- JupyterLab es la evolución de Jupyter Notebook, con una interfaz flexible que integra notebooks, consolas, terminales y visores en un único entorno web.
- La instalación puede hacerse con pip, conda o en servidores remotos, y se recomienda combinarla con entornos virtuales y kernels dedicados para aislar proyectos.
- Los kernels gestionan la ejecución del código y permiten trabajar con múltiples lenguajes y motores como Python, R, Spark o AWS Glue desde el mismo JupyterLab.
- El ecosistema de extensiones y buenas prácticas de gestión convierten JupyterLab en una herramienta robusta para ciencia de datos, Big Data y aprendizaje automático.
JupyterLab se ha convertido en una de las herramientas clave para quienes trabajan con ciencia de datos, aprendizaje automático, Big Data o simplemente quieren un entorno cómodo para programar en Python y otros lenguajes. Es como tener un IDE moderno dentro del navegador, pero pensado desde cero para trabajar con notebooks, datos y visualizaciones de forma interactiva.
Si estás buscando un tutorial de JupyterLab en español, claro y práctico, en esta guía vas a encontrar todo lo necesario: qué es, cómo instalarlo paso a paso con distintas opciones (pip, conda, servidores remotos, WSL2…), cómo usar sus notebooks, consolas, terminales, kernels, entornos virtuales y hasta cómo integrarlo con proyectos reales como modelos de visión por computador (por ejemplo, YOLO) o scripts de ETL en la nube.
