- Las crisis informáticas combinan fallos de ciberseguridad y tensión en el mercado de hardware, con un impacto global creciente.
- El auge de la IA ha disparado la demanda de GPU, DRAM y almacenamiento, encareciendo y escaseando el hardware de consumo.
- Errores de respuesta ante incidentes (borrar evidencias, ignorar protocolos, ocultar brechas) agravan los daños económicos y legales.
- Casos como el fallo de CrowdStrike evidencian la vulnerabilidad sistémica y la necesidad de planes sólidos de continuidad y comunicación.

Las crisis informáticas se han convertido en uno de los grandes puntos débiles de empresas, administraciones públicas y servicios críticos en todo el mundo. Lo que antes eran caídas puntuales hoy puede provocar parones masivos en aerolíneas, bancos, hospitales o gobiernos enteros en cuestión de minutos, con daños económicos y reputacionales brutales.
Además, en paralelo a estos fallos y ciberataques, se está produciendo una tormenta perfecta en el mercado del hardware: el auge de la inteligencia artificial, la falta de capacidad productiva de chips y los errores de software a gran escala (como el caso CrowdStrike) están demostrando lo frágil que es la infraestructura digital de la que dependemos a diario.
Qué es una crisis informática y por qué ahora son tan dañinas
Cuando hablamos de crisis informática nos referimos a episodios en los que un fallo tecnológico, un ciberataque o una actualización defectuosa provoca una interrupción seria de los sistemas de una organización o incluso a nivel global. Estas crisis tienen causas muy concretas, pero efectos en cascada que pueden extenderse durante horas o días, una dinámica que se entiende mejor si se considera cómo y cuándo el software se convirtió en producto.

En los últimos años hemos visto crisis de distinto origen pero con algo en común: la enorme dependencia tecnológica. Desde los desajustes provocados por la pandemia en la cadena de suministro de chips entre 2020 y 2023, pasando por la burbuja de las criptomonedas que disparó el precio de las GPU, hasta la actual ola de demanda de inteligencia artificial que está tensionando todo el ecosistema de hardware.
A todo esto hay que sumarle las tensiones geopolíticas, los desastres naturales y la concentración de proveedores que fabrican chips o prestan servicios críticos en la nube. Un apagón de una gran plataforma de ciberseguridad o un fallo en un hiperescalador de cloud ya no afecta solo a una empresa: puede tumbar medio planeta digital en cuestión de minutos.
El resultado es un escenario en el que los incidentes tecnológicos ya no son anecdóticos, sino que se han convertido en un riesgo estructural para la economía y la sociedad. La cifra de pérdidas por cibercrimen y crisis informáticas ronda los billones de dólares a escala global, si se suman tanto los daños directos como los intangibles (reputación, pérdida de confianza, multas regulatorias, etc.).
La nueva crisis: IA, hardware al límite y burbuja latente
En la actualidad, uno de los motores centrales de la crisis tecnológica es el boom de la inteligencia artificial generativa. En muy pocos años, proveedores como OpenAI, DeepSeek y otros actores han llevado la IA al centro del negocio de miles de compañías, que ahora quieren integrar modelos en prácticamente todos sus procesos, lo que hace que la figura del auditor de algoritmos de IA sea cada vez más relevante.
La IA se ha vendido casi como una solución mágica para cualquier problema, y esto ha desatado una fiebre de inversión en modelos, infraestructuras y servicios en la nube. Lo que al principio parecía un espejismo ligado al alza de empresas como NVIDIA se ha consolidado como un mercado gigantesco, que demanda recursos técnicos a un ritmo que la industria de chips no puede seguir cómodamente. Además, la adopción masiva ha reforzado la necesidad de contar con profesionales como el especialista en ética de la inteligencia artificial.
Este crecimiento acelerado está generando una burbuja en torno al hardware de alto rendimiento. Muchos analistas coinciden en que no solo estamos ante un cambio de paradigma tecnológico, sino ante una distorsión profunda en el mercado de componentes: gran parte del stock se está desviando a centros de datos de IA, dejando al usuario doméstico y a las pymes en segundo plano.
