- WSL2 permite usar la GPU física de Windows desde un Linux real con soporte CUDA y DirectML.
- Es imprescindible combinar Windows actualizado, drivers correctos y una distro WSL2 bien configurada.
- CUDA Toolkit, cuDNN, Docker y frameworks como PyTorch o TensorFlow se integran sin necesidad de VMs completas.
- La selección adecuada de GPU y la monitorización con nvidia-smi garantizan rendimiento y estabilidad en ML.
Si trabajas con machine learning, deep learning o ciencia de datos en Windows, seguramente te has planteado más de una vez si merece la pena montar un Linux aparte o tirar de la nube. Con el soporte oficial de GPU en WSL2 ya no hace falta complicarse tanto: puedes tener un entorno Linux real acelerado por CUDA directamente en tu PC con Windows.
En esta guía vamos a ver, paso a paso, cómo habilitar la GPU en WSL2 para ML y CUDA, qué necesitas a nivel de sistema, cómo instalar los controladores correctos, cómo preparar Ubuntu (u otra distro), cómo integrar CUDA, cuDNN, Docker, TensorFlow, PyTorch y DirectML, y cómo resolver los problemas más típicos que te vas a encontrar por el camino.
Arquitectura: cómo funciona la GPU dentro de WSL2
WSL2 ejecuta un kernel de Linux real dentro de una máquina virtual ligera que gestiona el propio Windows. No es una emulación cutre: es Linux de verdad, con su kernel y su espacio de usuario, pero extremadamente integrado con el sistema anfitrión.
Para aprovechar la GPU desde ese kernel, NVIDIA (y Microsoft) han desarrollado un stack específico que expone la GPU del host Windows a WSL2. Desde el punto de vista de Linux, lo que aparece es la clásica interfaz de CUDA vía libcuda.so, lo que permite que el software piense que está en un Linux “nativo”.
Gracias a esa capa, dentro de WSL2 puedes usar nvidia-smi, nvcc, el CUDA Toolkit, cuDNN y prácticamente cualquier framework de ML compatible con CUDA (PyTorch, TensorFlow, etc.) sin necesidad de montar una máquina virtual pesada ni depender siempre de la nube.
Además, esta integración se extiende a Docker y NVIDIA Container Toolkit, así que puedes ejecutar contenedores GPU-enabled igual que lo harías en un servidor Linux dedicado: por ejemplo, imágenes oficiales de NVIDIA NGC para TensorFlow, PyTorch u otros frameworks de IA.
En la parte de gráficos, con WSLg, también se puede controlar qué GPU se usa para las aplicaciones con interfaz gráfica de Linux, algo muy útil si tu equipo tiene una iGPU Intel o GPU integrada AMD y una NVIDIA dedicada y quieres que el trabajo pesado vaya a la NVIDIA.
Requisitos de Windows, GPU y versiones necesarias

Para que todo esto funcione, el primer filtro es el sistema operativo: necesitas Windows 11 o Windows 10 a partir de la versión 21H2. Versiones anteriores no tienen soporte maduro (o directamente no lo tienen) para GPU en WSL2.
A nivel de hardware, hace falta una GPU moderna con drivers actualizados. Para CUDA puro necesitarás una GPU NVIDIA compatible (idealmente una serie RTX reciente), pero también puedes apoyarte en DirectML si tu GPU es AMD o Intel, o incluso si prefieres usar frameworks adaptados a DirectML sobre una NVIDIA.
Además, WSL2 debe ejecutar un kernel lo bastante reciente. Para las características de GPU, se requiere una versión de kernel 5.10.43.3 o superior. Puedes comprobarlo desde PowerShell con:
wsl cat /proc/version
Si estás justo montando el entorno desde cero en un Windows actualizado, lo más normal es que ya tengas una versión compatible, pero conviene verificarlo por si tu equipo lleva tiempo sin recibir updates o si has tocado la configuración de WSL a mano.
