- El error indica que el kernel no puede montar la partición raíz por fallos en initramfs, GRUB o la configuración de discos.
- En Ubuntu suele bastar con arrancar un kernel antiguo, regenerar initramfs para el kernel nuevo y actualizar GRUB.
- En CentOS el modo rescate permite chroot, limpiar la base de datos RPM y reinstalar el paquete del kernel.
- En instalaciones nuevas o VMs es clave revisar particiones EFI, modo UEFI/Legacy y la configuración de discos virtuales.
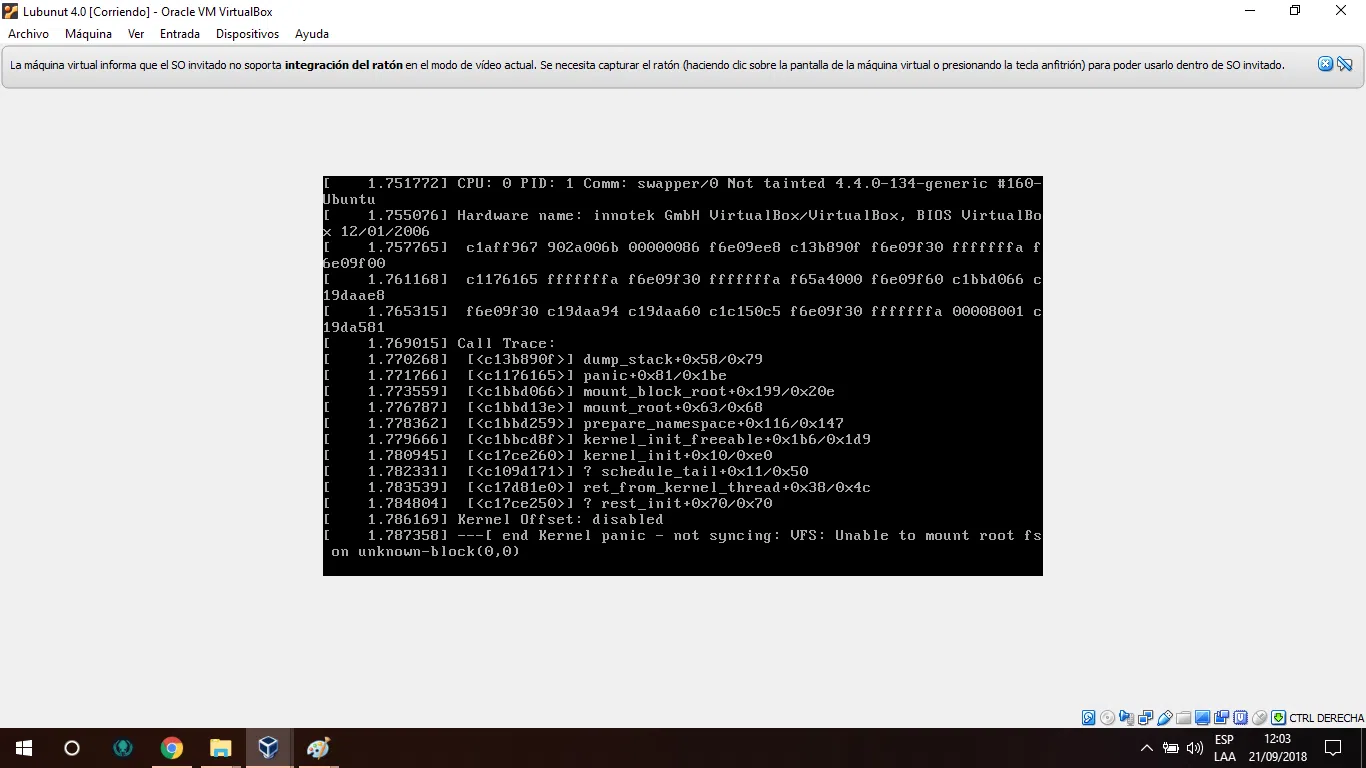
Cuando aparece en la pantalla el temido mensaje “Kernel panic – not syncing: VFS: unable to mount root fs on unknown-block(0,0)” es normal ponerse nervioso. De repente, tu sistema Linux no arranca, la consola se queda congelada con un muro de texto y parece que lo has perdido todo. La buena noticia es que, en la mayoría de los casos, no has perdido datos y la situación tiene arreglo si sigues una serie de pasos con calma.