El problema no es únicamente de precios altos; también es un tema de desigualdad en el acceso a la capacidad de cómputo. Quien no pueda pagar GPU, memoria y almacenamiento a los nuevos precios, se queda atrás en competitividad, y eso afecta directamente a la transformación digital de muchas empresas.
Los centros de datos de IA y su voracidad de recursos
Detrás de cada modelo de IA hay centros de datos hiper-especializados que requieren cantidades brutales de cómputo, memoria, almacenamiento y energía. Desde 2026, con el auge de los modelos generativos gigantes y el edge computing, los data centers tienen que gestionar cargas de trabajo masivas y muy variables, y en muchos casos emplean gemelos digitales para simular y planificar esas cargas.
El corazón de estos entornos son las unidades de procesamiento acelerado: GPUs de gama altísima y aceleradores específicos como TPUs de Google, NVIDIA H100/Blackwell o AMD Instinct. Estos chips están optimizados para trabajar con enormes volúmenes de operaciones de precisión relativamente baja, justo lo que exigen los modelos de aprendizaje profundo. Ejecutar estas cargas en CPU convencionales sería mucho más caro y menos eficiente.
Pero el cómputo no llega solo: cada acelerador necesita cantidades enormes de memoria. Además de la RAM del servidor, se utilizan chips DRAM de alto rendimiento y memorias HBM (High Bandwidth Memory) para servir como VRAM a las GPU. Esta combinación está literalmente arrasando con toda la producción disponible de memoria para muchos fabricantes.
En paralelo, estos centros también necesitan almacenamiento masivo y redes ultrarrápidas. Los datasets de entrenamiento y los modelos ocupan decenas o cientos de terabytes, lo que dispara el uso de SSD NVMe y discos HDD de alta capacidad, junto con redes de 100/200/400 Gbps sobre Ethernet o Infiniband para unir clústeres de cómputo y almacenamiento sin cuellos de botella.
Todo este ecosistema conlleva una demanda energética descomunal. Las compañías eléctricas y los reguladores ya miran con recelo cómo crece el consumo eléctrico de los data centers de IA, porque amenaza con tensionar redes, encarecer la energía y complicar objetivos medioambientales.
Cómo la crisis golpea al mercado de las GPU
El segmento donde más se nota esta tormenta es el de las tarjetas gráficas y aceleradores. Las GPU han sido el epicentro de varias crisis: primero por el minado de criptomonedas y ahora por la IA. Cada vez que se dispara una nueva ola de demanda, el mercado de consumo (gaming, creación de contenido, estaciones de trabajo pequeñas) se queda seco.
Los fabricantes y diseñadores de GPU han visto que el negocio empresarial y de centros de datos es mucho más rentable que el mercado doméstico. En consecuencia, se han volcado en producir modelos para IA y servidores, relegando las gamas orientadas a PC de sobremesa y portátiles. Esto deja a los usuarios con menos variedad, stocks muy limitados y precios inflados.
El problema es doble: por un lado, sube la demanda de GPU de alto rendimiento para IA; por otro, las fábricas redirigen recursos para servir a este segmento, reduciendo la producción para consumo. El resultado es que las pocas unidades orientadas a gaming o trabajo profesional tradicional se venden a precios prohibitivos, y muchos usuarios se resignan a aguantar hardware viejo o recurrir al mercado de segunda mano.
La memoria RAM y DRAM, en el ojo del huracán
Desde finales de 2025 se viene registrando una tensión enorme en el mercado de la memoria DRAM. No solo afecta a los módulos de RAM de PC, sino también a la memoria de móviles, Smart TV, routers, consolas y un sinfín de dispositivos conectados. El culpable principal, de nuevo, es el apetito voraz de la IA.
