidad responden a filosofías muy distintas y tienen implicaciones directas en rendimiento, facilidad de gestión, fiabilidad y, por supuesto, en cómo vas a dormir de tranquilo cuando un disco empiece a fallar.
En este artículo vamos a desgranar con calma las diferencias entre ZFS y mdadm (Linux Software RAID), repasando casos reales, puntos fuertes y débiles de cada solución, cómo se comportan con distintos niveles RAID (RAID0, RAID1, RAID5/6, RAID10, RAIDZ1/Z2…), qué pasa con las copias de seguridad, la corrupción silenciosa de datos, el uso de RAM o CPU y hasta cómo afectan los modos de caché como O_DIRECT en entornos de virtualización.
Qué es RAID y por qué nos importa al comparar ZFS y mdadm
Antes de meternos en harina con ZFS y mdadm, conviene recordar qué resuelve exactamente un RAID y qué cosas no resuelve, por mucho que a veces se confundan con copias de seguridad. RAID significa “Redundant Array of Independent Disks” y su objetivo original era juntar varios discos pequeños en una sola unidad lógica que ofrezca más rendimiento, más capacidad útil, o redundancia frente a fallos físicos.
Un RAID puede combinar distintas técnicas como striping (repartir los datos en bloques entre varios discos), mirroring (espejado) y paridad. Según cómo mezcles estas piezas obtienes niveles RAID distintos: RAID0 prioriza el rendimiento, RAID1 la copia exacta en otro disco, RAID5/6 paridad distribuida para equilibrar espacio y tolerancia a fallos, RAID10 mezcla mirroring y striping, etc.
La clave es entender que RAID aumenta la disponibilidad y reduce el impacto de que se muera un disco, pero no sustituye un buen sistema de copias de seguridad. Puedes perder datos por corrupción lógica, borrados accidentales, ransomware o un fallo catastrófico de varios discos, y el RAID no te va a salvar de eso.
Además, no todos los RAID se implementan igual: hardware RAID con controladoras dedicadas, software RAID integrado en el kernel (mdadm), y soluciones híbridas tipo ZFS o Btrfs que combinan gestor de volúmenes y sistema de archivos en una sola capa.
ZFS: sistema de archivos y gestor de volúmenes en un solo paquete
ZFS no es simplemente “otro tipo de RAID”: es un sistema de archivos de 64 bits con gestor de volúmenes integrado. Eso significa que, a diferencia de mdadm, no solo agrupa discos, sino que también sabe cómo se almacenan los datos a nivel de bloques y de metadatos, y puede tomar decisiones inteligentes sobre integridad, cachés, snapshots o compresión.
En ZFS creas un pool de almacenamiento (zpool) formado por uno o varios vdevs. Cada vdev puede ser un conjunto de discos en RAIDZ1, RAIDZ2, espejos, etc. Los niveles RAID clásicos están ahí, pero con otros nombres: RAIDZ1 se parece a un RAID5, RAIDZ2 a un RAID6 y los espejos de ZFS equivalen a un RAID1 o combinaciones tipo RAID10 cuando se usan múltiples vdevs en espejo.
Una vez tienes el zpool, ZFS monta automáticamente el sistema de archivos asociado. No hay que crear un dispositivo de bloque, luego un LVM, luego un sistema de archivos aparte. Puedes crear datasets y zvols (volúmenes en bloque) dentro del pool, con cuotas, compresión o propiedades diferentes para cada uno.
Uno de los puntos fuertes clave de ZFS es su modelo de copy-on-write (COW): nunca sobrescribe bloques en sitio, sino que escribe la nueva versión en un bloque diferente y actualiza los metadatos al final. Esto ayuda a evitar el clásico problema del “write hole” en RAID5/6, donde un corte de luz durante una escritura deja la paridad en estado inconsistente.
Además, ZFS incorpora de serie funcionalidades que en el mundo mdadm/LVM/EXT4 tendrías que montar con varias capas adicionales, como snapshots ligeros, clones, compresión transparente, desduplicación, scrubbing de datos con checksums y cachés avanzadas. Los zvols se integran muy bien con hipervisores para almacenamiento de VM.

mdadm y LVM: el RAID software clásico en Linux
mdadm es la utilidad estándar en Linux para gestionar MD RAID (también llamado Linux Software RAID). Trabaja a nivel de bloques, sin meter un sistema de archivos de por medio. Con mdadm creas un dispositivo /dev/mdX que agrupa varios discos físicos o particiones, y encima de ese dispositivo ya pones el sistema de archivos que quieras (EXT4, XFS, etc.) o un LVM.
