- Un servidor HTTP ligero en PowerShell permite probar webs y APIs en entorno local sin desplegar IIS completo ni recurrir a otros lenguajes.
- El núcleo se basa en System.Net.HttpListener, una tabla de rutas y un objeto servidor con métodos para iniciar, detener y servir contenido estático o dinámico.
- Hooks de enrutado, detección de MIME, parseo de query y cuerpo y lectura segura de archivos aportan flexibilidad y seguridad al servidor.
- Para producción, PowerShell se integra con IIS y Web Deploy para automatizar sitios, bases de datos y reglas de delegación, facilitando el salto desde el entorno local.
Si trabajas con Windows y haces pruebas de aplicaciones web, APIs o simplemente quieres servir unos cuantos ficheros HTML y JavaScript, tener un servidor HTTP ligero en PowerShell para pruebas locales es de lo más cómodo. No siempre apetece montar IIS completo, ni tirar de Python, Node o paquetes tipo XAMPP solo para un test rápido.
La buena noticia es que con las herramientas que ya trae el sistema es posible montar un servidor muy pequeño, flexible y fácil de mantener, que va desde lo más básico (servir ficheros estáticos) hasta escenarios bastante elaborados (endpoints de API, parseo de formularios, control de MIME, seguridad básica, etc.), todo ello sin salir de PowerShell.
Por qué usar un servidor HTTP ligero para pruebas locales
Cuando abres un archivo HTML con doble clic, el navegador lo carga con el esquema file:// en lugar de http:// o https://. Esto suele ir bien para cosas muy sencillas, pero se rompe en cuanto entras en terreno un poco serio.
Muchos ejemplos modernos de JavaScript usan peticiones asíncronas (fetch, XHR, etc.) y varios navegadores, con Chrome a la cabeza, aplican restricciones de seguridad muy estrictas a los recursos sirviendo desde file://, bloqueando llamadas AJAX o acceso a ciertos recursos por políticas CORS y similares.
Además, en cuanto entra en juego código de servidor como PHP, Python, Node.js o frameworks web, ya no basta con abrir el archivo directamente: necesitas un proceso que escuche en un puerto, reciba las peticiones HTTP y las traduzca en respuestas. Ahí es donde entra el servidor local.
En otros lenguajes, arrancar un servidor de desarrollo es casi instantáneo: python3 -m http.server 8000 levanta un servidor básico en Python con una sola línea. En el ecosistema .NET/Windows, podemos conseguir algo igual de cómodo usando PowerShell y la clase System.Net.HttpListener.
Este planteamiento tiene un plus añadido: si la mayor parte de tu infraestructura es Windows, quedarte en PowerShell te permite que cualquier administrador o compañero pueda entender, revisar y mantener el código del servidor sin necesidad de dominar otro lenguaje.
Concepto básico: enrutamiento HTTP en PowerShell
La mayoría de servidores web pueden verse como un enrutador HTTP que se queda escuchando en uno o varios puertos y, cada vez que llega una petición, decide qué hacer con ella en función del método (GET, POST, etc.) y de la ruta.
Esos “comandos HTTP” que ves en los logs o en la documentación —por ejemplo GET /index.html o POST /api/usuarios— se pueden tratar como cadenas de texto que incluyen el método y la ruta. A efectos prácticos, son la clave para decidir qué lógica ejecutar.
En PowerShell, un modelo muy cómodo para implementar este comportamiento es una tabla hash (diccionario) donde la clave es el comando HTTP completo (por ejemplo, «GET /index.html») y el valor es lo que vamos a ejecutar cuando llegue esa petición: puede ser un scriptblock con lógica ad hoc o una referencia a un fichero estático que queramos servir.
A partir de este esqueleto se puede ir añadiendo más extensibilidad: hooks antes y después del enrutado, una ruta por defecto para cuando no haya coincidencia exacta, inferencia de tipo MIME por extensión, conversión automática de lo que devuelva la ruta en cuerpo de respuesta, etc.
Así se puede definir un “mapa” de rutas en el que algunas entradas sean endpoints dinámicos (que generan una respuesta al vuelo) y otros sean simplemente ficheros HTML, CSS o JS que el servidor envía tal cual al cliente.