Qué es JupyterLab y en qué se diferencia de Jupyter Notebook
JupyterLab es la evolución natural de Jupyter Notebook: una interfaz web de código abierto que reúne en un solo sitio notebooks, editores de texto, terminales, visores de archivos y consolas de código interactivo. Todo esto corre sobre el servidor de Jupyter, pero con una capa visual mucho más potente y flexible.
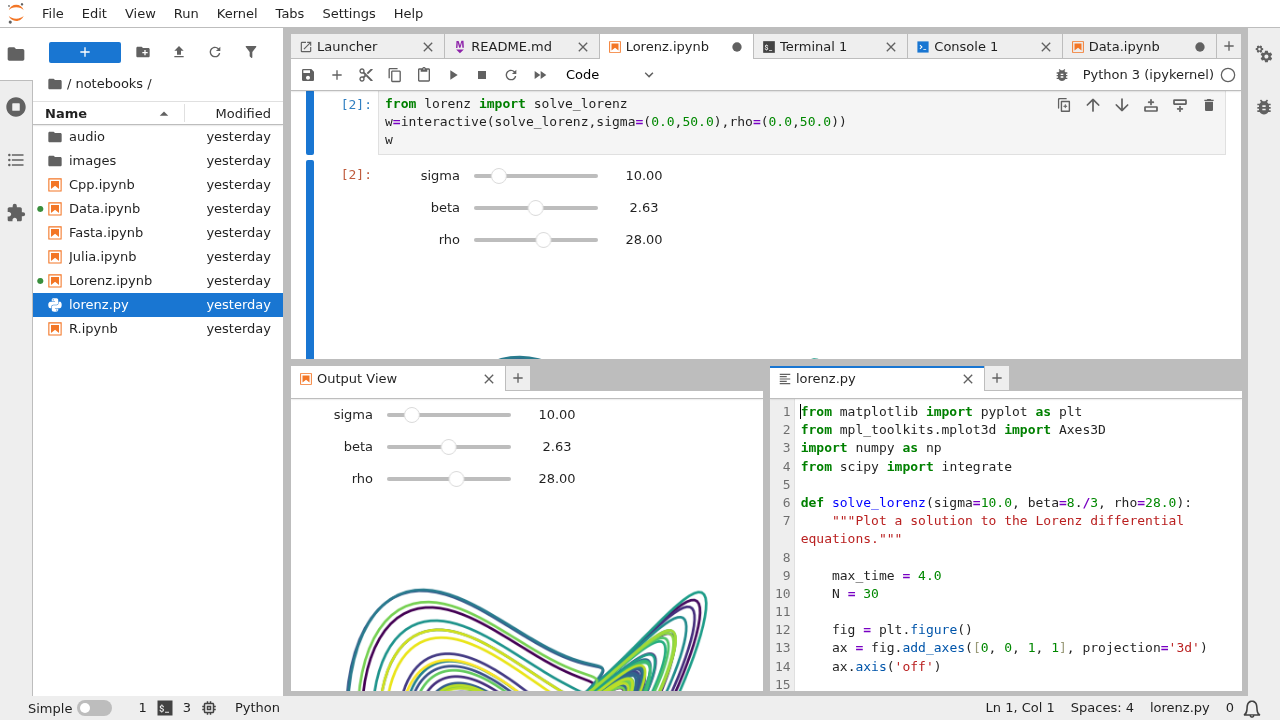
A diferencia del clásico Jupyter Notebook, que se limitaba a mostrar una lista de archivos y abrir un único notebook en pestañas del navegador, JupyterLab permite organizar el espacio de trabajo con paneles, pestañas y secciones divididas. Puedes ver varios notebooks a la vez, un notebook y su terminal, o un archivo de texto junto a un visor de CSV sin salir del navegador.
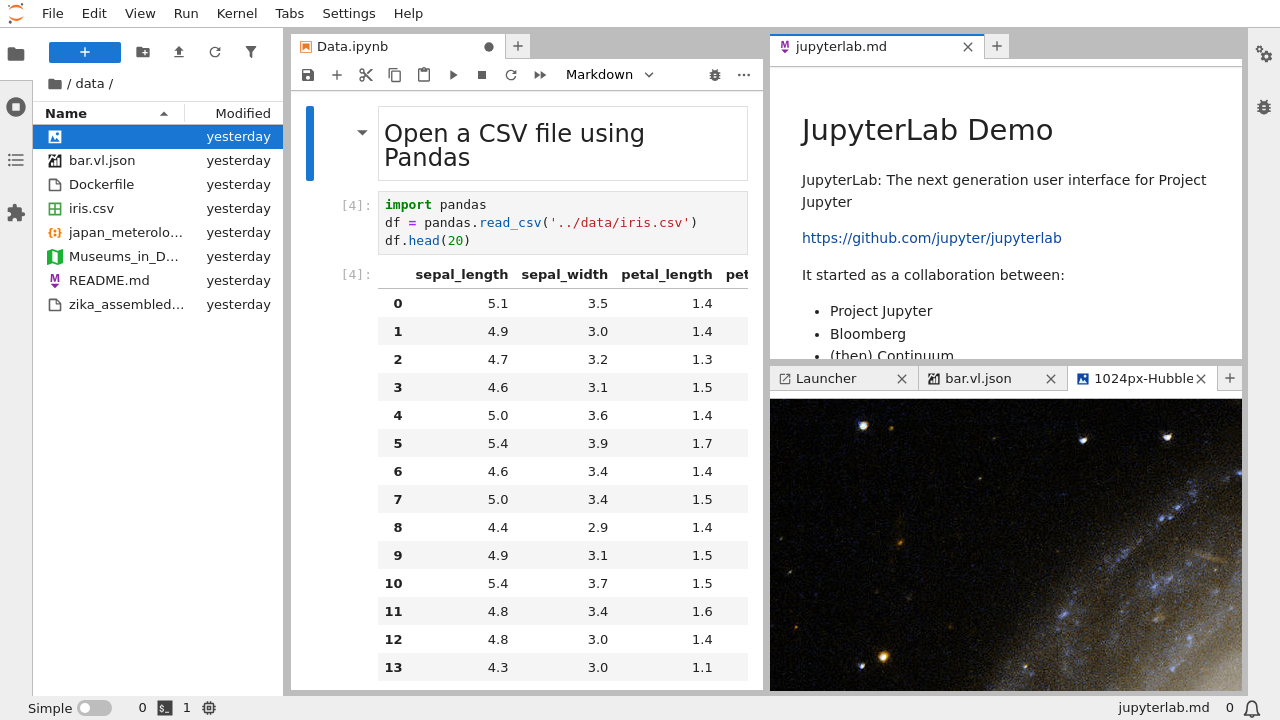
El corazón de JupyterLab son los notebooks (ficheros .ipynb): documentos interactivos compuestos por celdas que pueden contener código ejecutable, texto con formato (Markdown), ecuaciones, imágenes, tablas y salidas gráficas. Esto hace que sea ideal para análisis de datos, prototipado de modelos, documentación viva de procesos e, incluso, para enseñar y aprender programación.