Este problema puede darse en distintos escenarios: al instalar una distro nueva (como Linux Mint), al actualizar Ubuntu, al arrancar un servidor CentOS o al iniciar una máquina virtual con Ubuntu u otra distribución. Aunque los contextos sean diferentes, el error del kernel es parecido y las causas suelen girar en torno a lo mismo: el kernel no puede montar el sistema de archivos raíz. En este artículo vamos a desgranar, con detalle y en un lenguaje lo más claro posible, qué significa este error y cómo solucionarlo según cada caso real.
Qué significa el error «kernel panic – VFS: unable to mount root fs on unknown-block(0,0)»

Cuando el kernel arranca, uno de sus primeros trabajos es localizar y montar la partición que contendrá el sistema de archivos raíz “/”. Para poder hacerlo, necesita saber en qué dispositivo está (por ejemplo, /dev/sda2), qué tipo de sistema de archivos usa (ext4, xfs, etc.) y disponer de los módulos necesarios para acceder a ese dispositivo (controladores de disco, drivers de controladoras, etc.).
El mensaje “VFS: unable to mount root fs on unknown-block(0,0)” indica que el subsistema de archivos virtual (VFS) del kernel no ha sido capaz de montar esa raíz. El “unknown-block(0,0)” muestra que ni siquiera ha podido identificar correctamente el dispositivo de bloque desde el que debería arrancar. Es decir, para el kernel, el disco donde está tu “/” es prácticamente invisible o inaccesible en ese momento.
Este fallo puede deberse a varias causas: imagen initramfs ausente o corrupta, cambios en el UUID o en el mapeo de discos, drivers que no se cargan, errores en el cargador de arranque (GRUB) o incluso problemas de configuración de particiones y tabla de particiones.
Un punto importante que suele tranquilizar a mucha gente es que el kernel panic no implica de por sí pérdida de datos. Lo que ha fallado es la fase de arranque, pero las particiones, en la inmensa mayoría de los casos, siguen ahí intactas a la espera de que arranquemos un entorno de rescate o un kernel funcional para poder acceder a ellas.