Sobre ese mismo esqueleto se puede ir añadiendo más potencia: hooks antes y después del enrutado, una ruta por defecto para cuando no haya coincidencia exacta, inferencia de tipo MIME por extensión, conversión automática de lo que devuelva la ruta en cuerpo de respuesta, etc.
Núcleo del servidor: el bucle de escucha HTTP

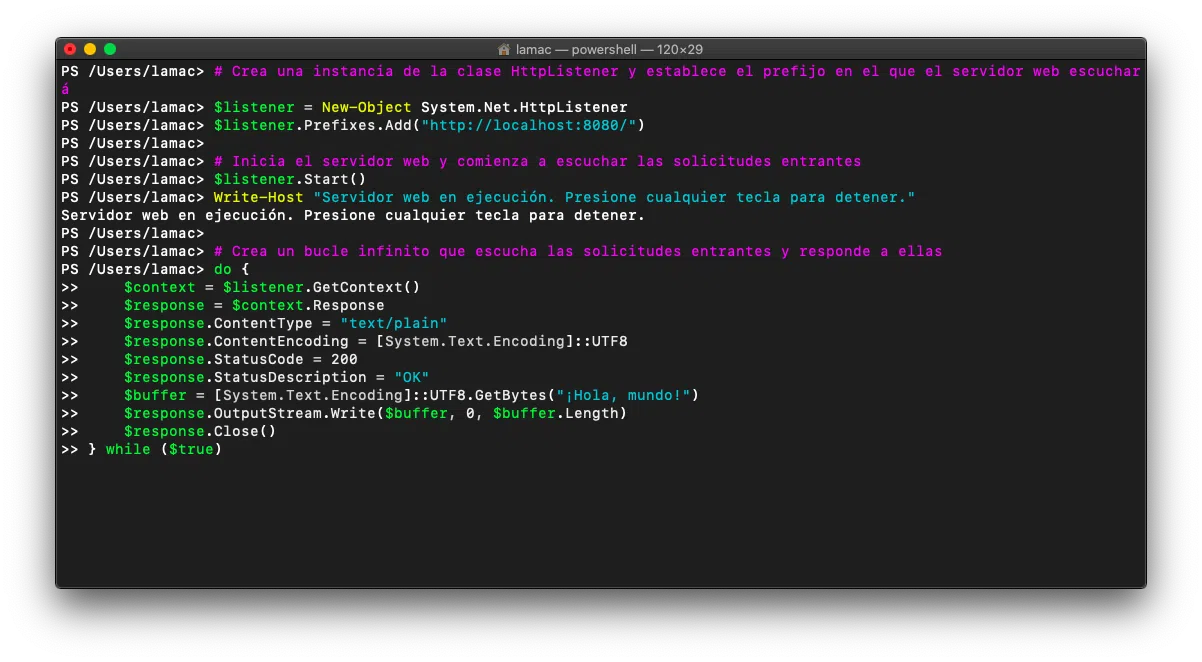
La pieza fundamental del servidor ligero es un bucle que usa System.Net.HttpListener. Esta clase de .NET permite escuchar peticiones HTTP sin montar todo IIS, de forma muy directa.
El patrón general consiste en crear un objeto HttpListener, registrar uno o varios prefijos (por ejemplo, «http://localhost:8080/»), arrancar el listener y luego entrar en un bucle que espera peticiones. Cuando llega una solicitud, se obtiene un contexto, se analiza la petición para construir el comando (método + ruta) y se pasa el control al enrutador.
Para no bloquear el hilo de PowerShell, se suele usar GetContextAsync() y un pequeño bucle de espera no bloqueante con un manejador asíncrono. Esto hace que el servidor pueda seguir ejecutando otras cosas o que puedas pararlo con orden sin que se quede colgado.
Del contexto se extrae el objeto Request (toda la información de la petición entrante: cabeceras, query string, cuerpo, etc.) y el objeto Response, que es el que vamos a rellenar con el contenido que generemos (estado HTTP, cabeceras, tipo de contenido, cuerpo, etc.).
Un detalle importante es que, una vez terminada la lógica de la ruta, siempre hay que cerrar la respuesta (Close). De lo contrario, el cliente se quedará esperando. Por eso es habitual envolver el manejo de cada petición en bloques try/finally que garanticen el cierre.