Otro punto clave es que JupyterLab no se limita a Python. Aunque lo habitual es usarlo con Python 3, puede trabajar con muchos otros lenguajes gracias a los kernels: R, Scala, JavaScript, e incluso entornos especializados como los de Apache Spark o AWS Glue, siempre que instales el kernel o extensión correspondiente.
Además, JupyterLab incluye varias funciones modernas que refuerzan el trabajo en equipo: integración con sistemas de control de versiones, colaboración en tiempo real en algunas configuraciones, ecosistema de extensiones muy amplio, y facilidad para publicar, compartir y revisar notebooks en plataformas como GitHub o GitLab.
Instalar JupyterLab: opciones y escenarios habituales
JupyterLab se puede instalar en prácticamente cualquier sistema operativo: Linux, macOS, Windows (incluyendo WSL2) e incluso desplegarse en servidores remotos en la nube. Dependiendo de tu caso de uso, te interesará una vía u otra.
Instalación con Python y pip en Linux, macOS o WSL2
La forma más directa y estándar de instalar JupyterLab es tener un Python base en tu sistema y usar pip para instalar los paquetes necesarios. En un entorno tipo Ubuntu (nativo o mediante WSL2 en Windows), el flujo típico sería:
1. Instalar una versión estable de Python con el gestor de paquetes del sistema. Por ejemplo, en Ubuntu:
sudo apt install python3.9
2. Comprobar que Python está correctamente instalado ejecutando:
python3 --version
Si no funciona, puedes probar:
python --version
3. Verificar que tienes disponible pip (el instalador de paquetes de Python). Según cómo se haya instalado Python, puede ser:
pip3 --version
Si no responde, prueba con:
pip --version
4. Instalar Jupyter Notebook y después JupyterLab sobre ese Python base:
pip install jupyter
pip install jupyterlab
Una vez instalados los paquetes, basta con ir a la carpeta donde quieras trabajar, crear si te apetece un directorio de proyectos y arrancar el servidor:
mkdir proyectos
cd proyectos
jupyter lab
El comando abrirá el servidor en tu máquina local y mostrará una URL del tipo http://localhost:8888/lab que puedes pegar en el navegador. Desde ahí ya tendrás acceso al entorno de JupyterLab, y todos los notebooks que crees se guardarán en la carpeta desde la que lanzaste el comando.
Instalar JupyterLab con conda
Si trabajas con Anaconda o Miniconda, también puedes instalar JupyterLab mediante conda, que gestiona entornos y paquetes de forma aislada. Es una opción muy usada en ciencia de datos porque facilita tener distintas versiones de Python y librerías.
En un entorno con conda activo, bastaría algo como:
conda install -c conda-forge jupyterlab
La ventaja de conda frente a pip es que te permite separar proyectos en entornos distintos con sus propias dependencias, lo que reduce conflictos de versiones cuando trabajas con muchos paquetes de ciencia de datos, Spark, bibliotecas de deep learning, etc.
Despliegue en servidores remotos y nubes
Para entornos profesionales es muy habitual desplegar JupyterLab en servidores Linux remotos. Desde allí puedes acceder mediante el navegador a través de Internet o de una red privada, lo que encaja bien con proyectos colaborativos o infraestructuras con GPUs potentes.