Instalar y actualizar WSL2 con una distribución Linux adecuada
Antes de entrar en drivers y CUDA, hay que asegurarse de que WSL2 está instalado y configurado correctamente. Lo recomendado para desarrollos de ML es usar una distribución basada en glibc, como Ubuntu o Debian, por su compatibilidad con repositorios y paquetes de NVIDIA.
Desde PowerShell con permisos de administrador, puedes habilitar WSL y el componente necesario para WSL2 con los comandos adecuados de Windows. En versiones modernas de Windows 10/11, el flujo más directo es usar wsl –install y especificar la distribución, por ejemplo:
wsl –install -d Ubuntu-22.04
Una vez que finalice la instalación, verás la nueva app de Ubuntu en el menú Inicio. Al abrirla por primera vez, se iniciará la configuración básica (usuario, contraseña, etc.). El siguiente paso esencial es actualizar la caché de paquetes y el sistema dentro de esa distro:
sudo apt update && sudo apt -y upgrade
Además, conviene asegurarse de que el propio WSL está usando el kernel más reciente disponible en Windows. Desde PowerShell, ejecuta:
wsl –update
Esta combinación de pasos te deja con un Ubuntu actualizado sobre WSL2, perfecto como base para instalaciones de CUDA, frameworks de ML o incluso Docker.
Instalación del driver NVIDIA con soporte CUDA para WSL2
La parte crítica para usar la GPU con CUDA en WSL2 es el driver de NVIDIA instalado en Windows, no dentro de Linux. Aquí mucha gente se lía pensando que debe instalar también el driver dentro de la distro, pero para WSL2 no es necesario.
Debes descargar el controlador habilitado para CUDA y WSL desde la página oficial de NVIDIA dedicada a WSL (o desde el buscador general de drivers, seleccionando tu GPU y sistema). Es importante no quedarse con un driver antiguo: el soporte de WSL2 y GPU ha ido recibiendo mejoras sustanciales.
Una vez instalado el driver en Windows, puedes verificar que el sistema ve correctamente la GPU y el driver desde PowerShell. Ejecuta un comando que muestre la información del adaptador, o simplemente abre el Panel de control de NVIDIA y comprueba la versión. Desde WSL, cuando todo está bien, nvidia-smi devolverá el listado de dispositivos CUDA disponibles.
En escenarios de servidor (por ejemplo, Windows Server con WSL2), el flujo es similar: primero instalas WSL y la distro Linux, y después el driver NVIDIA para Windows Server. A continuación, en la parte Linux instalas únicamente el CUDA Toolkit y las librerías necesarias, sin drivers adicionales de GPU dentro del kernel de WSL.
Instalación de CUDA Toolkit, cuDNN y herramientas base dentro de WSL2
Con WSL y el driver NVIDIA listos, toca configurar el entorno de desarrollo dentro de Linux. El objetivo es tener instalados el CUDA Toolkit, cuDNN y las herramientas básicas de Python para poder compilar, ejecutar ejemplos y trabajar cómodamente con frameworks de ML.
Hay dos enfoques: usar los repositorios oficiales de NVIDIA para WSL/Ubuntu o tirar del paquete nvidia-cuda-toolkit de tu distro. Lo más recomendable para flujos de trabajo modernos es añadir los repos de NVIDIA específicos para tu distribución, ya que suelen estar más actualizados que los paquetes genéricos.
Desde tu terminal de Ubuntu en WSL2 puedes agregar los repos y, a continuación, instalar CUDA. Un enfoque alternativo, más simple en algunos entornos, es:
sudo apt -y install python3-pip nvidia-cuda-toolkit
Si usas este paquete, asegúrate de que la versión de CUDA que instala es compatible con las versiones de PyTorch o TensorFlow que planeas usar. Una vez instalado, conviene incluir la ruta a los binarios de CUDA en tu variable PATH, editando por ejemplo el archivo ~/.bashrc y añadiendo una línea tipo:
export PATH=/home/usuario/.local/bin${PATH:+:${PATH}}
Tras guardar y cerrar, basta con abrir una nueva sesión de terminal o ejecutar source ~/.bashrc para que los cambios tengan efecto. Desde ahí ya podrás usar herramientas como nvcc o ejecutar scripts de ejemplo que usen CUDA.
