- Los microservicios permiten desarrollar aplicaciones modulares y escalables, donde cada servicio es autónomo y desplegable de forma independiente.
- Docker facilita la creación de contenedores ligeros y portables que empaquetan cada microservicio con todas sus dependencias.
- Kubernetes orquesta los contenedores, gestionando el despliegue, escalado, red y recuperación automática de los microservicios en el clúster.
- Aplicar buenas prácticas de seguridad, monitorización y automatización es clave para operar con éxito microservicios en producción.
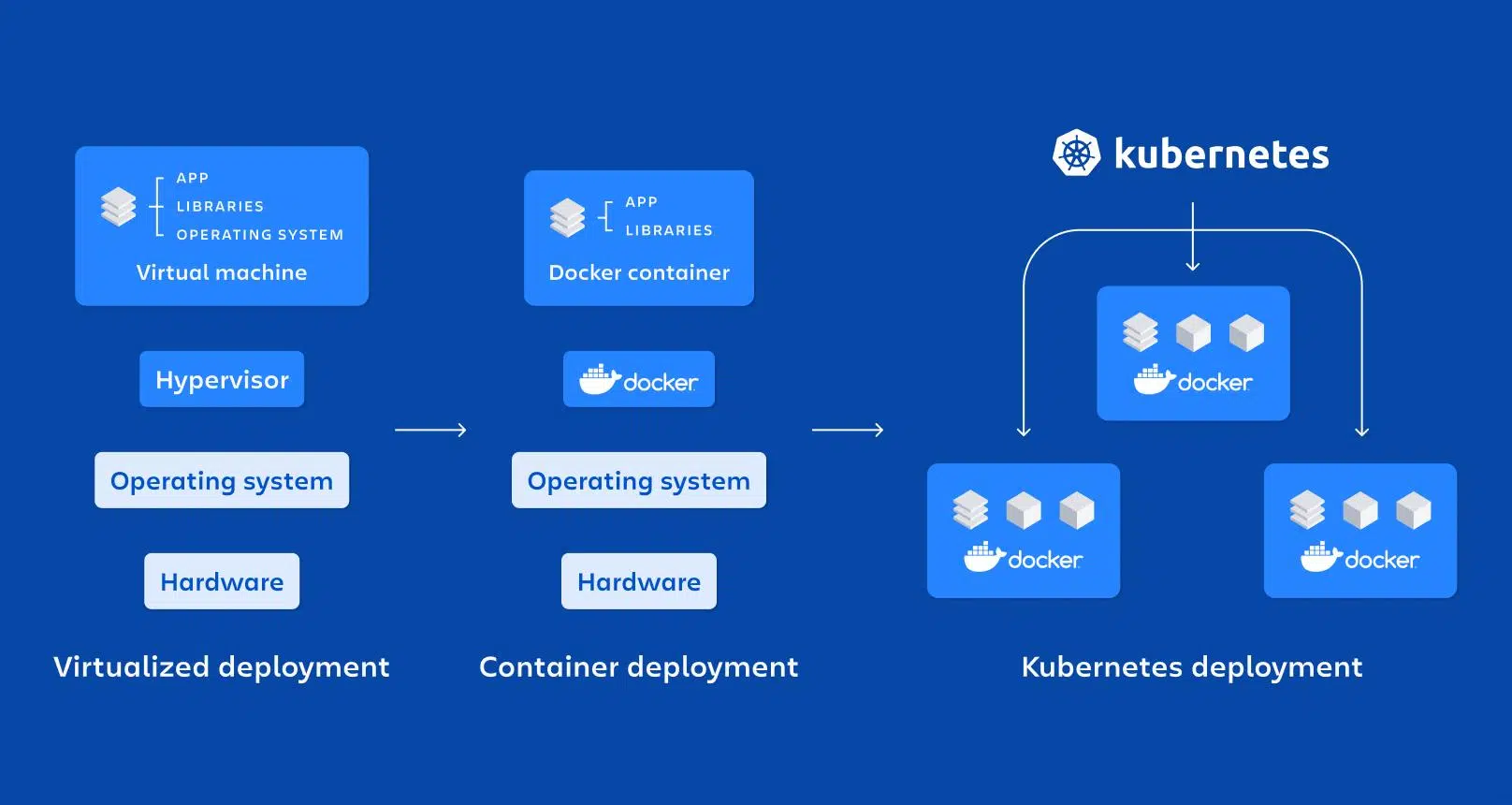
En los últimos años, la combinación de microservicios, Docker y Kubernetes se ha convertido en el estándar de facto para desplegar aplicaciones modernas, escalables y fáciles de mantener. Cada vez más empresas están dejando atrás las aplicaciones monolíticas para apostar por arquitecturas distribuidas que se adaptan mejor a entornos cambiantes y a estrategias DevOps.