Gigantes como Samsung Electronics, SK Hynix y Micron Technology han reorientado buena parte de su capacidad hacia DRAM de servidor y memorias HBM para GPU de IA. Esto ha dejado al mercado tradicional de consumo y OEM con menos suministro, provocando escasez y una escalada histórica de precios. Se han llegado a ver kits de DDR5 de altas frecuencias por varios miles de euros en el canal retail.
Esta situación ha tenido efectos colaterales dolorosos. Un ejemplo claro es la desaparición de la marca Crucial como línea de productos de memoria y SSD de consumo: Micron anunció que abandonaba esa marca desde febrero de 2026 para centrarse en otros segmentos más rentables.
Hay que recordar que el mercado DRAM es profundamente cíclico. Tras fases de sobreproducción, los precios se hunden y los fabricantes recortan gasto y capacidad. Justo cuando muchos habían cerrado el grifo tras un ciclo de precios bajos, llegó el boom de la IA, pillando a la industria con menor capacidad de la necesaria y agravando la crisis.
SSD, HDD y el problema del almacenamiento masivo
El almacenamiento tampoco se libra. La expansión de IA y de los servicios en la nube ha generado una presión brutal sobre las unidades SSD y los discos duros tradicionales. Primero fue el turno de GPU y DRAM, pero poco después empezó a sentirse la escasez de ciertos modelos de SSD y HDD, especialmente los que usan también los centros de datos.
En contra de lo que podría pensarse, no solo se disparan las ventas de SSD NVMe de alto rendimiento. Los data centers necesitan también enormes «graneros» de datos para almacenamiento en frío o nearline, donde los HDD de gran capacidad siguen siendo imbatibles en precio por terabyte. Para datasets históricos o copias de seguridad, el rendimiento extremo no es tan crítico como el coste.
Los fabricantes de NAND flash como Samsung, SK Hynix o Micron veían de un periodo de sobreoferta, en el que habían limitado capacidad para frenar la caída de precios. La llegada repentina de la demanda de IA mientras la producción estaba ajustada ha provocado tensiones de suministro y subidas importantes de precios, especialmente en SSD empresariales de alta densidad.
En el mundo de los HDD, empresas como Western Digital o Seagate se han encontrado con que gran parte de sus unidades ya están comprometidas para grandes proyectos de data center. De hecho, algunas compañías han comunicado que tienen toda su producción futura ya asignada, dejando muy poco margen para el canal general.
Impacto en precios y en el bolsillo del usuario
Todo este cóctel ha provocado que 2026 sea uno de los años más duros para el usuario final en cuanto a precios de hardware. Montar o actualizar un PC se ha vuelto un lujo, y las subidas no se limitan a gamers o entusiastas: se extienden a todo tipo de dispositivos que utilizan DRAM y NAND.
Smartphones, routers, televisores inteligentes, portátiles de gama media… prácticamente todo lo que integra memoria o almacenamiento ha sufrido incrementos de coste llamativos. Muchas personas directamente han renunciado a renovar equipos, y otras han optado por mirar el mercado de segunda mano o marcas alternativas de países emergentes.
Ante el vacío dejado por algunos grandes fabricantes en el segmento de consumo, están entrando nuevos actores chinos que buscan hacerse un hueco con chips DRAM y NAND más asequibles. Empresas como CXMT (ChangXin Memory Technologies) han logrado producir módulos DDR5-8000, mientras que YMTC (Yangtze Memory Technologies) ofrece NAND de alta densidad con tecnologías como Xtacking 4.0, alcanzando SSD de hasta 8 TB.
Marcas como Netac, Asgard, KingBank o Gloway ya integran estos chips en sus productos. Sin embargo, aún no han conseguido convencer a gigantes del sector como Kingston o Corsair, que se muestran cautos a la hora de basar su catálogo en estos proveedores por cuestiones de fiabilidad percibida, soporte a largo plazo o posibles restricciones comerciales.
En medio de esta situación, no faltan ideas extremas: incluso se han visto iniciativas en países como Rusia donde se plantean montar módulos de RAM «DIY» de forma artesanal para paliar la escasez y el coste.