Uso de Docker y NVIDIA Container Toolkit en WSL2

En muchos flujos de ML, sobre todo en empresas o proyectos grandes, es habitual encapsular todo en contenedores. Para aprovechar la GPU desde Docker dentro de WSL2, necesitas que el motor Docker tenga acceso a la GPU a través de NVIDIA Container Toolkit.
Hay dos opciones principales: instalar Docker Desktop en Windows y usar su integración con WSL2, o bien instalar directamente el motor de Docker en la distro Linux dentro de WSL. En el segundo caso, puedes hacerlo con:
curl https://get.docker.com | sh
sudo service docker start
Una vez instalado Docker, toca configurar el repositorio estable de NVIDIA Container Toolkit. Para Ubuntu dentro de WSL puedes seguir la secuencia típica: definir la variable de distribución a partir de /etc/os-release, añadir la clave GPG y el listado de repositorios de NVIDIA para nvidia-docker.
Después instalas el paquete necesario con:
sudo apt-get update
sudo apt-get install -y nvidia-docker2
Con esto en marcha puedes lanzar contenedores que vean la GPU usando la opción –gpus. Por ejemplo, para un contenedor oficial de TensorFlow en NGC:
docker run –gpus all -it –shm-size=1g –ulimit memlock=-1 –ulimit stack=67108864 nvcr.io/nvidia/tensorflow:20.03-tf2-py3
Dentro de ese contenedor, muchos ejemplos ya vienen preparados. Por ejemplo, puedes ir a los ejemplos CNN de NVIDIA y ejecutar un ResNet entrenado previamente:
cd nvidia-examples/cnn/python
resnet.py –batch_size=64
En entornos de servidor con múltiples GPUs, también puedes probar contenedores de ejemplo como el clásico nbody de CUDA para verificar que todas las tarjetas responden correctamente a través de Docker:
docker run –rm -it –gpus=all nvcr.io/nvidia/k8s/cuda-sample:nbody nbody -gpu -benchmark -numdevices=5
TensorFlow, PyTorch y DirectML en WSL2
WSL2 no se limita a CUDA puro: también permite aprovechar TensorFlow-DirectML y PyTorch-DirectML, algo especialmente interesante si tu GPU es AMD o Intel, o si quieres sacarle partido a DirectML incluso con una NVIDIA.
El punto de partida es el mismo: driver actualizado del proveedor de la GPU instalado en Windows, ya sea AMD, Intel o NVIDIA. A partir de ahí creas un entorno de Python virtual dentro de tu distro Linux. Una opción habitual es usar Miniconda:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
conda create –name directml python=3.7 -y
conda activate directml
Con el entorno activado, instalas el framework que te interese. Para TensorFlow-DirectML:
pip install tensorflow-directml
Y para PyTorch-DirectML, primero cubres algunas dependencias básicas de BLAS y LAPACK, y luego instalas el paquete correspondiente:
sudo apt install libblas3 libomp5 liblapack3
pip install torch-directml
Para comprobar que todo funciona, puedes abrir una sesión de Python e intentar una operación simple (por ejemplo, una suma de tensores) y verificar que no se producen errores y que se detecta la aceleración de DirectML en la salida del framework.
Instalación de PyTorch con soporte CUDA en WSL2
Si tu objetivo es usar PyTorch con CUDA “de toda la vida” sobre una GPU NVIDIA, lo más cómodo es instalar la versión preparada específicamente para una versión concreta de CUDA, por ejemplo, CUDA 11.8. PyTorch proporciona índices específicos para ruedas compatibles.