Si te preguntas cómo implementar microservicios con Docker y Kubernetes en la práctica, este contenido te va a venir como anillo al dedo: repasaremos los conceptos clave, las ventajas y desafíos, cómo crear contenedores, cómo orquestarlos en un clúster y qué pasos seguir para instalarlos en Windows y Linux, además de una serie de consejos para usarlos con cabeza en entornos reales.
Qué es una arquitectura de microservicios y en qué se diferencia de un monolito
Una arquitectura de microservicios se basa en dividir una aplicación en múltiples servicios pequeños, autónomos y desplegables de forma independiente, cada uno centrado en una funcionalidad concreta (usuarios, pagos, catálogo, pedidos, etc.), que se comunican principalmente mediante APIs ligeras (HTTP/REST, gRPC, mensajería, etc.).
En una aplicación monolítica, en cambio, toda la lógica de negocio, la capa de presentación y el acceso a datos están empaquetados en un único bloque de despliegue; cualquier cambio requiere recompilar, testear y desplegar todo el sistema, lo que complica la evolución y eleva el riesgo de introducir errores en producción.
Con microservicios, cada servicio dispone de su propio ciclo de vida: puede desarrollarse, probarse, desplegarse, escalarse y versionarse de manera independiente. Esto permite que múltiples equipos trabajen en paralelo, simplifica la adopción de nuevas tecnologías y facilita la integración con prácticas de CI/CD.
Además, esta arquitectura introduce el concepto de escalabilidad independiente por componente: en lugar de escalar toda una aplicación monolítica para soportar más carga en un módulo concreto, solo se escalan los microservicios que realmente lo necesitan, optimizando mejor los recursos de infraestructura.
Ventajas y desafíos reales de los microservicios
Pasar a microservicios no es solo una moda: aporta beneficios tangibles en escalabilidad, resiliencia y velocidad de despliegue, pero también introduce una complejidad operativa que hay que saber gestionar.
Entre las ventajas más destacadas está la escalabilidad independiente de cada servicio: si, por ejemplo, el módulo de pagos recibe más tráfico que el de administración, puedes incrementar únicamente las réplicas del microservicio de pagos, sin tocar el resto de la aplicación ni desperdiciar recursos.
También se gana mucho en despliegue continuo y entregas frecuentes. Al aislar cada servicio, es posible liberar nuevas versiones de forma incremental, sin tener que parar ni volver a desplegar toda la aplicación, reduciendo ventanas de mantenimiento y mejorando el time-to-market.
Otro punto clave es la resiliencia y tolerancia a fallos: cuando se diseña correctamente, la caída de un microservicio no debería tumbar por completo el sistema. Con patrones como timeouts, reintentos y circuit breakers, el resto de servicios puede seguir respondiendo, limitando el impacto de los errores.
Además, los microservicios permiten flexibilidad tecnológica: cada equipo puede elegir el lenguaje, framework o base de datos más apropiado para su servicio, siempre que respete los contratos de comunicación y las políticas globales de la plataforma.
En la cara B de la moneda encontramos la complejidad operativa y de observabilidad. Gestionar docenas o cientos de servicios implica lidiar con redes distribuidas, trazas entre servicios, logging centralizado, seguridad, versionado de APIs y consistencia de datos, lo que exige herramientas avanzadas y procesos maduros.
También se complica la gestión de la comunicación entre servicios: hay que diseñar bien cómo se intercambian datos, cómo se gestionan los fallos, cómo se manejan latencias y cómo se evita que una dependencia lenta arrastre al resto del sistema. Las pruebas y la depuración dejan de ser triviales, porque no se testea un único bloque, sino un conjunto de servicios interconectados.