Algunos proveedores cloud ofrecen imágenes preparadas donde JupyterLab ya viene instalado y preconfigurado. En esos casos, al crear un servidor nuevo solo tienes que seleccionar la imagen de JupyterLab, esperar unos minutos y después entrar a la IP pública con tu navegador. Normalmente, la clave de acceso coincide con la contraseña de administración del servidor.
También puedes montar JupyterLab sobre entornos especializados, por ejemplo, conectándolo a puntos de enlace de desarrollo de AWS Glue o a clústeres de Spark. En estos casos, además de instalar JupyterLab, necesitarás componentes como Sparkmagic o kernels específicos y usar túneles SSH para redirigir puertos desde tu máquina local al entorno remoto.
Primeros pasos en la interfaz de JupyterLab
Cuando se abre JupyterLab en el navegador, lo primero que verás es el Launcher (lanzador) y, a la izquierda, una barra lateral con el explorador de archivos. Desde el Launcher puedes crear notebooks, consolas de código, terminales, documentos de texto, archivos Markdown y más.
El explorador de archivos funciona de forma muy similar a un gestor de archivos clásico: puedes navegar por carpetas, renombrar, borrar, crear directorios nuevos o abrir ficheros con un doble clic. Esto convierte a JupyterLab en algo mucho más parecido a un IDE web que al antiguo listado plano de Jupyter Notebook.
La parte central de la interfaz está dividida en pestañas y paneles. Puedes arrastrar una pestaña hacia los laterales para dividir la vista en columnas o filas, y así visualizar varios documentos al mismo tiempo. Por ejemplo, un notebook a la izquierda y una consola de Python a la derecha, o dos vistas del mismo notebook en paralelo.
En la parte superior tienes la barra de menús y la barra de herramientas del notebook activo. Desde ahí puedes acceder a opciones como guardar, añadir celdas, cambiar el tipo de celda, ejecutar todo el documento, reiniciar el kernel, abrir una consola asociada, etc.
Crear y manejar notebooks en JupyterLab
Para crear tu primer notebook en JupyterLab, desde el Launcher haz clic en la opción de Notebook bajo el kernel de Python 3 (o el kernel que quieras usar). También puedes ir a File > New > Notebook. Se abrirá un archivo nuevo, normalmente con nombre Untitled.ipynb.
Puedes renombrar el notebook fácilmente haciendo clic derecho sobre el archivo en el explorador de la izquierda y seleccionando “Rename”. Dale un nombre significativo y mantén la extensión .ipynb, por ejemplo, MiPrimerProyecto.ipynb.
Los notebooks se componen de celdas. Cada celda puede ser de tipo código, Markdown u otros tipos especiales. Lo habitual es mezclar celdas de código Python, con celdas de texto explicativo en Markdown, y salidas gráficas resultantes de ejecutar el código.
Para ejecutar el contenido de una celda de código puedes usar el botón de “play” de la barra de herramientas o la combinación de teclas Shift + Enter. La salida (texto, gráficos, tablas…) aparecerá justo debajo de esa celda. En las celdas Markdown, al ejecutarlas se mostrará el texto formateado, con encabezados, listas, enlaces, imágenes, etc.
Modos de trabajo: comando y edición
El flujo de uso de un notebook se apoya en dos modos muy claros: el modo comando y el modo edición. Entenderlos te ahorra un montón de clics y hace que trabajar con notebooks sea mucho más ágil.
El modo comando se usa para operar sobre celdas completas (insertar nuevas, borrarlas, copiarlas, pegarlas, moverlas…). Se activa cuando el borde de la celda está resaltado (sin cursor de texto dentro). Desde este modo puedes usar accesos rápidos como:
- Flechas arriba/abajo para cambiar la celda activa.
- A para insertar una celda encima.
- B para insertar una celda debajo.
- X para cortar la celda seleccionada.
- C para copiarla y V para pegarla.