Una vez que tienes Python y pip o un entorno Conda listo, puedes ejecutar algo como:
pip3 install torch torchvision torchaudio –index-url https://download.pytorch.org/whl/cu118
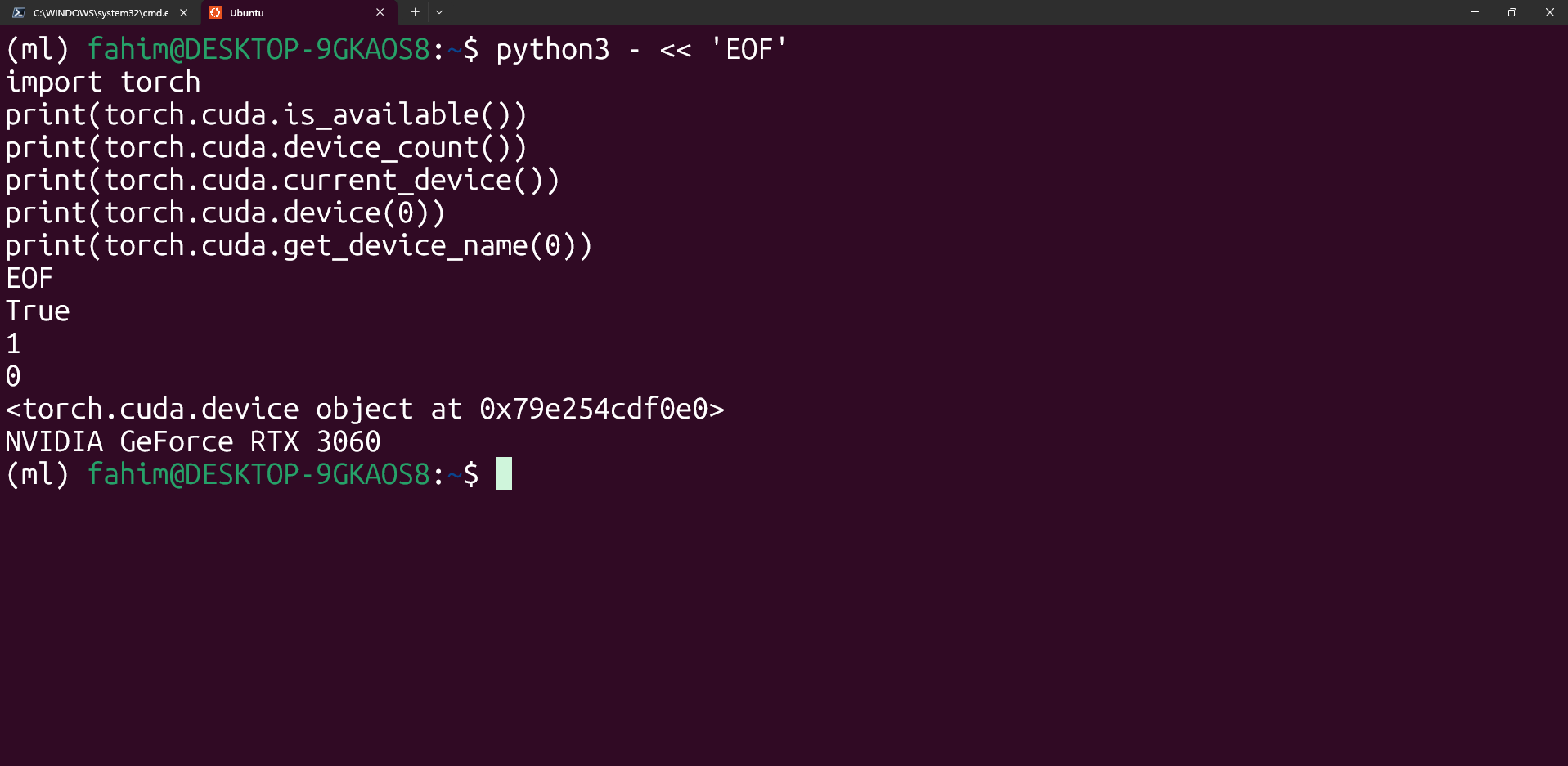
Para verificar que PyTorch ve correctamente la GPU, entra en la consola interactiva de Python dentro de WSL2 y ejecuta:
import torch
torch.cuda.device_count()
torch.cuda.is_available()
El primer comando importa PyTorch, el segundo te indica cuántos dispositivos compatibles con CUDA detecta el sistema, y el tercero te devuelve un True si la GPU está disponible para el framework. Si algo falla, lo habitual es revisar drivers, versión de CUDA y si WSL está actualizado.