Convertir el servidor en un objeto reutilizable

Montar el HttpListener “a pelo” está bien para una prueba rápida, pero si vas a reutilizar este servidor en más de un script, te compensa encapsularlo en un objeto PowerShell con sus propiedades y métodos.
La forma habitual de hacerlo es crear una función fábrica, por ejemplo New-Webserver, que devuelva un psobject con varias propiedades: el binding (URL base tipo «http://localhost:8080/»), la tabla de rutas, el directorio base desde el que se servirán archivos, un nombre descriptivo del servidor, etc.
Sobre ese mismo objeto puedes añadir métodos de script como Start() y Stop(). El método Start se encarga de crear el HttpListener, registrar el binding y arrancar el bucle de escucha; Stop detiene el listener, cierra los recursos y deja al servidor en un estado limpio para otro arranque futuro.
Este diseño de “servidor como objeto” encaja muy bien con un estilo semi orientado a objetos dentro de PowerShell, hace el código más legible y te permite tener varios servidores independientes instanciados con diferentes puertos o directorios base si lo necesitas.
Además, puedes almacenar en ese mismo objeto referencias a otros métodos auxiliares (por ejemplo, para servir archivos, inferir MIME, parsear peticiones, etc.), lo que hace que el código de las rutas quede bastante elegante.
Enrutamiento avanzado: hooks y ruta por defecto

Un servidor algo más pulido necesita cierto grado de enrutado dinámico. No siempre vas a tener una coincidencia exacta para cada comando HTTP, ni quieres duplicar lógica en todas las rutas por tareas comunes (logs, autenticación casera, etc.).
Para esto resulta muy útil extender la tabla de rutas con tres tipos de hooks: un bloque Before, que se ejecuta antes de despachar la ruta; un bloque After, que se llama una vez gestionada la petición; y una ruta Default, que actúa como plan B cuando no hay coincidencia exacta en el diccionario.
La gracia es que todos los comandos HTTP válidos llevan al menos un espacio (separando método y ruta), mientras que las claves especiales como Before, After o Default no. Así se evita colisión entre nombres de hook y comandos reales.
El hook Before puede limitarse a hacer trabajo auxiliar (por ejemplo, registrar en log cada petición), o devolver un valor booleano que indique si se permite continuar con el proceso de enrutado. Si devuelve falso, se puede cortar el manejo de esa petición directamente en el bucle de escucha.
El hook After sirve para ejecutar lógica que deba ir siempre al final (limpieza, telemetría, métricas, trazas, etc.) independientemente de cómo haya ido la ruta concreta, idealmente recibiendo también la información del contexto y el comando.
Gestión de contenido y tipos MIME
Al trabajar directamente con HttpListener no tienes helpers automáticos como en IIS o Kestrel para inferir el Content-Type, así que hay que indicarlo a mano. Si quieres que tu servidor sirva ficheros correctamente, es imprescindible mapear extensiones de archivo a tipos MIME.
Una forma elegante de hacerlo es añadir al objeto servidor un método como ConvertExtension que reciba una extensión («.html», «.css», «.js», etc.) y devuelva la cadena MIME correspondiente, por ejemplo «text/html; charset=utf-8», «text/css; charset=utf-8» o «application/javascript; charset=utf-8».
De esta forma, cualquier ruta que se encargue de servir contenido estático o dinámico puede simplemente llamar a $server.ConvertExtension(«.html») y asignar el resultado a ContentType de la respuesta. Para el resto de extensiones desconocidas es habitual usar «application/octet-stream» como comodín.
También es buena idea fijar un tipo de contenido por defecto en el bucle de escucha, sobre todo si tu servidor está más orientado a APIs que a páginas web HTML completas. Un valor típico sería «text/plain; charset=utf-8» o incluso «application/json; charset=utf-8» si casi todo lo que devuelves es JSON.
Este comportamiento se puede complementar con cabeceras estándar como Last-Modified o Server, que ayudan a depurar desde el navegador y a que el cliente sepa algo más sobre la respuesta y el servidor origen.