En el modo edición trabajas dentro del contenido de la celda, escribiendo código o texto. En este modo ves el cursor de texto dentro de la celda. Se entra haciendo doble clic sobre ella o pulsando Enter cuando estás en modo comando.
Puedes cambiar el tipo de celda (de código a Markdown, por ejemplo) usando el desplegable de la barra de herramientas del notebook o mediante accesos rápidos de teclado. Esto permite documentar tu código en el mismo documento y crear informes reproducibles muy completos.
Kernels: el motor que ejecuta tu código
En la arquitectura de Jupyter, el kernel es el proceso que ejecuta el código de un notebook. Cada documento tiene asociado un kernel concreto (Python 3, R, Scala, JavaScript, Spark, etc.), y todas las celdas de código del notebook se ejecutan en ese mismo proceso.
Esto implica que todas las celdas comparten el mismo espacio de memoria. Si defines una variable en una celda, podrás usarla en las siguientes, siempre que el kernel no se haya reiniciado. Además, puedes ejecutar una misma celda varias veces y el estado irá evolucionando según el orden en que se lanzan las ejecuciones.
Para seguir el orden de ejecución, a la izquierda de cada celda aparece un número entre corchetes (por ejemplo, In [3]). Ese índice indica el turno en el que se ejecutó dicha celda respecto al resto, lo que ayuda a entender cómo se ha construido el estado actual del kernel.
Desde el menú “Kernel” de la parte superior puedes reiniciar el kernel, detenerlo, reiniciar y limpiar todas las salidas, o incluso cambiar de kernel si el documento admite varios. Esto es fundamental cuando instalas nuevas librerías, cambias de entorno o quieres garantizar que ejecutas todo “desde cero”.
Añadir y usar otros kernels en JupyterLab
De serie, lo más habitual es trabajar con Python, pero JupyterLab soporta toda una colección de kernels desarrollados por terceros: R, Scala, JavaScript, kernels para Spark, kernels integrados con servicios de nube, etc.
Para añadir un kernel nuevo normalmente hay dos pasos: instalar el soporte del lenguaje en tu sistema (por ejemplo, un intérprete de R o Scala) y luego instalar el paquete que integra ese lenguaje con Jupyter (como IRkernel para R, o un kernel de JavaScript concreto). Cada kernel suele documentar en su repositorio de GitHub el comando que necesitas ejecutar para registrar el kernel en Jupyter.
Una vez instalado el kernel adicional, aparecerá en el Launcher y en los desplegables de selección de kernel dentro de los notebooks. A partir de ahí, puedes crear nuevos documentos o cambiar el kernel de uno existente para trabajar con ese lenguaje.
Consolas de código y terminales en JupyterLab
Además de notebooks, JupyterLab ofrece consolas de código interactivas muy útiles para probar rápidamente fragmentos de código, inspeccionar funciones o ir registrando cálculos según trabajas con un notebook principal.
Puedes crear una consola desde el menú File > New > Console. Esto abrirá una ventana de consola vinculada a un kernel, similar a un intérprete interactivo (REPL). Es perfecto para experimentar sin “ensuciar” el notebook con pequeñas pruebas.
También puedes vincular una consola a un notebook ya existente, de modo que compartan el mismo kernel. Así, lo que ejecutes en el notebook estará disponible en la consola, y viceversa. Esta opción aparece en el menú contextual haciendo clic derecho sobre la pestaña del notebook.
JupyterLab permite además abrir terminales de sistema, donde ejecutas comandos de shell directamente en el servidor donde corre Jupyter. Se crean desde File > New > Terminal, y muestran el sistema de archivos real, lo que te permite crear carpetas, gestionar entornos virtuales, instalar paquetes, o lanzar scripts externos sin salir del navegador.
Entornos virtuales y kernels dedicados en Jupyter Notebooks
En proyectos de Python es muy recomendable usar entornos virtuales para aislar dependencias y versiones de librerías entre proyectos. Esto es igual de importante cuando trabajas con JupyterLab, especialmente si manejas distintos stacks de ciencia de datos o machine learning.