La filosofía aquí es modular: mdadm se encarga del RAID, LVM de los volúmenes lógicos y el sistema de archivos solo se ocupa de almacenar datos. Esto da mucha flexibilidad, pero también implica más capas y más cosas que configurar a mano (fstab, scripts de arranque, políticas de monitorización, etc.).
La sintaxis básica de mdadm sigue una estructura bastante lógica: mdadm dispositivo. Los modos más habituales son --create para crear un RAID nuevo, --assemble para ensamblar uno ya existente, --manage para gestionar un array activo, --grow para ampliar, y --detail para ver información.
Por ejemplo, crear un RAID1 con dos discos sería algo como mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sda1 /dev/sdb1. Si el array ya existe y hay que montarlo tras un reinicio, se usaría --assemble indicando el dispositivo RAID y los discos miembro.
Para configuraciones más avanzadas, mdadm se suele combinar con LVM, de forma que el RAID proporciona un gran bloque de almacenamiento y LVM permite dividirlo en múltiples volúmenes lógicos de distintos tamaños, sobre los que luego se montan sistemas de archivos y se dan a servicios, máquinas virtuales, etc.
Diferencias clave entre ZFS y mdadm: arquitectura y funciones
La primera gran diferencia está en que ZFS integra RAID, gestor de volúmenes y sistema de archivos, mientras que mdadm solo se ocupa de la parte de RAID por software. Esto tiene un impacto directo en el tipo de cosas que puedes hacer de forma “nativa” con cada solución.
En mdadm, si quieres snapshots, clonado de volúmenes o aprovisionamiento thin para máquinas virtuales, tienes que tirar de LVM-thin, sistemas de archivos con snapshots (como Btrfs) o capas adicionales. ZFS trae todo eso de serie: cualquier dataset puede tener snapshots instantáneos y clones en cuestión de segundos, y los zvols se integran muy bien con hipervisores para almacenamiento de VM.
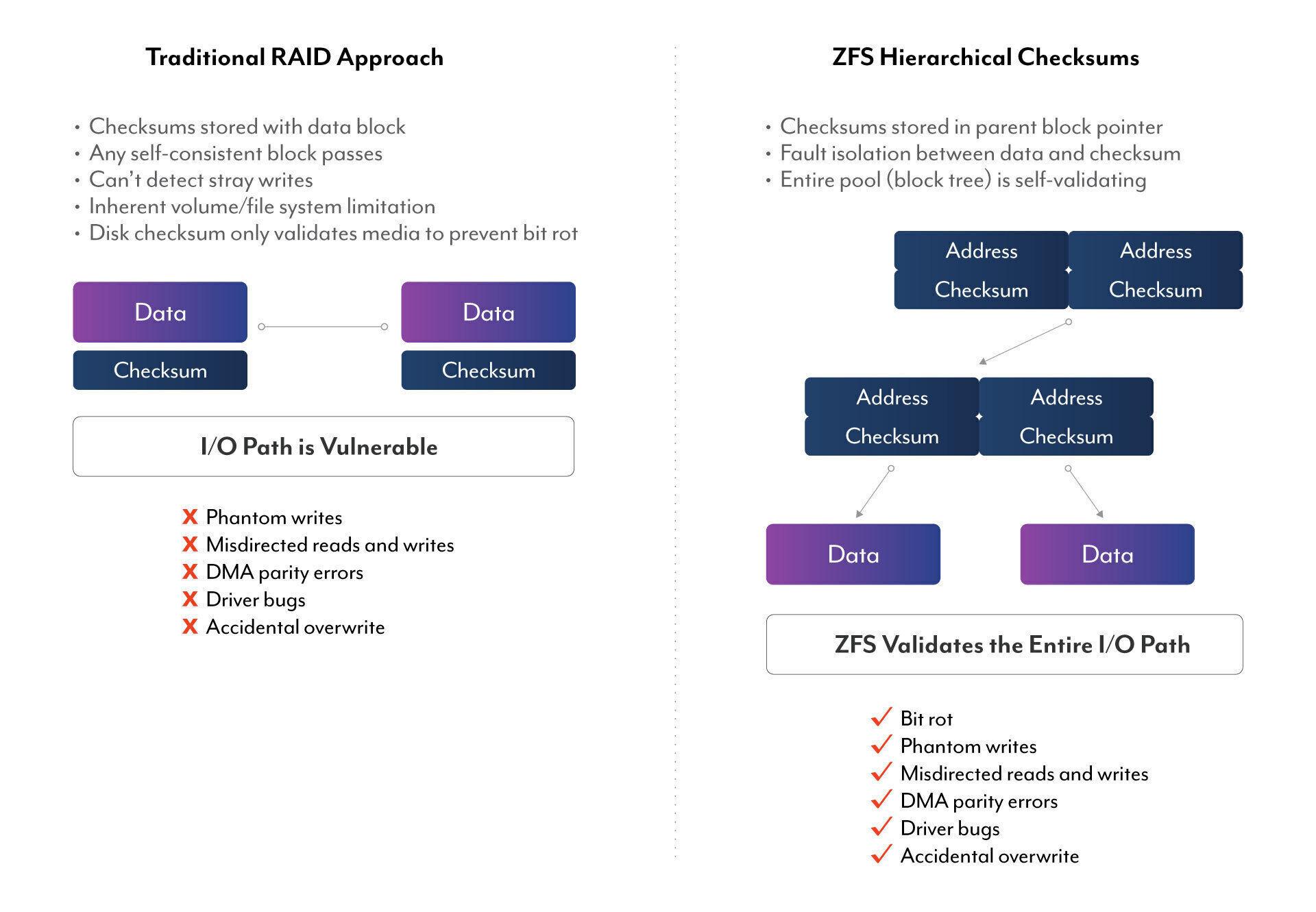
Otra diferencia importante es la integridad de datos. mdadm protege contra fallos de disco gracias al RAID, pero no controla lo que pasa dentro del sistema de archivos ni añade checksums a nivel de bloque de datos. ZFS, en cambio, calcula checksums para todos los bloques de datos y metadatos, y durante los scrubs comprueba que lo leído coincide con lo esperado, corrigiendo desde otro disco si detecta corrupción silenciosa.