Construcción automática de respuestas
Si en cada ruta tuvieras que encargarte manualmente de escribir en el stream, calcular la longitud del contenido, fijar cabeceras, etc., el código del servidor se llenaría de boilerplate repetitivo. Para evitarlo, conviene estandarizar la forma en la que el resultado de cada ruta se convierte en una respuesta HTTP.
Una estrategia cómoda consiste en que las rutas devuelvan simplemente una cadena de texto. El bucle de escucha central recoge ese valor y, si no es nulo ni vacío, lo transforma en bytes UTF-8, asigna ContentLength64, rellena las cabeceras básicas que falten, escribe el cuerpo y cierra la respuesta.
Alrededor de la invocación de la ruta es recomendable envolver el código en un bloque try/catch. Si algo falla en la lógica de la ruta, el servidor puede atrapar la excepción, fijar el estado HTTP a 500, y devolver un mensaje estándar del tipo «500 Internal Server Error» seguido del detalle del error, útil durante el desarrollo.
Esto reduce mucho el código necesario en cada endpoint: en muchos casos basta con que la ruta genere un string con JSON, HTML o texto plano y lo devuelva, sabiendo que la plomería HTTP (longitud, codificación, cierre) ya la resuelve el servidor base.
En los casos en los que una ruta decida gestionar por completo la respuesta (por ejemplo, escribiendo directamente en el stream y cerrándolo), el código central debe ser tolerante a que la respuesta esté ya cerrada y no intente escribir de nuevo, de ahí la importancia de capturar y silenciar ciertos errores al cerrar.
Servir archivos estáticos desde un directorio base
En muchos escenarios lo que necesitas es, simple y llanamente, servir ficheros estáticos: HTML, CSS, JavaScript, imágenes, etc. Para eso suele definirse en el objeto servidor una propiedad BaseDirectory, que indica la carpeta del disco desde la que se van a leer los contenidos.
Con ese directorio como referencia se puede añadir al servidor un método Serve, que reciba el nombre de un archivo y el objeto Response. El método lee el fichero con Get-Content -Raw, calcula la extensión, infiere el MIME con ConvertExtension, asigna el tipo de contenido y devuelve el contenido al bucle central para que lo envíe al cliente.
Si el archivo no existe o hay cualquier problema al leerlo, Serve puede asignar un 404 a la respuesta y devolver un mensaje «404 Not Found» personalizado. Esto simplifica bastante las rutas que solo quieren servir contenido estático.
Otro truco interesante es permitir que en la tabla de rutas el valor no sea siempre un scriptblock. Si detectas que la ruta apunta a una cadena de texto que representa un fichero, el bucle de escucha puede llamar directamente a $server.Serve() con esa ruta en vez de ejecutar código.
De esa forma, el diccionario de rutas podría tener entradas como «GET /» = «index.html», sin tener que escribir más lógica. E incluso la ruta por defecto puede estar implementada como un pequeño scriptblock que derive el nombre de archivo a partir de la URL y delegue en Serve.
Lectura avanzada y protección frente a rutas peligrosas
Cuando empiezas a servir rutas generadas dinámicamente, es importante controlar bien qué rutas del sistema de ficheros son accesibles. No quieres que alguien pueda hacer un ataque de path traversal tipo «../» y llegar a carpetas fuera de tu BaseDirectory.
Una forma flexible de abordar esto es permitir que el constructor del servidor acepte un scriptblock Reader opcional. Si el usuario pasa uno, ese será el encargado de “resolver” una ruta lógica (la parte de la URL) en una ruta física de disco, aplicando las reglas que considere oportunas.
Si no se proporciona un Reader personalizado, el servidor define uno por defecto que toma la ruta, elimina barras iniciales sobrantes, la combina con el directorio raíz, y luego intenta resolver el archivo con Resolve-Path. Si no encuentra el archivo directo, prueba alternativas como añadir «.html» o buscar un «index.html» dentro del directorio.
Tras esa resolución, conviene comprobar tres cosas: que la ruta no sea vacía ni inválida, que el resultado apunte a un archivo real (no directorio) y que se encuentre dentro del BaseDirectory (esto último se puede validar con un simple “empieza por la ruta raíz”). Si alguna de estas comprobaciones falla, se lanza una excepción indicando ruta no válida.