Un flujo típico para trabajar con entornos virtuales y Jupyter podría ser el siguiente, ejecutado desde un terminal del sistema (por ejemplo, el propio terminal de JupyterLab):
1. Crear una carpeta para tu proyecto y entrar en ella:
mkdir miproyecto
cd miproyecto
2. Crear un entorno virtual con venv (u otra herramienta similar):
python3 -m venv .myenv
3. Activar ese entorno en la consola:
source .myenv/bin/activate
4. Instalar las librerías que necesites dentro del entorno, por ejemplo ipykernel para exponerlo a Jupyter:
pip install ipykernel
5. Registrar un kernel específico asociado a ese entorno con un nombre reconocible:
ipython kernel install --user --name=miproyecto
Después de estos pasos, al crear un nuevo notebook en JupyterLab podrás elegir el kernel “miproyecto”. Esto garantiza que ese notebook use el entorno virtual correcto, con sus dependencias y versiones separadas del resto del sistema.
Recuerda que si instalas nuevas librerías con pip dentro de un entorno ya en uso por Jupyter, puede que tengas que reiniciar el kernel del notebook para que las nuevas dependencias estén disponibles.
Configuraciones avanzadas: Spark, AWS Glue y port forwarding
JupyterLab se utiliza también en escenarios de Big Data, donde necesitas conectarte a motores como Apache Spark o servicios gestionados en la nube, por ejemplo AWS Glue. En estos entornos, los notebooks sirven como front-end interactivo para scripts de ETL, análisis distribuidos y pruebas antes de desplegar el código definitivo.
En el caso de AWS Glue, un patrón común es conectar JupyterLab que corre en tu máquina local a un punto de enlace de desarrollo remoto. Para eso se suelen usar dos piezas básicas: Sparkmagic (para hablar con el servidor de Spark) y un túnel SSH que reenvíe el puerto local al endpoint de Glue.