Cuándo podría relajarse esta tensión de mercado
Los informes de consultoras como TrendForce e IDC apuntan a que el gran cuello de botella actual no está tanto en las materias primas como en la falta de capacidad fabril. Construir nuevas plantas de semiconductores (fabs) es un proceso carísimo y lento, que puede tardar fácilmente entre tres y cinco años desde que se toma la decisión hasta que salen los primeros chips comerciales.
Las previsiones más prudentes señalan que a finales de 2026 podríamos empezar a notar cierta estabilización de precios, en el sentido de que dejarán de subir de forma tan agresiva. Es decir, entraríamos en una fase de meseta en la que la demanda de IA se modere un poco y las nuevas líneas vayan entrando en producción.
Para 2027 algunas fábricas importantes, como la nueva planta de Micron en Singapur o las ampliaciones de SK Hynix en Corea, deberían estar ya operativas, aumentando la producción de DRAM y NAND. Si el boom de la IA pierde algo de fuerza, podríamos ver un equilibrio más razonable entre oferta y demanda.
Muchos analistas incluso contemplan que, hacia 2028, se produzca una corrección fuerte: si la capacidad productiva crece mucho y la demanda se ralentiza, los precios podrían desplomarse hasta niveles similares o inferiores a 2023, con auténticas gangas en RAM, SSD y GPU de generaciones anteriores.
El coste real de una crisis informática: números y reputación
Más allá del hardware, las crisis informáticas ligadas a ciberataques y fallos de seguridad dejan cifras escalofriantes. El Centro de Estudios Internacionales y Estratégicos de Estados Unidos estimó que solo en 2020 las pérdidas por incidentes vinculados al cibercrimen superaron los 945.000 millones de dólares en ese país, casi el doble que en 2018.
Si a estas pérdidas directas se suman los daños reputacionales, la pérdida de confianza de los clientes y socios, y el impacto a medio plazo en la marca, la factura total puede superar holgadamente los dos billones de dólares. En países como España, el crecimiento de los ciberdelitos en los últimos años se sitúa por encima del 130%, lo que refleja un entorno cada vez más hostil.
En este contexto, organizaciones especializadas en continuidad de negocio y gestión de crisis subrayan siempre la misma idea: cuando ocurre un incidente grave que afecta a las infraestructuras técnicas, lo primero es mantener la calma y seguir el plan si existe. El peor enemigo en una crisis informática es el pánico.
Cuando una empresa no dispone de un plan de continuidad o de contingencia bien definido, se ve obligada a ir improvisando decisiones estratégicas en caliente. Sin profesionales preparados y sin procedimientos claros, las probabilidades de agravar el problema se disparan.
Errores críticos tras una brecha o caída informática
Las compañías que han pasado por una crisis tecnológica suelen coincidir: los mayores desastres no vienen solo del ataque o del fallo inicial, sino de cómo se responde después. Hay una lista de errores recurrentes que conviene tener muy presentes.
El primero es borrar evidencias sin querer. Restaurar una copia de seguridad o formatear equipos en los primeros minutos, sin guardar antes toda la información forense posible, es un suicidio a nivel de investigación. Es clave preservar logs, imágenes de discos y cualquier rastro que ayude a entender qué ha pasado, cómo ha entrado el atacante o qué componente ha fallado.
Muy relacionado con esto está el error de no mantener la cadena de custodia. Para que las autoridades puedan perseguir a los autores de un ciberataque, las pruebas deben extraerse y conservarse siguiendo un procedimiento forense. Si alguien manipula un sistema sin control, o se pierden metadatos, esas evidencias pueden dejar de tener validez legal.
Otro fallo enorme es no enterarse de que se ha sufrido un ataque. Hay empresas con tal descontrol sobre su infraestructura que pasan meses antes de detectar que les han comprometido sistemas, robado datos o desplegado malware latente, incluso por métodos de espionaje mic-e-mouse. Cuanto más tarde se descubre, más difícil es contener el incidente y recuperar activos.