En muchas pantallas de error también aparecen mensajes secundarios como “SGX disabled” o avisos de otros módulos, que pueden despistar. Normalmente, estas líneas no son la causa principal del problema, sino simples mensajes informativos sobre características del procesador o del sistema. La clave está siempre en la frase relacionada con VFS y el montaje de la raíz.
Casos típicos: instalación de Linux Mint, actualización de Ubuntu, CentOS y máquinas virtuales
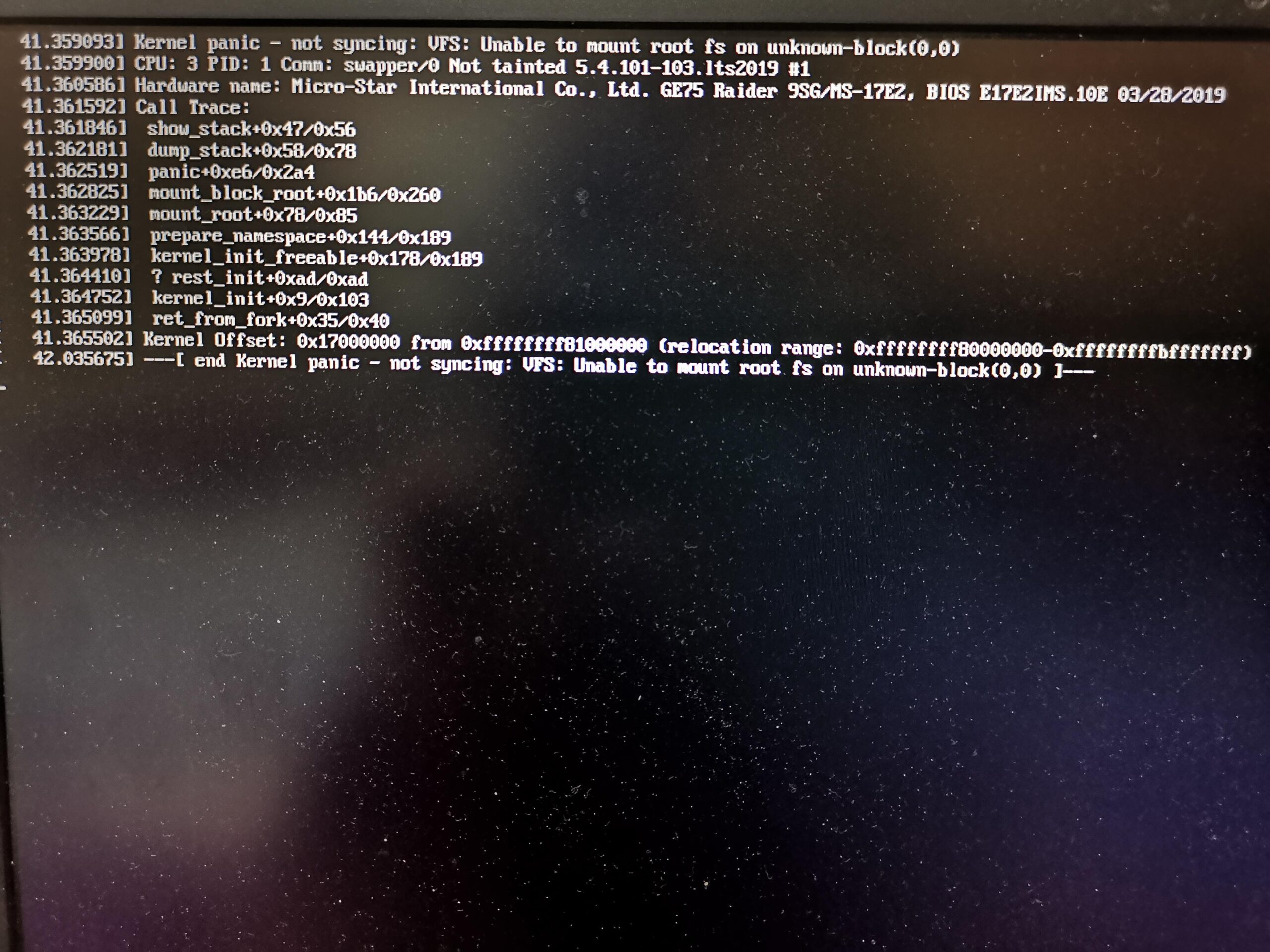
Este error de kernel panic suele aparecer en situaciones muy concretas. Conocer esos escenarios ayuda a entender qué ha podido salir mal y qué pasos seguir. Uno de los casos más frecuentes es intentar arrancar por primera vez un sistema recién instalado, como Linux Mint 21.2 Cinnamon, después de crear manualmente las particiones.
Un ejemplo real: un usuario en un portátil con Windows decide instalar Linux Mint usando BalenaEtcher para grabar la ISO en un pendrive de 16 GB. Comprueba en Windows que el equipo usa firmware UEFI, entra en la BIOS, elige el USB de arranque y entra en la sesión en vivo de Mint. Hasta aquí todo parece normal. El problema llega cuando, durante la instalación, se hace un particionado manual con creación de una nueva tabla de particiones en /dev/sda (1 TB), una partición EFI de 512 MB en /dev/sda1, swap de 2 GB, raíz (/) de unos 10 GB en ext4 y /home con el resto del disco.
En ese escenario concreto, se selecciona además /dev/sda1 (la partición EFI) como dispositivo para la instalación del cargador de arranque. La instalación termina, se marcan opciones como la instalación de códecs y se crea el usuario. Después, en lugar de reiniciar, se decide ejecutar en la sesión en vivo un “apt update” y “apt upgrade” para salir con el sistema ya actualizado. Al reiniciar, en lugar de iniciar correctamente, aparece el famoso kernel panic y el usuario queda atrapado entre la BIOS y las opciones de arranque de Mint.