En entornos con multi-GPU, desde PyTorch también puedes restringir el uso a ciertas tarjetas usando variables de entorno como CUDA_VISIBLE_DEVICES o APIs específicas de selección de dispositivo, algo útil cuando compartes el equipo con más procesos o usuarios.
TensorFlow con CUDA en WSL2 y flujo de ML completo
TensorFlow también puede aprovechar la GPU en WSL2 vía CUDA, especialmente cuando lo combinas con imágenes de Docker de NVIDIA o con instalaciones cuidadas desde los repos de CUDA y cuDNN. El flujo habitual incluye:
1) Instalar el driver de NVIDIA con soporte para CUDA en Windows, como ya hemos comentado, asegurando que la versión es compatible con la release de TensorFlow que vayas a usar.
2) Configurar en WSL2 el CUDA Toolkit y cuDNN siguiendo la guía oficial de NVIDIA CUDA en WSL.
3) Opcionalmente, usar una imagen NGC de TensorFlow con soporte GPU, que ya viene ajustada con las versiones correctas de CUDA/cuDNN, evitando el baile de librerías.
Una vez que tu entorno reconoce la GPU (lo puedes comprobar con nvidia-smi desde WSL2), puedes entrenar modelos intensivos directamente desde Linux en Windows, sin máquinas virtuales completas ni necesidad de subir todo a la nube. Lo normal es combinar esto con VS Code Remote – WSL y Jupyter para trabajar en notebooks cómodamente.
Para quienes empiezan, una buena forma de coger soltura es probar ejemplos simples de redes neuronales, monitorizar el consumo en nvidia-smi y experimentar con el tamaño de batch, número de capas o precision (FP16/FP32) para ver cómo varía la carga de la GPU.
Verificación de acceso a la GPU y monitorización
Verificar que todo está bien configurado es clave antes de lanzarse a entrenar modelos grandes. Desde WSL2, el comando estrella es nvidia-smi, que debería mostrar la lista de GPUs, memoria total y usada, proceso que consume GPU, temperatura, etc.
Si el comando devuelve un mensaje tipo “No devices were found”, suele ser indicio de que el driver de Windows no está bien instalado o WSL no está actualizado. En muchos casos se soluciona con:
wsl –shutdown
y volviendo a abrir la distribución para que se recargue el entorno, o bien actualizando drivers y reiniciando el sistema. También existen herramientas adicionales como gpustat que dan un resumen más amigable de la carga de las GPUs.
Durante entrenamientos largos, conviene dejar una consola aparte con nvidia-smi o scripts de monitorización para vigilar temperatura, consumo de memoria y utilización. Esto ayuda a detectar cuellos de botella (por ejemplo, quedarte corto de VRAM) o problemas de rendimiento por configuración deficiente.
Selección de GPU en equipos con varias tarjetas (NVIDIA, AMD, iGPU)
En portátiles y sobremesas modernos es frecuente tener varias GPUs: por ejemplo, una iGPU Intel o chip AMD integrado y una NVIDIA dedicada. Desde WSL2, especialmente con WSLg para apps gráficas, es importante poder elegir cuál se usa.