También es un clásico pensar que “ya no volverá a suceder”. Estudios de compañías como CrowdStrike muestran que siete de cada diez organizaciones que sufren una intrusión vuelven a ser atacadas. Por eso es vital analizar qué vulnerabilidades técnicas o humanas permitieron el incidente, y dejar el sistema en cuarentena tras la restauración para detectar posibles puertas traseras ocultas.
Formatear «a lo loco» para borrar el ataque es otro error muy frecuente. Puede parecer la solución rápida, pero se pierden datos críticos y se destruyen pruebas. Sin esa información, no se puede mejorar la protección, ni aprender de lo ocurrido, ni reclamar a terceros, y se corre el riesgo de que las aseguradoras rechacen el siniestro por negligencia.
A esto se suma el problema de ignorar los protocolos internos. Muchas empresas tienen planes de contingencia bien redactados, pero nadie los conoce o no se han ensayado nunca. En plena crisis, se toman atajos, se saltan pasos clave y se provocan impactos fatales para la continuidad del negocio. Certificaciones como ISO 22301 pueden ayudar a estandarizar estos procesos y reducir la improvisación.
Por último, es muy grave no informar a los usuarios afectados cuando hay una fuga de datos. El responsable del tratamiento tiene la obligación legal de avisar con rapidez a los clientes o ciudadanos cuyos datos personales se han visto expuestos, para que puedan cambiar contraseñas, vigilar movimientos bancarios o tomar otras medidas. Ocultar el incidente solo multiplica el daño y las posibles sanciones.
Y quizá el error más peligroso es creer que se puede resolver todo sin ayuda profesional. Mientras que las grandes corporaciones cuentan con equipos dedicados de seguridad y continuidad, la mayoría de pymes no pueden permitírselo. En estos casos, apoyarse en socios de confianza es clave para minimizar el tiempo de parada y el impacto económico.
Cómo prepararse para una crisis informática en la empresa
La mejor forma de sobrevivir a una crisis informática es trabajarla antes de que suceda. Eso empieza por algo tan básico como llevar un buen mantenimiento de los equipos, sistemas y redes, y por formar a los empleados en buenas prácticas de uso (no abrir adjuntos sospechosos, no instalar software pirata, cuidar las contraseñas, etc.).
Cada organización debería contar con un protocolo de actuación claro ante incidentes. Este documento marca qué hacer si cae el ERP, si se detecta ransomware, si se produce una filtración de datos o si falla un proveedor crítico en la nube. Cuando ya has pensado esos escenarios de antemano, puedes reaccionar en minutos en lugar de improvisar durante horas.
Hay algunas reglas sencillas que ayudan mucho. La primera, identificar rápidamente el origen del problema: no es lo mismo un fallo físico de hardware que un problema de privacidad o una intrusión. En algunos casos, un técnico puede resolverlo en minutos; en otros, necesitas activar todo el plan de crisis.
Es indispensable tener alternativas preparadas: equipos de sustitución, canales manuales de operación, copias de seguridad probadas (no solo realizadas), acceso remoto alternativo, etc. Si un ordenador crítico falla, poder seguir trabajando con otro es la diferencia entre parar el negocio o mantenerlo a medio gas.
En incidentes graves de seguridad, a veces hay que tomar medidas drásticas. Por ejemplo, si sospechas que alguien está espiando un equipo desde fuera, la respuesta sensata es apagarlo, aislarlo de la red y ponerlo en cuarentena antes de empezar a analizarlo con herramientas antimalware y forenses.
Lo que no suele funcionar es intentar arreglarlo a base de tutoriales aleatorios de Internet. Buscando soluciones a ciegas puedes perder horas, empeorar la situación y borrar sin querer pruebas valiosas. En crisis serias, lo razonable es llamar a especialistas que sepan exactamente qué hacer.