Otro escenario típico se da tras actualizar Ubuntu a una versión superior. En teoría, debería ser un proceso transparente: se descarga el nuevo kernel, se generan los archivos necesarios y se actualiza GRUB. Sin embargo, a veces el paso de generación del initramfs del kernel recién instalado falla o no se llega a ejecutar correctamente. El sistema parece actualizarse sin problemas, pero al reiniciar aparece el error de “Kernel Panic – not syncing: VFS: Unable to mount root fs on unknown-block(0,0)” y no hay forma de entrar con el kernel nuevo.
También hay casos muy comunes en entornos de servidor, por ejemplo en CentOS 6.x tras aplicar actualizaciones. En algunos servidores, después de un yum update o similares, el nuevo kernel puede quedar dañado o mal instalado. Al intentar arrancar, el sistema lanza un kernel panic y se detiene. En estos entornos, evidentemente, la prioridad es recuperar el servicio lo antes posible, por lo que hay procedimientos específicos con modo rescate e instalación de nuevo del paquete del kernel.
Por último, no hay que olvidar las máquinas virtuales (VM) con Ubuntu u otras distros. A veces, al iniciar la VM, el sistema muestra el mensaje de “end kernel panic: not syncing: VFS: unable to mount root fs on unknown-block(0,0)” y se queda totalmente bloqueado. En estos casos, suele ser posible arrancar únicamente con un kernel anterior entrando en “Advanced options for Ubuntu” desde el GRUB de la propia VM, mientras que el kernel más nuevo siempre falla con el mismo error.
Principales causas técnicas del fallo de montaje del root fs
Debajo de todos estos casos hay una serie de motivos técnicos recurrentes. Una de las causas más habituales, sobre todo tras actualizaciones de Ubuntu o kernels nuevos, es la ausencia o corrupción del initramfs correspondiente a la versión de kernel que se intenta cargar. El initramfs es una imagen que contiene un sistema de archivos mínimo con los módulos y herramientas necesarios para montar la raíz real.
Si el initramfs falta, está corrupto o no contiene los módulos adecuados para acceder al disco donde está la partición raíz, el kernel no llegará nunca a montar “/”. Por eso, en muchos tutoriales sobre este error se insiste tanto en “regenerar el initramfs” y en asegurarse de que GRUB recoge correctamente esa imagen para la entrada de arranque afectada.
Otra causa frecuente tiene que ver con problemas en el cargador de arranque GRUB: rutas mal configuradas, UUIDs cambiados, entradas que apuntan a un disco o partición que ya no corresponde, o instalaciones donde se ha montado mal la partición EFI. En el ejemplo de Linux Mint con particionado manual, un error muy común es instalar GRUB en la partición EFI equivocada, o no respetar la configuración de UEFI/Legacy, lo que provoca que el firmware o GRUB no arrancan el kernel correcto o lo hacen sin los parámetros adecuados.
En servidores CentOS y entornos similares, además del initramfs, también pueden afectar paquetes de kernel dañados o inconsistencias en la base de datos de RPM. Si la base de datos de paquetes está corrupta, el gestor de paquetes puede dejar el kernel a medias o con ficheros esenciales ausentes, lo que desemboca en kernel panic al siguiente reinicio.
En máquinas virtuales, además de los problemas ya mencionados, hay que considerar la configuración de discos virtuales, controladoras (IDE, SATA, SCSI, VirtIO) y cambios de hardware virtual. Si modificamos el tipo de controladora de disco de la VM y el kernel no tiene el módulo adecuado en su initramfs, al arrancar puede ocurrir exactamente lo mismo: no ve el disco y se queda con un unknown-block(0,0).
En todos los casos hay una constante: el kernel no llega a ver un dispositivo de bloque válido con el sistema de archivos raíz utilizable. La clave de la reparación estará en restaurar ese camino entre kernel y raíz: arreglar initramfs, reinstalar kernel, corregir la configuración de GRUB o ajustar las particiones y dispositivos visibles.
Solución en Ubuntu: regenerar initramfs y actualizar GRUB
Cuando el problema aparece tras actualizar Ubuntu a una nueva versión o instalar un kernel más moderno, una de las soluciones más efectivas consiste en regenerar la imagen initramfs del kernel afectado y actualizar el cargador de arranque. El proceso se apoya en el hecho de que normalmente aún queda un kernel anterior que sí funciona y permite entrar en el sistema.