Los pasos generales son instalar JupyterLab (por pip o conda), instalar Sparkmagic, arrancar JupyterLab y, antes de empezar a ejecutar código, abrir el port forwarding con un comando tipo:
ssh -i private-key-file-path -NTL 8998:169.254.76.1:8998 glue@dev-endpoint-public-dns
Dejando abierto ese terminal con el túnel, puedes comprobar que la redirección funciona con una llamada como:
curl localhost:8998/sessions
Una vez validado el túnel, los notebooks de JupyterLab pueden conectarse al endpoint remoto y ejecutar scripts de PySpark o Glue, permitiéndote probar y depurar procesos de ETL con datos reales antes de desplegarlos en producción.
JupyterLab para proyectos de aprendizaje automático y YOLO
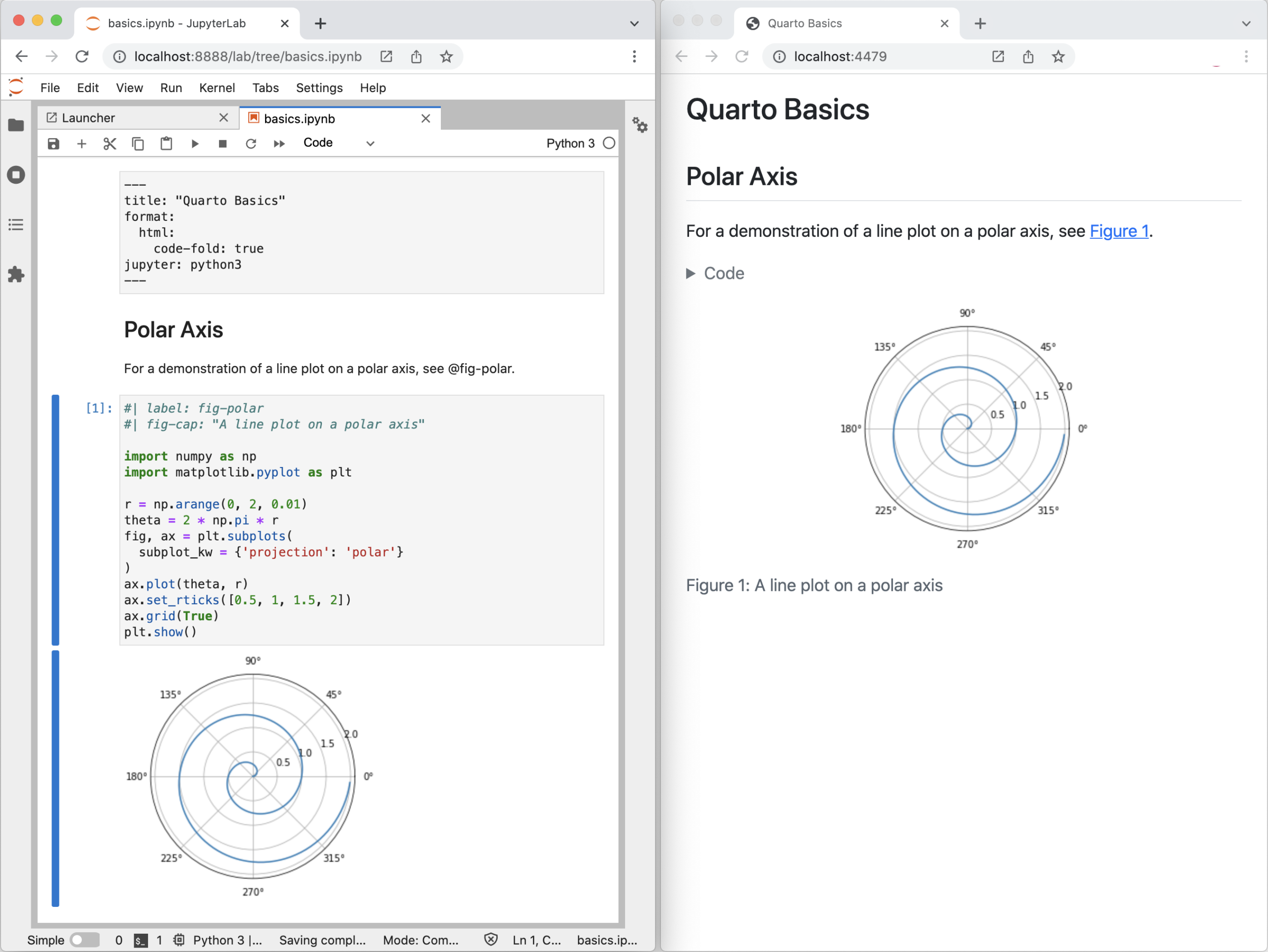
JupyterLab encaja muy bien en flujos de trabajo de deep learning, donde necesitas iterar rápido sobre datasets, modelos, hiperparámetros y visualizaciones. Un ejemplo típico son los proyectos con modelos de detección de objetos como YOLO.
En un escenario local, puedes usar JupyterLab para descargar cuadernos de ejemplo desde repositorios (por ejemplo, cuadernos tutoriales de YOLO), abrirlos, ejecutar sus celdas y adaptarlos a tus propios datos. El entorno interactivo te permite modificar código, ver resultados al vuelo, inspeccionar métricas y documentar cada experimento.
El flujo habitual suele ser: instalar JupyterLab y los paquetes de deep learning necesarios, descargar el notebook tutorial de la librería que uses (por ejemplo desde GitHub), situarlo en un directorio de trabajo, lanzar jupyter lab, abrir el cuaderno y ejecutar las celdas una por una para entender y adaptar el proceso de entrenamiento y evaluación.
Al trabajar con GPUs y grandes modelos, JupyterLab facilita además el diagnóstico de problemas de memoria, la visualización de curvas de entrenamiento, la exploración de métricas de rendimiento y la comparación de configuraciones, todo sin salir del navegador.