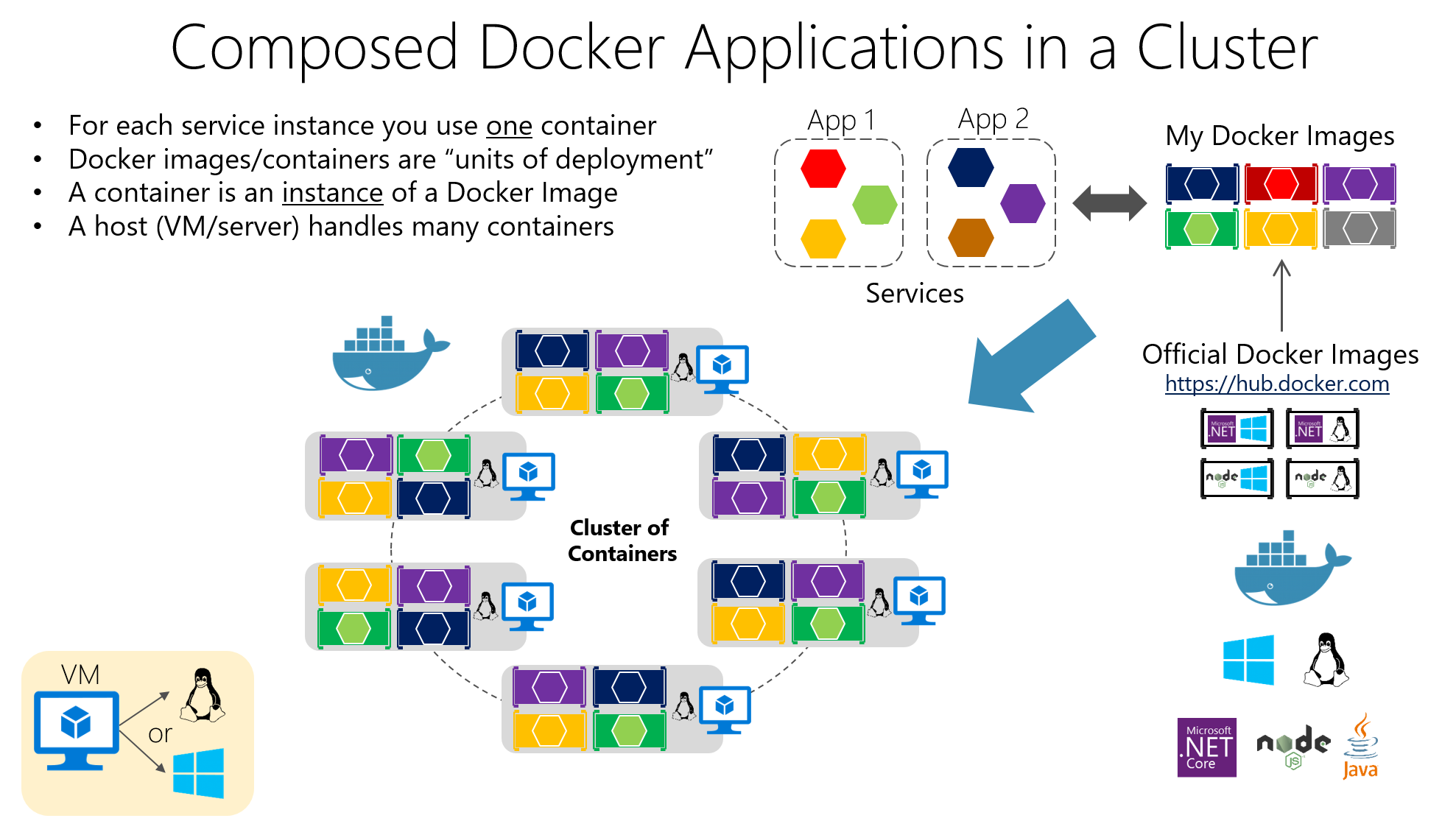
Contenedores: la base para ejecutar microservicios de forma aislada
La tecnología de contenedores se ha convertido en el soporte ideal para microservicios porque permite empaquetar una aplicación y todas sus dependencias en una unidad estandarizada y portable. En lugar de instalar librerías, runtimes y herramientas en cada servidor, todo viaja dentro del contenedor.