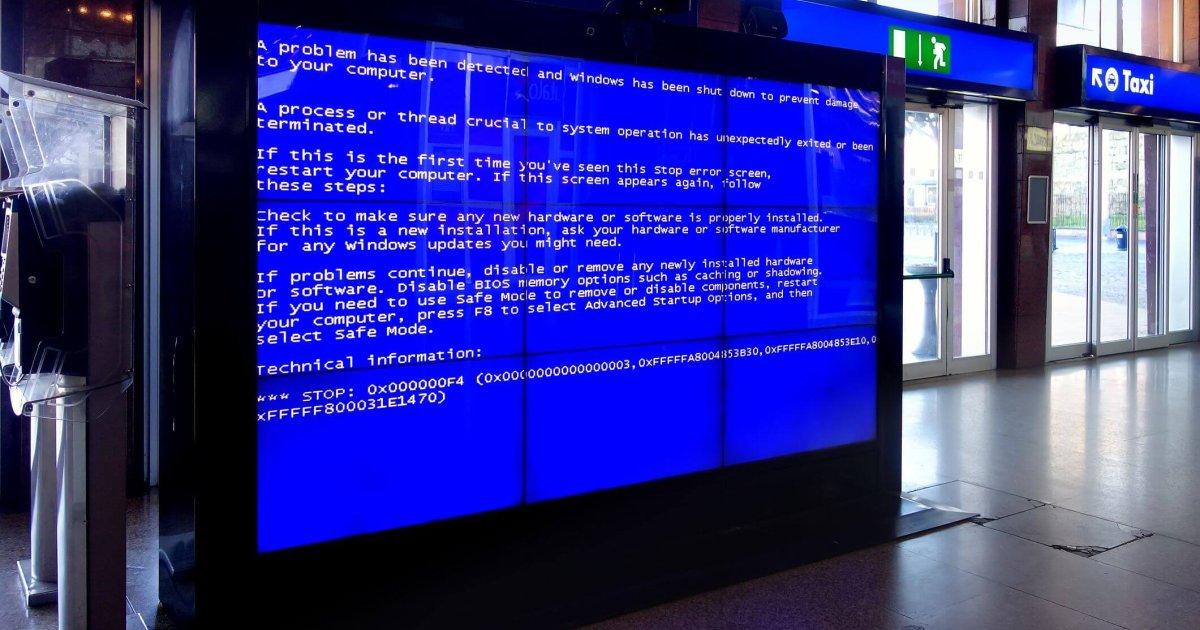
El caso CrowdStrike: cuando un fallo de seguridad tumba medio planeta
Un ejemplo extremo de cómo una crisis informática puede trascender cualquier frontera es el fallo global asociado a una actualización defectuosa de la plataforma de ciberseguridad CrowdStrike Falcon. Un único cambio en un componente de seguridad generó un error crítico en equipos con Windows y servicios en Azure, afectando a miles de organizaciones en todo el mundo.
CrowdStrike, fundada en 2011, se había consolidado como referente en ciberseguridad moderna, utilizando inteligencia artificial y aprendizaje automático para detectar y bloquear ataques en tiempo real. Su tecnología Falcon, basada en la nube, protege endpoints frente a malware, ransomware y amenazas de día cero, y está integrada de forma profunda con Microsoft Azure.
La actualización problemática generó pantallazos azules de “error fatal” en innumerables sistemas Windows. Aerolíneas, bancos, medios de comunicación, servicios de salud e incluso administraciones públicas se vieron afectados. En algunos lugares, los sistemas del servicio de emergencias 911 en Estados Unidos sufrieron interrupciones, y en Europa múltiples aeropuertos tuvieron que recurrir a procesos manuales para facturación y embarque.
El incidente sacó a la luz la enorme dependencia tecnológica y la vulnerabilidad sistémica que existe cuando una sola pieza de software de seguridad tiene acceso prioritario y simultáneo a cientos de miles de máquinas. La escala de la interrupción fue calificada por expertos como “sin precedentes en la historia reciente”, comparable solo a episodios como el ataque WannaCry de 2017.