Características clave que hacen tan cómodo JupyterLab
Más allá de lo básico, JupyterLab incorpora una serie de detalles que, en el día a día, marcan mucha diferencia respecto al Jupyter clásico o a otros entornos:
- Espacio de trabajo unificado: notebooks, editores de texto, vistas de imágenes, PDF, CSV, consolas y terminales, todo bajo la misma interfaz y con posibilidad de ver varios elementos a la vez.
- Diseño flexible con pestañas y paneles: arrastra y suelta para organizar tu entorno como quieras; por ejemplo, código a la izquierda, gráficos arriba a la derecha y terminal abajo a la derecha.
- Vista previa de Markdown en tiempo real: puedes escribir documentación en formato Markdown y ver cómo queda al instante, sin tener que cambiar constantemente de modo.
- Ejecutar código desde archivos de texto: si abres un
.pyo un archivo de texto, puedes seleccionar fragmentos de código y ejecutarlos con Shift + Enter en el kernel activo. - Copiar y mover celdas entre notebooks: basta con arrastrar celdas de un notebook a otro o usar copiar/pegar, lo que agiliza mucho la reutilización de bloques de código.
- Múltiples vistas del mismo notebook: puedes abrir varias vistas simultáneas de un mismo documento para comparar secciones lejanas sin estar subiendo y bajando por el scroll.
- Temas personalizables: incluye tema claro y oscuro, y soporta temas adicionales para ajustar colores al gusto.
- Ecosistema de extensiones: desde paneles de Git hasta herramientas de cómputo remoto, tableros de monitorización y más, que amplían mucho las capacidades base.
Problemas frecuentes y buenas prácticas al usar JupyterLab
Al trabajar intensivamente con JupyterLab, es normal encontrarse con ciertos problemas típicos, sobre todo en proyectos pesados o entornos compartidos. Tener claro cómo afrontarlos te ahorra muchos sustos.
Gestión de kernels en segundo plano es uno de los puntos clave. Aunque cierres la pestaña del navegador, el kernel puede seguir activo en el servidor, consumiendo memoria y CPU. Desde la interfaz de JupyterLab, en la barra lateral o el menú, puedes ver qué kernels están corriendo y pararlos explícitamente con la opción de apagado.
Otro tema habitual son los paquetes de Python que “faltan” en un entorno. Si estás en un servidor o instalación donde no tienes todo lo que necesitas, puedes instalar paquetes adicionales con algo como:
python -m pip install nombre-paquete
Si manejas muchos proyectos con dependencias diferentes, compensa crear entornos separados (conda o venv) y asignar un kernel distinto para cada proyecto. Esto reduce conflictos de versiones y hace más fácil actualizar librerías sin romper otros notebooks.
En proyectos de deep learning y Big Data, las caídas del kernel suelen estar relacionadas con falta de memoria (RAM o GPU) o con fugas debidas a bucles sobre grandes volúmenes de datos. Reducir el tamaño de lote, limpiar memoria entre ejecuciones (por ejemplo con funciones específicas en frameworks como PyTorch) y reiniciar periódicamente el kernel son estrategias muy efectivas.
Por último, no olvides cerrar el servidor de JupyterLab cuando termines de trabajar. En la consola donde lo lanzaste, puedes detenerlo con Ctrl + C. Esto libera recursos y evita dejar servicios escuchando en puertos que no necesitas abiertos.
Con todo lo anterior, JupyterLab se consolida como un entorno versátil y muy potente tanto para aprender a programar como para montar flujos de trabajo profesionales de ciencia de datos, machine learning, ETL y Big Data. Entender su arquitectura de kernels, aprovechar los notebooks, consolas y terminales, y combinarlo con entornos virtuales y despliegues remotos te permite tener un “cuartel general” único para desarrollar, documentar y compartir prácticamente cualquier proyecto de datos.
Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.