Un contenedor es, en esencia, una forma ligera de virtualización a nivel de sistema operativo: comparte el kernel del host pero ejecuta procesos en espacios de nombres aislados (namespaces) y con recursos limitados por cgroups, lo que hace que arranquen rápido y consuman menos que una máquina virtual.
Entre sus propiedades clave destacan el aislamiento, la portabilidad, la ligereza y la modularidad; cada microservicio ejecutándose en su propio contenedor se vuelve más fácil de desplegar, parar, actualizar o replicar, encajando de maravilla con los principios de las arquitecturas distribuidas.
Comparados con las máquinas virtuales para producción, los contenedores no necesitan un sistema operativo completo por instancia, sino que comparten el del host. Eso reduce drásticamente el tamaño de las imágenes y el tiempo de arranque, permitiendo levantar o destruir contenedores en segundos.
Docker: la plataforma de referencia para contenerizar microservicios
Docker es la herramienta más popular para trabajar con contenedores, porque facilita la creación, empaquetado, distribución y ejecución de aplicaciones contenerizadas tanto en entornos de desarrollo como en pruebas y producción.
Su idea central es empaquetar el software en imágenes Docker, que son artefactos inmutables que incluyen el código de la aplicación, las librerías que necesita, herramientas del sistema y configuraciones básicas. A partir de estas imágenes se crean contenedores en ejecución, que son instancias aisladas basadas en esa imagen.
La construcción de imágenes se define en un Dockerfile, un archivo de texto donde se indican instrucciones como la imagen base, el directorio de trabajo, qué archivos copiar, qué dependencias instalar, qué puertos exponer y qué comando lanzar al iniciar el contenedor.
Imagina que tienes una API escrita en Node.js. Podrías crear un Dockerfile similar al siguiente, donde se parte de una imagen oficial de Node, se copian los archivos, se instalan las dependencias y se define el comando de arranque:
FROM node:14
WORKDIR /app
COPY . .
RUN npm install
EXPOSE 3000
CMD
Este archivo indica que la aplicación se ejecutará en el directorio /app dentro del contenedor, que se instalarán las dependencias con npm, que se expondrá el puerto 3000 y que, al arrancar el contenedor, se ejecutará npm start.
Para construir y lanzar ese contenedor, bastaría con ejecutar desde la carpeta del proyecto docker build y después docker run, mapeando los puertos para poder acceder desde el host, o para aplicaciones multicontenedor usa docker-compose:
docker build -t mi-app .
docker run -p 3000:3000 mi-app
Gracias a este modelo, el clásico problema de “en mi máquina funciona” se reduce al mínimo, porque el entorno de ejecución viaja con la aplicación. Además, Docker se integra muy bien con sistemas de CI/CD, registries privados y herramientas de orquestación como Kubernetes.
Componentes clave en Docker y su papel en microservicios
En un despliegue típico, hablamos de un Docker Host, que es el sistema (físico o virtual) donde se instala Docker; sobre él corre el Docker Engine, el demonio que gestiona imágenes, redes, volúmenes y el ciclo de vida de los contenedores.
Los contenedores contienen la aplicación y sus dependencias empaquetadas en una imagen, de modo que cualquier servidor con Docker puede ejecutar esa imagen de forma consistente. Esta consistencia es crucial cuando se tienen muchos microservicios desplegados en varios entornos (desarrollo, QA, producción, etc.).
Entre las ventajas más interesantes de Docker están la portabilidad entre entornos, la automatización de despliegues, la modularidad de procesos y el soporte para capas y control de versiones en las imágenes, lo que facilita revertir cambios y optimizar el almacenamiento.
Kubernetes: el orquestador para gobernar cientos de contenedores
Cuando pasas de unos pocos contenedores a docenas o cientos de ellos, administrarlos a mano se convierte en una locura. Ahí entra en juego Kubernetes, una plataforma open source diseñada para orquestar contenedores a gran escala.
Kubernetes automatiza tareas críticas como el despliegue, el escalado, la recuperación ante fallos, la configuración de red y el almacenamiento de las aplicaciones contenerizadas. Está pensado para funcionar en nubes públicas, privadas, entornos híbridos e incluso on-premises.
Su foco es gestionar clústeres compuestos por varios nodos (máquinas) donde se ejecutan los contenedores. El objetivo es garantizar que las aplicaciones estén siempre en el estado deseado: número de réplicas, versiones desplegadas, recursos asignados y conectividad entre servicios.