CrowdStrike identificó el fallo como un defecto en una actualización de contenidos, sin relación con un ciberataque externo. Aseguró que el problema estaba localizado en equipos Windows (los hosts Mac y Linux no se vieron afectados) y que se había desarrollado una solución. Sin embargo, la aplicación de la corrección en miles de redes fue lenta y laboriosa, obligando a reiniciar equipos en modo seguro, eliminar el archivo erróneo y volver a iniciar uno por uno.
Servicios críticos afectados y efecto dominó global
El apagón informático derivado del fallo de CrowdStrike mostró con crudeza cómo un incidente en un proveedor puede paralizar sectores enteros. Las aerolíneas fueron de las más perjudicadas: sistemas de registro de pasajeros, documentación de equipaje y planificación de vuelos quedaron inoperativos en muchos aeropuertos.
En lugares como Sídney, Londres o Nueva Delhi se vivieron escenas de caos y confusión, con vuelos en tierra y colas interminables. Las compañías recurrieron a tarjetas de embarque escritas a mano y procesos manuales para intentar mantener algo de operativa. En Estados Unidos, aerolíneas como Delta, American o United llegaron a declarar un “alto en tierra global” durante horas.
El impacto se extendió también a bancos y redes de pago como Bizum, que experimentaron dificultades para procesar transacciones. Algunas entidades retrasaron la apertura de oficinas y limitaron operaciones mientras recuperaban sus sistemas. En bolsas de valores como la de Londres se registraron interrupciones, y servicios mediáticos y de televisión se quedaron fuera de emisión en varios países.
El sector sanitario no salió indemne: en distintos lugares se reportaron problemas con sistemas de citas, historiales médicos y emisión de recetas. Algunos hospitales se vieron obligados a cancelar operaciones no urgentes y priorizar solo casos graves. Incluso el comité organizador de los Juegos Olímpicos de París reconoció incidencias en sus sistemas TI, si bien activó sus planes de contingencia.
Aunque la conectividad general de Internet no colapsó, el caso demostró cómo una falla en una sola pieza de la cadena de ciberseguridad puede provocar un efecto dominó que afecta a la aviación, las finanzas, los medios, la salud y los servicios públicos de medio mundo.
Lecciones en ciberseguridad y gestión de crisis
Del incidente de CrowdStrike y de otros apagones similares se pueden extraer varias lecciones. En primer lugar, la necesidad de planes sólidos de gestión de crisis y comunicación. Cuando una organización depende de servicios en la nube o de proveedores de seguridad externos, debe tener procedimientos claros para actuar y comunicar ante caídas masivas.
También se ha puesto de relieve la importancia de un buen gobierno de actualizaciones. Aunque mantener sistemas al día es esencial para la seguridad, es clave contar con fases de pruebas, despliegues controlados y mecanismos de rollback rápidos si una actualización sale mal. En entornos críticos, no se puede depender de cambios simultáneos sin margen de maniobra.
Las organizaciones deben reforzar sus políticas de ciberseguridad y continuidad con planes específicos para fallos de proveedores, caída de la nube o indisponibilidad prolongada de servicios externos. Eso incluye escenarios de operación degradada: qué se puede hacer manualmente, qué procesos se priorizan, qué sistemas deben tener alternativas locales, etc.
Por último, estos episodios recalcan la necesidad de contar con equipos especializados y aliados de confianza para gestionar crisis complejas. Desde el análisis forense y la respuesta a incidentes hasta la comunicación externa y la coordinación con reguladores, una crisis informática mal gestionada puede tener consecuencias económicas, legales y reputacionales devastadoras.
Todas estas crisis, desde la escasez de hardware por la IA hasta caídas globales como la de CrowdStrike, dejan claro que vivimos en un ecosistema digital extremadamente interdependiente, donde un fallo técnico, una decisión de producción de chips o una simple actualización errónea pueden repercutir en la vida diaria de millones de personas y en la salud económica de sectores enteros.
Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.