Lo primero que se hace es acceder al menú de GRUB. Para ello, se reinicia el equipo y, justo después del arranque de la BIOS/UEFI, se pulsa la tecla Shift (en muchos equipos BIOS) o Esc (en algunos sistemas UEFI) repetidamente hasta que aparezca la pantalla de GRUB. Allí se verá una entrada principal del tipo “Ubuntu” y otra llamada “Advanced options for Ubuntu”.
Dentro de “Advanced options for Ubuntu” se muestra un listado de todas las versiones de kernel instaladas. La idea es seleccionar una versión anterior que se sepa que funcionaba antes de la actualización. Normalmente, la entrada más nueva es la que da kernel panic, así que conviene escoger la inmediatamente anterior (por ejemplo, si falla 5.15.x, probar con 5.13.x). Se selecciona esa entrada y se pulsa Enter para arrancar con ella.
Una vez que el sistema se inicia correctamente con el kernel antiguo, hay que abrir una terminal. Desde ahí se procede a regenerar el initramfs del kernel que estaba fallando. El comando típico en Ubuntu sería algo como:
sudo update-initramfs -c -k <versión-del-kernel>
Reemplazando <versión-del-kernel> por la cadena exacta de la versión problemática, por ejemplo 4.15.0-36-generic o la que aparezca en el mensaje de error o en la salida de uname -r si se necesita comprobarlo. Con este comando se crea (o recrea) la imagen initramfs para esa versión concreta del kernel, incluyendo los módulos y utilidades necesarios para montar la raíz.
Después de regenerar el initramfs, es fundamental actualizar GRUB para que detecte bien la nueva imagen y ajuste los parámetros de arranque. Para ello, se ejecuta:
sudo update-grub
Este comando escaneará el sistema, encontrará las diferentes versiones de kernel, reconstruirá el menú de GRUB y enlazará correctamente cada kernel con su initramfs correspondiente. Una vez finalizado el proceso, solo queda reiniciar el equipo normalmente, sin tocar nada en GRUB, para comprobar si ahora el sistema arranca con el kernel nuevo sin kernel panic.
Recuperación de servidores CentOS en modo rescate
En el mundo de los servidores, especialmente con CentOS 6.x (y versiones similares de RHEL), el kernel panic tras una actualización puede asustar bastante, pero también tiene una solución bastante clara usando el modo rescate. La idea general es arrancar desde un medio externo, montar el sistema instalado, chrootearse a él y reparar el kernel y la base de datos de paquetes si fuera necesario.
El primer paso consiste en arrancar el servidor desde un disco de rescate, que puede ser un CD/DVD o una ISO montada desde la consola de administración del servidor (iLO, iDRAC, KVM remoto, etc.). Al iniciar desde ese medio, en lugar de elegir una instalación normal, se selecciona la opción “Rescue installed system” o similar. Si dicha opción no aparece directamente, se puede entrar en modo rescate escribiendo en el prompt de arranque:
boot: linux rescue
A partir de ahí, el asistente pedirá elegir idioma y distribución de teclado, y ofrecerá la posibilidad de activar la red, por ejemplo mediante DHCP. Activar la red puede ser útil si se va a necesitar descargar paquetes o acceder a repositorios externos durante el proceso de reparación.