El método Serve se apoya en este Reader para obtener tanto la ruta física definitiva como el contenido. Así consigues separar claramente la parte de seguridad y resolución de caminos de la parte de envío de datos al cliente.
Parseo de peticiones: query string y cuerpo
Si solo vas a servir HTML estático, con leer archivos tienes de sobra, pero en cuanto montas una API o procesas formularios necesitas acceder a parámetros GET y POST de forma sencilla desde las rutas.
Para ello suele añadirse al objeto servidor un método ParseQuery que, a partir de un objeto Request, aproveche System.Web.HttpUtility.ParseQueryString para convertir el query string en una colección de nombre-valor muy cómoda de manejar en PowerShell.
Para los cuerpos de las peticiones (POST, PUT, etc.) es útil otro método como ParseBody. Este método primero comprueba si la petición realmente tiene entidad (HasEntityBody) y si el tamaño es mayor que cero. En tal caso, abre el stream de entrada, crea un StreamReader con la codificación apropiada y lee todo el contenido.
Después, en función del Content-Type declarado en la petición, se decide qué hacer con ese cuerpo: si es «application/x-www-form-urlencoded», se parsea como si fuera un query string; si es «application/json», se pasa por ConvertFrom-Json; si es «text/xml», se convierte a objeto XML; y si no coincide con ninguno de los patrones conocidos, se devuelve como cadena de texto sin más.
Estos métodos hacen que las rutas de tu servidor puedan centrarse en la lógica de negocio, delegando en el objeto servidor el trabajo más mecánico relacionado con cómo vienen los datos desde el cliente.
PowerShell e IIS: cuando necesitas un servidor completo
El servidor HTTP ligero en PowerShell es perfecto para pruebas locales y pequeños servicios internos, pero en cuanto quieres publicar aplicaciones web de forma seria hacia usuarios externos, toca hablar de IIS y herramientas como Web Deploy.
En entornos Windows Server (2008, 2012, 2016, 2019, 2022, etc.) puedes usar PowerShell para instalar el rol Web-Server con comandos como Get-WindowsFeature y Install-WindowsFeature, añadiendo además las herramientas de administración necesarias. Una vez instalado, puedes comprobar el estado desde Server Manager o mediante nuevo Get-WindowsFeature.
Tras la instalación, llegar a «http://127.0.0.1» desde el propio servidor debería mostrarte la página por defecto de IIS, confirmando que todo está operativo. A partir de aquí entran en juego los módulos de PowerShell orientados a administrar IIS (IISAdministration), que exponen cmdlets para crear sitios, gestionar bindings, arrancar o parar sitios, etc.
Scripts suministrados con Web Deploy, como SetupSiteForPublish.ps1, permiten automatizar la creación de un sitio de publicación, usuarios no administradores con permisos ajustados, pools de aplicaciones dedicados y la generación de ficheros .PublishSettings que luego consumen herramientas como Visual Studio o WebMatrix.
Comandos de PowerShell para gestionar IIS
Una vez tienes el servidor IIS desplegado, PowerShell se convierte en un aliado muy potente para crear sitios, probarlos, detenerlos o eliminarlos de forma repetible y scriptable.