También cambia mucho la forma de ampliar o gestionar el almacenamiento. En mdadm puedes crecer ciertos niveles RAID añadiendo discos y luego redimensionando LVM y el sistema de archivos, pero es un proceso delicado y relativamente lento. ZFS permite añadir nuevos vdevs al zpool para incrementar capacidad; eso sí, cada vdev tiene su propia configuración RAID y la distribución de datos se hace a nivel de vdev, algo que hay que tener en cuenta al diseñar el pool.
Por último, la gestión cotidiana es diferente: ZFS dispone de comandos muy coherentes y descriptivos (zpool, zfs), mientras que mdadm tiene una CLI potente pero a veces poco intuitiva, y además dependes de ficheros como /etc/mdadm.conf y /etc/fstab para que todo monte bien al arrancar.
Rendimiento: RAID10, RAID5/6, RAIDZ y casos reales
En el terreno del rendimiento no hay una única respuesta ganadora, porque depende muchísimo del tipo de discos (HDD, SATA SSD, NVMe), del nivel RAID y del patrón de acceso (secuencial vs aleatorio, lecturas vs escrituras, tamaño de bloque, etc.). Aun así, hay patrones bastante claros.
En discos duros clásicos y SSD SATA, ZFS suele rendir muy bien. Su diseño por copy-on-write y su forma de agrupar IO tiende a convertir muchas operaciones aleatorias en secuenciales, algo que encaja genial con la mecánica de los discos mecánicos. Además, puede apoyarse en RAM, L2ARC (caché de lectura en SSD) y ZIL/SLOG (registro de intención de escritura) para suavizar picos y mejorar latencias.
Sin embargo, cuando todo el almacenamiento principal son NVMe rápidos, ZFS no siempre exprime el 100 % del potencial. Fue diseñado en una época donde la latencia de los discos daba margen de sobra para hacer cálculos en CPU mientras se esperaba al disco; con NVMe, la CPU a veces se convierte en el cuello de botella y se ven rendimientos por debajo de lo que daría un solo NVMe “a pelo”.
En cuanto a mdadm, los tests reales muestran que ofrece un rendimiento sólido, especialmente en RAID0, RAID1 y RAID10, pero puede quedarse por detrás de hardware RAID y de ZFS en algunos escenarios con RAID5/6 por software, especialmente en escrituras intensivas donde el cálculo de paridad y el journaling penalizan más.