Una vez que el entorno de rescate haya detectado el sistema instalado, montará la partición raíz en /mnt/sysimage. Al arrancar una shell dentro de este entorno, el siguiente paso es entrar en el sistema como si lo hubiésemos arrancado realmente, usando el comando:
chroot /mnt/sysimage
A partir de este momento, todos los comandos que se ejecuten afectarán al sistema real del servidor, no al entorno de rescate. Aquí es donde entra en juego la reparación con yum. Un problema típico es que la base de datos de RPM esté corrupta, lo que impide que se gestionen bien los paquetes del kernel. Para comprobarlo, se puede intentar primero:
yum clean
Si este comando lanza errores relacionados con la apertura de las bases de datos, es necesario eliminarlas manualmente. Para ello, se accede al directorio donde se almacenan:
cd /var/lib/rpm
Y se borran los ficheros temporales de base de datos:
rm -f __db.00*
Tras este borrado, se vuelve a intentar la limpieza de yum, esta vez de forma más completa:
yum clean all
Si ahora funciona, significa que la base de datos de RPM se ha reconstruido correctamente. El siguiente paso clave es reinstalar el paquete del kernel, que suele ser el origen del kernel panic cuando hay ficheros dañados o ausentes. Para ello se ejecuta:
yum reinstall kernel
Este comando forzará la descarga e instalación de todos los archivos del kernel actual, incluyendo el propio binario del kernel, el initramfs y cualquier dependencia relacionada. Una vez finalizada la reinstalación, se sale del chroot, se detiene el entorno de rescate y se reinicia el servidor normalmente. Si todo ha ido bien, el servidor debería arrancar sin kernel panic y sin pérdida de datos.
Problemas de arranque en máquinas virtuales con Ubuntu
En el caso de las máquinas virtuales, el mensaje de “end kernel panic: not sync: VFS: unable to mount root fs on unknown-block(0,0)” suele aparecer al iniciar la VM, quedándose el sistema completamente bloqueado. La situación puede resultar muy frustrante porque la única forma de entrar al sistema es a través de una versión de kernel anterior, seleccionada desde el menú “Advanced options for Ubuntu” en GRUB.
Si la VM permite arrancar con un kernel más antiguo, la estrategia es muy similar a la descrita para Ubuntu en bare metal: entrar con el kernel que funciona, regenerar el initramfs del kernel problemático y actualizar GRUB. Esto suele ser suficiente para que el kernel nuevo recupere su capacidad de montar la raíz y el sistema vuelva a iniciarse con normalidad.
Cuando se trata de una VM, también hay que revisar la configuración del hipervisor (VirtualBox, VMware, KVM, Hyper-V, etc.). Cambios en el tipo de controlador de disco (por ejemplo, pasar de SATA a VirtIO) o en la asignación de discos pueden hacer que el kernel no encuentre el dispositivo correcto si su initramfs no contiene los módulos necesarios para ese driver de disco concreto.
En algunos foros se menciona que el problema se produce “aunque la virtualización ya está activada” en la BIOS del host, y esto puede confundir. Lo cierto es que, salvo contadas excepciones, las opciones de virtualización del procesador (VT-x, AMD-V) no tienen relación directa con el error VFS del kernel. El hecho de que estén habilitadas solo garantiza que la VM pueda ejecutarse con mejor rendimiento, pero el kernel panic suele estar más vinculado a la configuración interna de la VM (discos, controladoras) o al propio kernel/ initramfs dentro de la distro invitada.
Si después de regenerar initramfs y actualizar GRUB el problema persiste, se puede recurrir a iniciar la VM desde una ISO en modo live, montar el disco virtual de la máquina afectada y revisar manualmente los ficheros de configuración de GRUB, el contenido de /boot y la presencia de los archivos initramfs correspondientes a cada versión de kernel instalada.
Errores al instalar Linux Mint con particionado manual y UEFI
Volviendo al caso de la instalación de Linux Mint 21.2 Cinnamon con BIOS en modo UEFI y particionado manual, muchos usuarios caen en pequeños errores de configuración que terminan en un kernel panic a la hora de montar la raíz. El proceso típico incluye crear una tabla de particiones nueva en /dev/sda (borrando todo el contenido anterior), definir una partición EFI, swap, raíz y /home, y luego seleccionar la partición EFI como destino de instalación del cargador de arranque.
Aunque en principio esto suena correcto, hay varios puntos delicados. Por ejemplo, la partición EFI debe ser de tipo “EFI System Partition” (ESP), con formato FAT32 y montada en /boot/efi. Si se crea simplemente como una partición cualquiera en el instalador, sin marcarla correctamente como EFI, GRUB puede no instalarse bien y el firmware UEFI puede no reconocerla como partición de arranque válida.