Elementos fundamentales de Kubernetes
La unidad más pequeña en Kubernetes es el Pod, que representa una o más instancias de contenedores que deben ejecutarse juntas (por ejemplo, un contenedor de aplicación y uno de sidecar para logging). Los Pods son efímeros: se crean, destruyen y reemplazan según las necesidades del clúster.
Para exponer tus Pods, Kubernetes ofrece el recurso Service, que actúa como capa de abstracción de red. Un Service agrupa un conjunto de Pods y proporciona una IP estable, un nombre DNS y balanceo de carga interno, de forma que los clientes no necesitan conocer los detalles de cada Pod.
El recurso Deployment se utiliza para definir cómo deben desplegarse y actualizarse los Pods: cuántas réplicas, qué imagen usar, qué etiquetas aplicar y qué estrategia de actualización seguir. Kubernetes se encarga de mantener siempre el número deseado de Pods en ejecución y de realizar rolling updates o rollbacks cuando cambias la configuración.
También existen recursos como ConfigMap y Secret, que permiten externalizar la configuración y almacenar datos sensibles (contraseñas, tokens, claves API) sin tener que empaquetarlos dentro de las imágenes. Esto facilita mucho la gestión segura de la configuración en diferentes entornos.
Cómo se organiza un clúster de Kubernetes
La “cabeza” del clúster es el Control Plane de Kubernetes, que agrupa varios componentes responsables de orquestar todo el sistema. Entre ellos está el API Server, que es la puerta de entrada para administrar el clúster; cualquier acción (crear un Deployment, listar Pods, modificar un Service) pasa por esta API.
El Scheduler se encarga de decidir en qué nodo se ejecuta cada Pod, teniendo en cuenta recursos disponibles, afinidades y restricciones; mientras que el Controller Manager vigila el estado del clúster y lanza acciones para que la realidad coincida con lo que has declarado en los manifiestos (por ejemplo, crear nuevos Pods si hay menos de los que has pedido).
El almacenamiento del estado se delega en etcd, una base de datos distribuida que guarda la configuración y la información de todos los recursos del clúster. Por otro lado, en cada nodo trabajador se ejecutan procesos como el kubelet (agente que comunica el nodo con el API Server), el kube-proxy (que gestiona el tráfico de red y el balanceo) y el runtime de contenedores (Docker, containerd, CRI-O, etc.).
Despliegue de microservicios en Kubernetes con archivos YAML
Para desplegar un microservicio en Kubernetes, lo habitual es describirlo con un manifiesto YAML, donde defines el Deployment (plantilla de Pods, imagen, puertos, número de réplicas, etiquetas) y el Service correspondiente para exponerlo dentro o fuera del clúster.
Un ejemplo básico de Deployment para una aplicación llamada “mi-app” podría ser algo así, donde se definen tres réplicas y el puerto 3000 como puerto del contenedor:
apiVersion: apps/v1
kind: Deployment
metadata:
name: mi-app
spec:
replicas: 3
selector:
matchLabels:
app: mi-app
template:
metadata:
labels:
app: mi-app
spec:
containers:
- name: mi-app
image: mi-app:latest
ports:
- containerPort: 3000
Este manifiesto indica que el clúster debe mantener tres Pods en ejecución con la imagen “mi-app:latest”, todos etiquetados con app=mi-app, de forma que un Service pueda localizarlos y distribuir tráfico entre ellos. La lógica de escalado, actualizaciones y sustitución de Pods en caso de fallo la gestiona Kubernetes automáticamente.
Junto a los Deployments es habitual definir Servicios de tipo ClusterIP, NodePort o LoadBalancer, según si el microservicio debe ser accesible solo dentro del clúster, desde los nodos o desde Internet. Toda esta configuración se versiona en repositorios, integrándose naturalmente con pipelines de CI/CD.
Escalado, actualizaciones y autoreparación en Kubernetes
Uno de los grandes motivos para usar Kubernetes es su capacidad para escalar y actualizar microservicios sin parar la aplicación. Puedes cambiar el número de réplicas en el manifiesto (o con un comando de kubectl) y el clúster se encargará de crear o eliminar Pods hasta alcanzar el valor deseado.