Hay casos de uso reales donde un gran RAID10 con mdadm (por ejemplo, 16 discos de 2 TB en RAID10 midiendo más de 1 GB/s de throughput teórico) no alcanza esas cifras en usos prácticos (tráfico real, copias a través de 10GbE, etc.). La teoría dice una cosa, pero la pila completa (protocolo de red, CPU, sistema de archivos, cachés) a menudo limita el rendimiento final por debajo del máximo bruto del array.
Fiabilidad y problemas típicos: write hole, O_DIRECT y corrupción silenciosa
Más allá de las cifras de MB/s, lo que realmente marca la diferencia entre ZFS y mdadm es cómo manejan los fallos y los escenarios “feos”: cortes de luz durante escrituras, corrupción silenciosa, bugs de kernel o aplicaciones que usan modos de acceso directos al disco.
El famoso RAID write hole afecta a implementaciones de RAID5/6 donde un corte de energía puede dejar una escritura de datos y su paridad a medias, provocando incoherencias internas difíciles de detectar. Las controladoras de hardware RAID lo mitigan con caché de escritura protegida por batería (BBU), y ZFS lo esquiva gracias a su modelo COW, que solo considera válida la nueva versión de los datos cuando todo se ha escrito correctamente.
mdadm, en el mundo Linux, se apoya en mecanismos como journaling y bitmaps para reducir el riesgo, pero sigue siendo más vulnerable a estos escenarios que ZFS o un buen hardware RAID con caché protegida. Esto se nota tanto en fiabilidad como en rendimiento en cargas de escritura intensivas, donde el journaling recae directamente sobre discos lentos.
Otro tema delicado es el uso de O_DIRECT (caché “none” en VMs) en entornos de virtualización. Cuando una máquina virtual accede al almacenamiento con acceso directo al dispositivo, el RAID software (md/dm) puede terminar reenviando el mismo puntero de memoria como varias escrituras independientes a cada disco. Si otro hilo modifica la memoria mientras las escrituras están en curso, cada disco puede acabar grabando contenido distinto, degradando o corrompiendo el RAID.
Se ha documentado incluso un caso real donde una escritura a swap en progreso coincide con la liberación de esa memoria: la entrada de swap se descarta mientras el IO sigue en marcha, y el RAID termina marcando el array como degradado. Técnicamente O_DIRECT promete “intentar minimizar el efecto de las cachés”, no romper la coherencia entre réplicas, pero en la práctica es un modo en el que hay que tener mucho cuidado con MD RAID.
Si evitas ese modo de caché en VMs, o sabes exactamente lo que haces, mdadm es perfectamente válido, pero consumes algo más de RAM. Con ZFS, en cambio, el control de la caché y del flujo de IO está mucho más integrado en la pila del sistema de archivos, y el riesgo de estos escenarios se reduce notablemente.
Casos prácticos: de grandes RAID10 a pools sin redundancia para VM
Para ver la diferencia filosófica entre ZFS y mdadm, viene muy bien revisar escenarios reales de uso que reflejan dudas habituales de administradores y usuarios avanzados.
En un primer caso, alguien tiene un servidor con Ubuntu y 16 discos de 2 TB en RAID10 usando mdadm. La velocidad bruta es excelente, pero se encuentra con un problema de fiabilidad concreto: después de algunos reinicios, la matriz no sube bien, hay que desmontarla y recrearla una y otra vez. Justo el tipo de situación que el RAID se supone que debe evitar.
Parte del riesgo viene de que el RAID10, tal y como está montado, no tolera que se caigan dos discos consecutivos que dejen una franja completa sin datos. Ese es el talón de Aquiles del diseño concreto: se cumple la condición teórica de fallo que el RAID10 no puede gestionar, y la matriz deja de ser recuperable de forma limpia.
En esa situación se barajan opciones como pasar a RAID50 (5 stripes de RAID5 de 3 discos cada uno, más un spare) o RAID60 (2 stripes de RAID6 de 8 discos). Y surge también la idea de migrar todo a ZFS con configuraciones equivalentes: cinco vdevs RAIDZ1 de 3 discos (con un disco de repuesto) o dos vdevs RAIDZ2 de 8 discos, buscando un compromiso entre rendimiento y tolerancia a fallos.