Otro detalle crítico es asegurarse de que el dispositivo seleccionado para el cargador de arranque es el disco completo (por ejemplo /dev/sda) o la partición EFI correcta, según recomiende la distro y el instalador concreto. En algunos casos, elegir manualmente /dev/sda1 como destino cuando la distribución esperaba instalar GRUB en /dev/sda puede provocar que el sistema no genere la estructura de arranque adecuada y que, al reiniciar, el flujo de arranque quede roto.
El hecho de hacer un “apt update” y “apt upgrade” desde la sesión en vivo antes del primer reinicio tampoco es lo más recomendable, porque estás actualizando el entorno de la live, no necesariamente el sistema ya instalado en el disco. Esto puede generar confusión y, bajo ciertas circunstancias, incluso tocar paquetes que puedan influir en el instalador o en cómo se han dejado los ficheros de arranque.
Cuando, tras la instalación, el equipo queda atrapado en un bucle entre BIOS y opciones de arranque de Mint, y al intentar arrancar siempre se llega al kernel panic, una vía de solución es volver a iniciar una sesión en vivo desde el USB, montar el sistema ya instalado y revisar la partición EFI, el contenido de /boot/efi, la configuración de fstab y las entradas de GRUB. En algunos casos resultará más rápido y limpio repetir la instalación, asegurando que la tabla de particiones GPT y la partición EFI se configuran correctamente desde el principio.
También se puede revisar la BIOS/UEFI en busca de opciones que puedan afectar al arranque, como MOK y Secure Boot, modo UEFI vs Legacy/CSM o el orden de arranque. Aunque el mensaje del kernel hable de “SGX disabled”, esa línea suele ser irrelevante para el problema concreto del VFS; lo importante es que el firmware encuentre y lance el GRUB correcto y que este apunte al kernel e initramfs adecuados.
Cuándo usar un dispositivo externo o un live system para rescatar datos
En todos estos escenarios, una preocupación muy frecuente es si hay que recurrir a un dispositivo externo para acceder al disco y rescatar archivos. La respuesta depende del grado de urgencia y de si el sistema sigue teniendo algún kernel funcional desde el que arrancar, ya sea en “Advanced options” o mediante una entrada antigua de GRUB.
Si el equipo aún puede iniciar con una versión de kernel anterior (como en el caso de la VM con Ubuntu o algunas instalaciones de escritorio), lo más cómodo es aprovechar ese kernel que funciona para hacer copias de seguridad completas antes de tocar nada más serio. Se puede conectar un disco externo USB y copiar /home o cualquier directorio crítico, o incluso usar herramientas de clonación si se quiere guardar una imagen completa del sistema.
Cuando no hay ningún kernel que arranque y el sistema entra en kernel panic siempre, entonces sí conviene arrancar desde un medio externo: pendrive con una distro en vivo, ISO de rescate, CD/DVD, etc.. Desde ese entorno en vivo se puede montar el disco duro interno, acceder a las particiones (normalmente ext4 u otras) y extraer los datos que se deseen, ya sea hacia un disco externo, a través de la red o como se prefiera.
Este mismo medio live también sirve para reparar la instalación in situ, ejecutando comandos como chroot, reinstalando kernel, regenerando initramfs o reparando GRUB. De hecho, muchas guías recomiendan este enfoque, sobre todo cuando el sistema está muy dañado o cuando no se puede acceder de ninguna forma al entorno instalado usando un kernel anterior.
Es importante recalcar que el kernel panic, por sí mismo, no destruye datos ni borra particiones. Es un mecanismo de seguridad del kernel que detiene el sistema cuando se encuentra con errores graves que comprometen la integridad del mismo. La prioridad debe ser no forzar apagados ni manipulaciones extrañas del disco y, si hay información importante, centrarse primero en asegurar copias de seguridad antes de profundizar en la reparación.
Sabido todo esto, este tipo de error deja de ser un “fin del mundo” y pasa a ser un contratiempo técnico que casi siempre se puede resolver: arrancando desde un kernel antiguo o desde un entorno de rescate, regenerando el initramfs, reinstalando el kernel o corrigiendo la configuración de GRUB y las particiones, se consigue que el sistema vuelva a montar su raíz y arranque con normalidad sin perder información.

Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.