Este escalado puede ser manual o automático, usando recursos como el Horizontal Pod Autoscaler (HPA), que ajusta dinámicamente las réplicas en función de métricas como CPU o memoria. Así, en momentos de alta demanda, se incrementa la capacidad, y cuando baja la carga, se liberan recursos.
En cuanto a las actualizaciones, Kubernetes implementa rolling updates por defecto: va creando Pods con la nueva versión y eliminando los de la anterior de forma progresiva, sin hacer un corte brusco. Si algo sale mal, un rollback te permite recuperar rápidamente la versión previa.
Otra funcionalidad crítica es la autorreparación: si un contenedor o un Pod muere, Kubernetes lo recrea automáticamente; si un nodo deja de responder, los Pods afectos se reprograman en otros nodos disponibles, manteniendo la aplicación operativa.
Monitorización y observabilidad de microservicios en Kubernetes
Para operar correctamente un entorno de microservicios, no basta con desplegar y escalar: necesitas visibilidad en tiempo real del rendimiento y del estado de los servicios. En Kubernetes es muy habitual integrar herramientas como Prometheus para recopilar métricas y Grafana para visualizarlas.
Prometheus se encarga de “raspar” métricas de los Pods, nodos y componentes del clúster, almacenarlas y permitir definir alertas sobre ellas; combinado con Grafana, puedes crear paneles donde vigilar consumo de CPU, memoria, errores HTTP, latencias, número de réplicas o estado de los nodos de forma muy clara.
Además, kubectl ofrece comandos para inspeccionar el estado de Deployments, Services, Pods y otros recursos, ver logs, describir eventos o acceder a contenedores para depurar. Todo esto forma parte de una estrategia de observabilidad que, en microservicios, no es opcional si quieres dormir tranquilo.
Relación entre microservicios, Docker y Kubernetes
Microservicios, Docker y Kubernetes encajan como piezas de un mismo puzle: la arquitectura de microservicios define cómo diseñas la aplicación, Docker se encarga de empaquetar y ejecutar cada servicio y Kubernetes orquesta todos esos contenedores en un clúster.
Cada microservicio se encapsula en una imagen de Docker que incluye su código y dependencias, lo que garantiza que se comporte igual en el portátil del desarrollador, en un entorno de pruebas o en producción en la nube. Este empaquetado uniforme es vital para la filosofía DevOps.
Por su parte, Kubernetes actúa como orquestador de contenedores: decide cuántas instancias de cada microservicio deben estar corriendo, dónde se ubican, cómo se balancea el tráfico hacia ellas, cómo se recuperan ante fallos y cómo escalan cuando aumenta o disminuye la demanda.
En una aplicación de e-commerce, por ejemplo, podrías tener microservicios de autenticación, catálogo, carrito y pagos, cada uno con su imagen Docker y su Deployment en Kubernetes. De este modo, puedes escalar el catálogo en campañas masivas o los pagos en momentos críticos sin tocar el resto, y orquestar su ciclo de vida completo desde pipelines de CI/CD hasta el monitoreo post-producción.
Instalación de Docker y Kubernetes en Windows
Si trabajas con Windows, la forma más cómoda de empezar es instalar Docker Desktop, que incluye el motor de Docker y herramientas adicionales, e incluso opciones para habilitar Kubernetes integrado en tu máquina.
El proceso típico pasa por descargar Docker Desktop desde la web oficial, ejecutar el instalador (Docker Desktop Installer.exe) y seguir el asistente. Durante la instalación, se puede elegir entre usar Hyper-V o WSL 2 como tecnología de virtualización; si solo hay una disponible, es la que se usará.
Tras el reinicio del sistema, al abrir Docker Desktop se inicializa el entorno de contenedores; si la virtualización no estaba activada, el propio instalador suele ofrecer habilitarla automáticamente. A partir de ahí puedes lanzar contenedores, por ejemplo, de Nginx o de tus propias aplicaciones.
Para usar Kubernetes en Windows, es importante contar primero con Docker y con las capacidades de virtualización activadas. Después, se puede habilitar Kubernetes desde Docker Desktop o bien instalar y configurar kubectl para gestionar clústeres externos y, si procede, desplegar el dashboard de Kubernetes mediante un manifiesto remoto.