La conclusión lógica es que, con tantos discos, el diseño del layout es tan importante como la tecnología elegida. Un mayor número de vdevs suele dar más IOPS y throughput, pero también aumenta la complejidad a la hora de gestionar fallos; un par de vdevs grandes RAIDZ2 refuerzan la tolerancia a fallos, pero pueden ser algo menos ágiles en ciertas cargas.
En otro ejemplo, un administrador quiere montar un pool de datos para discos de trabajo de máquinas virtuales donde la prioridad absoluta es exprimir los 4 TB de capacidad y conseguir buen rendimiento, sin preocuparse demasiado por la redundancia, ya que las VM se respaldan fuera del nodo en otro almacenamiento, incluso fuera del sitio.
La decisión está entre montar un pool ZFS en RAID0 o un stack basado en LVM-thin sobre mdadm RAID0. Ambos permiten snapshots y aprovisionamiento thin para VMs, perfectos para backups online en plataformas tipo Proxmox. En este caso, la típica recomendación “no uses RAID0 en producción” se relativiza, porque la recuperación ante desastre se basa en backups externos, no en la resiliencia local.
Quien decide tiene mucha experiencia en ZFS, pero apenas ha tocado mdadm/LVM. El dilema aquí no es tanto de fiabilidad (que ya está cubierta por backups) como de comodidad de gestión diaria, integración con la plataforma y rendimiento sostenido en cargas de virtualización.
Hardware RAID frente a ZFS y mdadm: CPU, caché y portabilidad
En la comparativa tampoco se puede ignorar el papel del hardware RAID con controladoras dedicadas, muy presentes en servidores de marca (Dell, HP, etc.). Una tarjeta tipo Dell H710P (como muchas controladoras LSI) lleva su propio procesador, memoria caché (a menudo 1 GB) y BBU para garantizar que las escrituras en caché sobreviven a un corte de luz.
La gran ventaja del hardware RAID es que el sistema operativo solo ve un disco lógico, lo cual simplifica mucho la compatibilidad y permite usar prácticamente cualquier sistema operativo sin preocuparse de configuraciones complejas de RAID por software. Además, la CPU central apenas se entera del trabajo de paridad e IO pesado, porque la controladora se lo come todo.
Pero a cambio, te casas con esa controladora: si se rompe, a menudo necesitas exactamente el mismo modelo para poder recuperar el array. Con software RAID como mdadm o con ZFS, basta con mover los discos a otro servidor con Linux y las herramientas necesarias; el array se puede detectar y ensamblar sin demasiados dramas.
Otro problema práctico de las controladoras es la dependencia de herramientas de gestión y utilidades de fabricante, que no siempre están bien mantenidas para distribuciones modernas. Suelen traer un entorno de configuración previo al arranque (BIOS/UEFI de la controladora), pero en placas base de consumo a veces ni siquiera se detecta correctamente el hardware.
En cuanto a rendimiento, en pruebas con ocho WD Red Plus de 4 TB en RAID6, el hardware RAID suele ofrecer las mejores tasas secuenciales de lectura y escritura, seguido de cerca por ZFS, y dejando a mdadm en último lugar, especialmente en escrituras complejas. La razón probable es que ZFS y hardware RAID solucionan el write hole y aprovechan cachés rápidas, mientras que mdadm depende casi totalmente de los discos físicos para journaling y reconstrucciones.
Consumo de recursos: RAM, CPU y swap
Uno de los comentarios más repetidos sobre ZFS es que “le encanta la RAM”. Y es cierto: cuanta más memoria tenga para ARC (Adaptive Replacement Cache), mejor puede cachéar lecturas y mejorar rendimiento. En servidores serios se recomienda además usar memoria ECC, para que ZFS no tenga que lidiar con errores de RAM que podrían corromper la integridad de sus checksums.
En cuanto a CPU, ZFS consume algo más que mdadm, sobre todo si activas compresión, desduplicación o usas muchas funcionalidades avanzadas. Sin embargo, con CPUs modernas, este coste suele ser perfectamente asumible en la mayoría de entornos domésticos y de pequeña empresa, sobre todo comparado con el valor añadido de integridad de datos y snapshots.
Hay que mencionar también que ZFS no es buena idea para gestionar swap. Se puede producir una especie de carrera: baja la RAM disponible, el sistema quiere usar más swap, ZFS trata de crecer su ARC o administrar más metadatos, lo que consume más RAM todavía, y entras en un bucle desagradable. Por eso es habitual que, en servidores donde todo el almacenamiento de datos está en ZFS, se mantenga un pequeño RAID1 con mdadm solo para swap y quizá el sistema base.