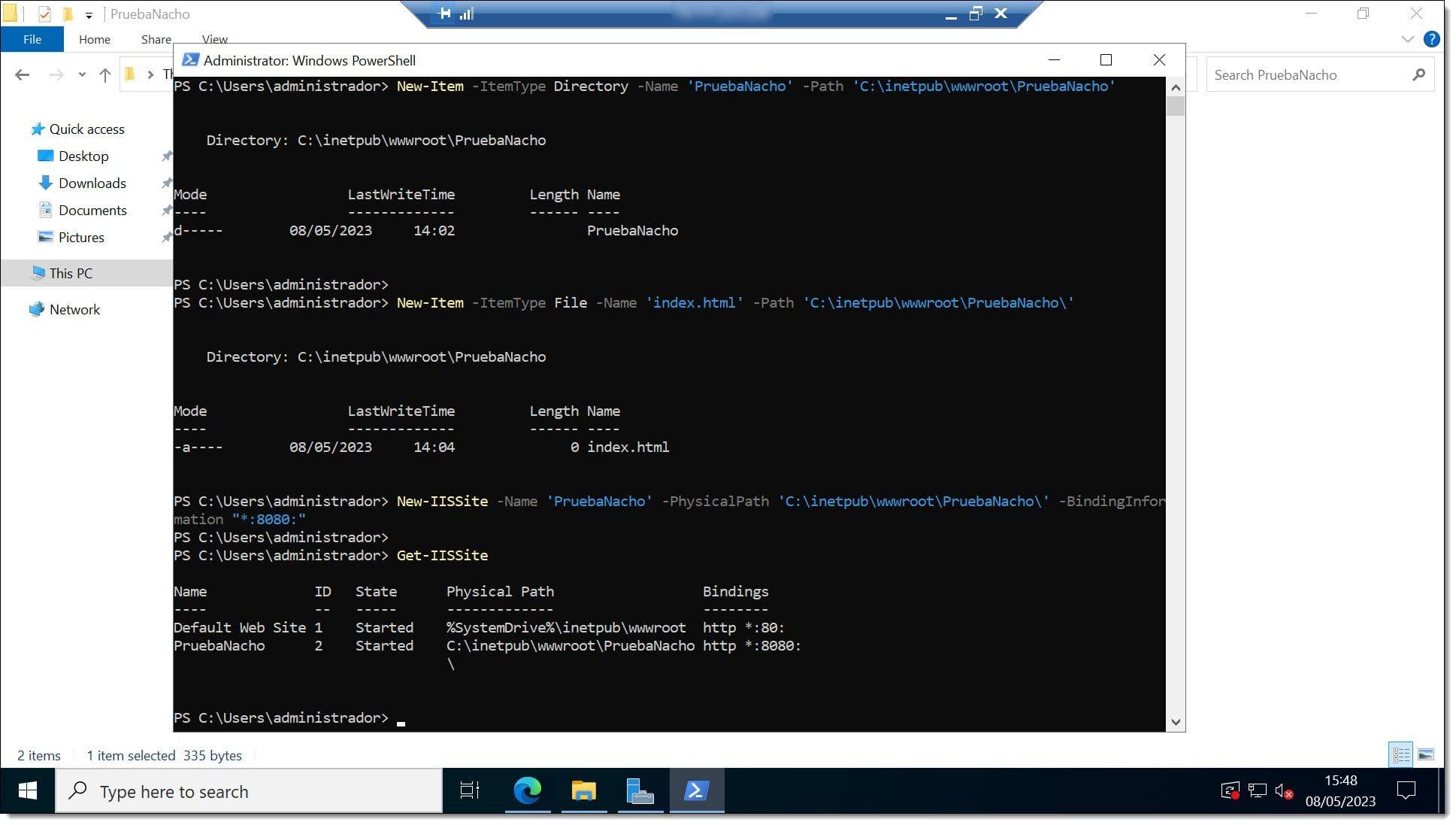
Para crear la carpeta física de un nuevo sitio se utiliza New-Item -ItemType Directory, indicando nombre y ruta. Conviene organizar los contenidos web bajo rutas como «C:\inetpub\wwwroot\NombreSitio» para mantener un esquema ordenado.
El propio fichero inicial del sitio (por ejemplo, un index.html sencillo) también puede crearse con New-Item -ItemType File, y después editarse a mano o mediante otros cmdlets si quieres automatizar la generación.
El siguiente paso es asociar ese directorio a un nuevo sitio de IIS con New-IISSite, pasando el nombre del sitio, la ruta física y la información de binding. Por ejemplo, un binding «*:8080:» indica que el sitio escuchará en el puerto 8080 en todas las IP disponibles de la máquina.
Una vez creado el sitio, puedes comprobar que responde correctamente accediendo desde el navegador a la URL correspondiente (por ejemplo, «http://servidor:8080/») y verificando que se muestra el contenido de tu index.html.