Una vez configurado, podrás acceder al dashboard a través de un proxy local, utilizando un token de autenticación generado con kubectl y apuntando, por ejemplo, al fichero de configuración .kube/config para gestionar el acceso al clúster desde el navegador.
Instalación de Docker y Kubernetes en Linux
En sistemas Linux, como Ubuntu, la instalación de Docker suele ser bastante directa: se actualizan los paquetes, se instala el motor Docker y se comprueba que el entorno funciona correctamente ejecutando un contenedor de prueba.
Los pasos típicos incluyen actualizar el sistema con apt-get update y apt-get upgrade, eliminar posibles versiones previas de Docker Desktop si las hubiera y, a continuación, instalar docker-ce, docker-ce-cli, containerd.io y el plugin de docker-compose desde los repositorios oficiales o especificando la versión deseada.
Para verificar que todo está en orden, suele lanzarse un contenedor de “hello-world” que descarga una imagen mínima y la ejecuta. Si el mensaje se muestra correctamente, tienes Docker operativo para empezar a contenerizar tus microservicios.
En cuanto a Kubernetes, en Linux se puede instalar utilizando herramientas como kubeadm. El flujo típico pasa por añadir la clave del repositorio de Kubernetes, configurar el fichero de lista de paquetes, instalar kubeadm y comprobar su versión.
Después se inicializa el clúster en el nodo maestro con kubeadm init (indicando el rango de red para los Pods), se recupera el comando de “join” para que los nodos trabajadores se unan al clúster y se configura el acceso local creando el directorio $HOME/.kube, copiando el admin.conf y ajustando los permisos.
Con esto, tendrás un clúster básico listo para desplegar microservicios contenerizados, instalar una red de Pods (Flannel, Calico, etc.) y comenzar a trabajar con Deployments, Services y el resto de recursos de Kubernetes.
Buenas prácticas y recomendaciones para usar Docker y Kubernetes
Para aprovechar al máximo estos entornos, conviene seguir una serie de buenas prácticas con Docker, empezando por usar imágenes oficiales o de confianza, ya sea desde Docker Hub o desde repositorios privados verificados, para reducir riesgos de seguridad.
Es muy recomendable optimizar el tamaño de las imágenes utilizando imágenes base ligeras, multi-stage builds y eliminando archivos temporales o artefactos innecesarios. Imágenes más pequeñas se descargan más rápido y agilizan los despliegues en Kubernetes.
Otro punto clave es utilizar volúmenes para la persistencia de datos, en lugar de guardar información dentro de los contenedores, de forma que la pérdida o recreación de un contenedor no implique perder datos importantes.
Limitar los recursos asignados a cada contenedor (CPU, memoria, I/O) ayuda a evitar que un único servicio acapare el host y degrade al resto. Además, hay que monitorizar contenedores con herramientas como docker stats o soluciones más avanzadas para mantener el control en producción.
Con Kubernetes, es esencial antes de saltar a producción. Dominar la arquitectura del clúster y sus componentes reduce muchos dolores de cabeza.
También es buena idea automatizar al máximo: utilizar controladores de replicación, autoscalers y Jobs para cargas batch; aprovechar las capacidades de rolling updates y rollbacks; y definir manifiestos declarativos versionados en repositorios Git.
La seguridad debe estar siempre encima de la mesa: restringir accesos al API Server, gestionar credenciales mediante Secrets, cifrar datos en tránsito y en reposo, aplicar parches con regularidad y definir políticas de red que limiten la comunicación entre servicios según el principio de mínimo privilegio.
Por último, es indispensable contar con buenos sistemas de monitorización y logging centralizado, así como con entornos de preproducción donde probar cambios de forma exhaustiva antes de llevarlos al clúster de producción, reduciendo riesgos y sorpresas desagradables.
Todo este ecosistema de microservicios, contenedores Docker y orquestación con Kubernetes te permite construir sistemas mucho más flexibles, escalables y resilientes que los monolitos tradicionales; combinando una arquitectura bien pensada, herramientas adecuadas y buenas prácticas de DevOps, puedes desplegar aplicaciones que se adapten sin problema a los cambios de carga, que se recuperen de fallos con rapidez y que resulten más sencillas de evolucionar a lo largo del tiempo.

Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.