En el lado de mdadm, el consumo de RAM es más modesto, ya que la mayor parte de la inteligencia de caché la asume el sistema de archivos que pongas encima (por ejemplo EXT4 o XFS). La CPU también sufre menos con mdadm puro, aunque con RAID5/6 el cálculo de paridad siempre va a tener un coste, sea software u hardware.
En cualquier caso, las pruebas muestran que incluso con CPUs veteranas tipo dual-Opteron, los picos de CPU durante reconstrucciones de RAID por software no suelen ser catastróficos; es raro que sean el cuello de botella absoluto frente a la velocidad de los discos.
Facilidad de administración diaria y curva de aprendizaje
Para alguien que llega de cero, mdadm puede parecer intimidante por su sintaxis, pero en cuanto te aprendes cuatro comandos básicos, gestionar RAID1 y RAID10 se vuelve relativamente sencillo. Lo mismo con LVM: la primera vez cuesta, luego ya te mueves con soltura entre volúmenes físicos, grupos de volúmenes y volúmenes lógicos.
ZFS, por su parte, tiene más conceptos nuevos al principio: pools, vdevs, datasets, zvols, ARC, L2ARC, ZIL/SLOG, propiedades, snapshots, scrubs…. La curva de aprendizaje es más pronunciada, pero a cambio, muchas tareas comunes (crear un nuevo dataset con compresión, tirar un snapshot, replicar datos a otro servidor) se resuelven con un par de comandos muy coherentes.
En administración diaria, ZFS se gana a muchos administradores porque su CLI está pensada como un todo coherente. Comandos como zpool status, zpool scrub, zfs list, zfs snapshot o zfs send | zfs recv cubren la mayoría de acciones con poco esfuerzo. Con mdadm y LVM, las acciones se reparten entre varias herramientas y ficheros de configuración dispersos.
Otro punto fuerte de ZFS es la replicación de backups. La combinación de snapshots con zfs send/recv permite enviar flujos incrementales de datos a otro servidor ZFS de forma muy eficiente, copiando solo bloques cambiados. Para un entorno con varios NAS o servidores, es una delicia tener esa capacidad integrada.
Con mdadm y sistemas de archivos tradicionales, también puedes montar replicación (rsync, herramientas de snapshot de LVM, soluciones de backup especializadas, etc.), pero nada tan estrechamente acoplado a la lógica del sistema de archivos como ZFS.
En la parte de arranque y montaje automático, hay que recordar que un RAID mdadm no se monta solo después de un reinicio si no lo declaras correctamente en /etc/mdadm.conf y /etc/fstab. Lo mismo con los sistemas de archivos que pongas encima. En ZFS, el propio sistema se encarga de montar datasets según sus propiedades, lo cual simplifica un poco el puzzle.
Vistas todas estas piezas, se ve claramente que mdadm brilla cuando quieres un RAID por software clásico, sencillo y muy integrado en Linux, especialmente en configuraciones RAID1/10 o cuando tienes restricciones de RAM y quieres algo sobrio y probado. ZFS, en cambio, se siente como el “todo en uno” ideal cuando te importa tanto la integridad de los datos como la flexibilidad para hacer snapshots, clonar, comprimir y replicar sin depender de mil herramientas externas.
En entornos con mucha carga de trabajo sobre discos mecánicos o SATA, ZFS suele ofrecer un rendimiento estupendo, y si le añades NVMe como caché L2ARC o como vdev “especial” para metadatos y ficheros pequeños, puede escalar muy bien. Donde puede defraudar ligeramente es en configuraciones muy simples sobre NVMe puros, donde otros enfoques o incluso discos independientes con buenos backups pueden ofrecer más chicha por menos complejidad.
Para situaciones en las que el máximo rendimiento absoluto manda y la redundancia local no es crítica, a veces tiene más sentido usar discos independientes, automatizar backups frecuentes y olvidarse de RAID para esa parte concreta. En el resto de casos, la elección entre ZFS y mdadm pasa por sopesar experiencia previa, recursos de hardware disponibles y cuánto valoras la comodidad de tenerlo todo integrado frente a la sencillez y sobriedad del RAID software clásico.

Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.