Arranque, parada y eliminación de sitios con PowerShell
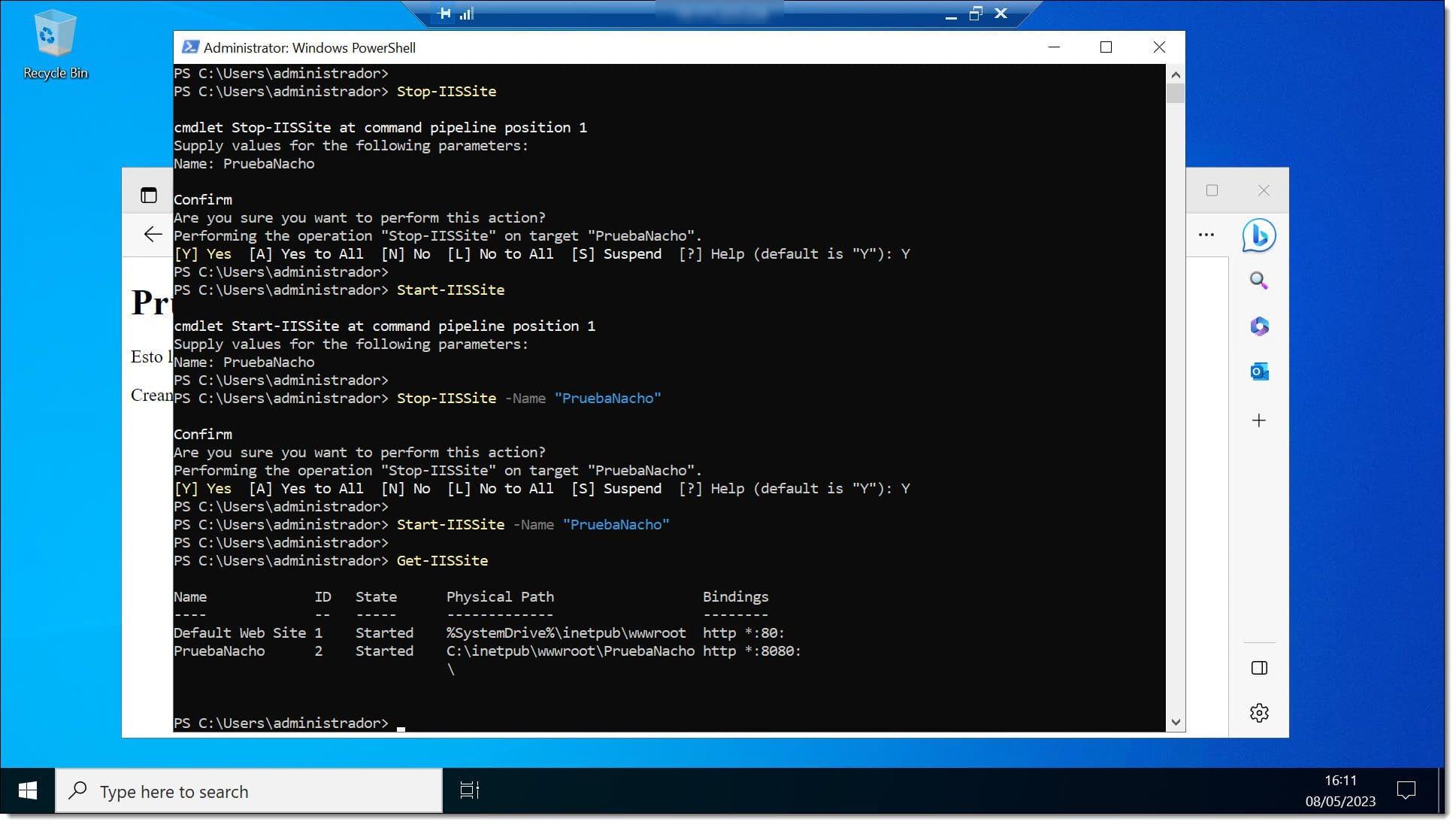
El ciclo de vida de un sitio web bajo IIS se controla fácilmente desde PowerShell con cmdlets como Start-IISSite, Stop-IISSite y Remove-IISSite, además de Get-IISSite para consultar su estado actual.
Por ejemplo, Stop-IISSite puede usarse de forma interactiva pidiendo el nombre del sitio, o pasarlo directamente con el parámetro -Name para automatizar la detención sin más preguntas, ideal en scripts de despliegue o mantenimiento.