Microsoft documenta mecanismos para seleccionar la GPU en WSLg, y usuarios que se han visto en la situación de que su aplicación tiraba de la iGPU han resuelto el problema siguiendo la guía oficial de selección de GPU en WSLg disponible en el repositorio de GitHub de microsoft/wslg.
Además, para entornos donde se apoya DirectML en varias GPUs, se puede escoger un dispositivo concreto mediante la variable de entorno:
export MESA_D3D12_DEFAULT_ADAPTER_NAME=»<NombreTalComoSaleEnDeviceManager>»
Esta variable hace una coincidencia de cadena con los nombres de los adaptadores, por lo que si pones algo como «NVIDIA», seleccionará la primera GPU cuyo nombre comience por NVIDIA. Es un truco útil cuando el sistema elige por defecto la GPU equivocada (por ejemplo, priorizando una AMD integrada frente a una NVIDIA dedicada para ciertas cargas de ML).
En casos especialmente puñeteros (por ejemplo, al usar FAISS u otros componentes dentro de frameworks como LangChain u Ollama), puede que veas que se engancha a la GPU equivocada incluso cuando NVIDIA está visible en WSL. Ahí suele tocar combinar la configuración de WSLg, la variable de entorno anterior y ajustes específicos de cada librería para forzar el dispositivo correcto.
Buenas prácticas y resolución de problemas frecuentes
Una vez que todo está funcionando, hay algunas buenas prácticas que marcan la diferencia en comodidad y rendimiento del día a día. La primera es trabajar siempre con entornos virtuales de Python o conda, y activarlos antes de lanzar cualquier entrenamiento:
source ~/.venvs/ml/bin/activate (o el comando equivalente en tu configuración)
Mantener un archivo requirements.txt actualizado con las dependencias clave (por ejemplo, usando pip freeze > requirements.txt) facilita reconstruir el entorno en otra máquina o después de un formateo sin dolores de cabeza.
Otra recomendación importante es evitar trabajar directamente en /mnt/c/ para datos de entrenamiento o proyectos grandes. El rendimiento de disco suele ser mucho mejor si usas el home de Linux en WSL (por ejemplo, ~/proyectos_ml), sobre todo cuando trabajas con muchos ficheros o grandes volúmenes de datos.
Para desarrollo interactivo, VS Code con la extensión Remote – WSL y soporte para Jupyter ofrece una experiencia muy cómoda: editas en Windows, ejecutas en Linux con GPU, y todo queda bastante integrado. Además, puedes usar herramientas como tmux o screen para dejar entrenamientos corriendo en segundo plano aunque cierres la ventana de la terminal.
Si compartes la máquina o tienes procesos pesados en paralelo, puede interesarte ajustar límites de recursos en el archivo .wslconfig de Windows (por ejemplo, RAM y número de cores que WSL2 puede usar), y controlar manualmente en qué momentos lanzas entrenamientos gordos para no colapsar el equipo.
En cuanto al troubleshooting, los fallos más típicos incluyen que nvidia-smi no detecte la GPU (driver incorrecto o WSL desactualizado), incompatibilidades entre versiones de CUDA y los frameworks (PyTorch/TensorFlow) e instalaciones de CUDA directamente desde la web sin seguir los repos y guías oficiales para WSL, lo que suele acabar en conflictos de librerías. En general, es mejor apoyarse en los repos y documentación específica para WSL que en instalaciones genéricas.
Con todos estos elementos bien configurados —Windows 11 o 10 moderno, WSL2 actualizado, drivers de GPU correctos, CUDA/cuDNN en la distro, Docker y/o DirectML según el caso— puedes tener en tu propio portátil o sobremesa un entorno Linux de alto rendimiento para IA y ML sin renunciar a la comodidad de Windows. Es una solución híbrida muy potente que, bien afinada, te permite entrenar modelos complejos, prototipar flujos de trabajo y depurar código de forma ágil sin depender tanto de máquinas virtuales pesadas o de la nube.
Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.