Start-IISSite funciona del mismo modo, y con Get-IISSite puedes listar todos los sitios existentes o filtrar por nombre para ver rápidamente propiedades como el estado (Iniciado/Detenido) y los bindings configurados.
Si te interesa alguna propiedad concreta, como los puertos en los que escucha un sitio, puedes recuperarla desde PowerShell accediendo a la colección Bindings del objeto devuelto por Get-IISSite, lo que te da una vista muy clara de cómo está publicado cada sitio.
Cuando toca eliminar un sitio que ya no se necesita, Remove-IISSite -Name permite hacerlo directamente, y el modificador -WhatIf resulta muy útil para simular la operación y ver qué sucedería antes de ejecutar cambios destructivos reales.
Web Deploy, bases de datos y delegación
La herramienta Web Deploy incorpora varios scripts de PowerShell orientados a facilitar la publicación remota de sitios en IIS y la creación de recursos asociados como bases de datos SQL Server o MySQL, así como la configuración de reglas de delegación.
Scripts como SetupSiteForPublish.ps1 automatizan desde la creación del sitio y el pool de aplicaciones hasta la asignación de permisos a un usuario de despliegue específico, garantizando un modelo en el que ese usuario puede publicar sin ser administrador de la máquina.
Para bases de datos SQL Server existe el script CreateSqlDatabase.ps1, que crea la base de datos, un login y un usuario con permisos db_owner sobre esa base, y añade la cadena de conexión resultante al fichero PublishSettings asociado, listo para que el desarrollador lo consuma desde sus herramientas.
De forma análoga, CreateMySqlDatabase.ps1 cubre el caso de MySQL, generando la base de datos y un usuario con privilegios sobre la misma, y actualizando igualmente los perfiles de publicación. Aquí es importante revisar los permisos (por ejemplo, si quieres permitir acceso más allá de localhost) ajustando el comando GRANT correspondiente en el propio script.
Por último, AddDelegationRules.ps1 se encarga de aplicar o reparar las reglas de delegación necesarias en IIS para que Web Deploy funcione correctamente, creando cuentas de servicio específicas y dándoles los permisos justos sobre la configuración (applicationHost.config) y sobre ciertas operaciones de administración.
Servidores locales “todo en uno” y migración a hosting
Más allá de PowerShell e IIS, en el ecosistema web es muy habitual montar servidores locales tipo WAMP, MAMP, LAMP o XAMPP. Estos paquetes combinan Apache, PHP y MySQL en un único instalador para facilitar pruebas de CMS como WordPress en entorno local.
La lógica es similar: el servidor local expone el sitio bajo http://127.0.0.1 o http://localhost, y la carpeta donde colocas los proyectos (por ejemplo «C:\wamp\www\») actúa como raíz de documentos. Cada subcarpeta suele ser un proyecto web distinto, accesible vía URLs tipo «http://localhost/miweb».
Cuando quieres mover un proyecto desarrollado en local a un hosting real, el proceso típico consiste en exportar la base de datos (normalmente desde phpMyAdmin), comprimir los archivos web, subirlos al servidor remoto con un gestor de archivos o FTP e importar la base de datos desde el panel de control del hosting.
Después hay que ajustar algunos detalles, como las URLs de la web dentro de la base de datos (cambiando localhost por el dominio real) y los datos de conexión en los ficheros de configuración del CMS (por ejemplo, wp-config.php en WordPress, donde se indican nombre de la base de datos, usuario y contraseña del entorno de producción).
En todos estos escenarios, el patrón se repite: disponer de un servidor HTTP local bien configurado, ya sea con un bundle tipo WAMP o con un servidor ligero hecho en PowerShell, acelera muchísimo el desarrollo y las pruebas antes de publicar nada hacia fuera.
Al final, combinar un servidor HTTP mínimamente sofisticado en PowerShell —con rutas, hooks, parseo de peticiones y servicio de ficheros estáticos— con las capacidades de IIS y Web Deploy para producción te da un entorno muy completo: ligero para el día a día del desarrollo local y robusto para los despliegues definitivos, todo ello aprovechando las herramientas nativas del ecosistema Windows sin depender obligatoriamente de stacks externos.
Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.