- Pogocache ofrece caché de baja latencia y habla protocolos Memcache, Redis, HTTP y PostgreSQL.
- HTTP caching se controla con cabeceras como Cache-Control, ETag y Vary para equilibrar frescura y velocidad.
- Capas de caché en cliente, proxy/edge, aplicación y base de datos reducen carga y latencia.
- Estrategia basada en TTL alineados al cambio del dato e invalidación selectiva maximiza aciertos.

Si alguna vez te has preguntado por qué ciertas aplicaciones responden a toda velocidad, la respuesta suele ser la misma: una buena estrategia de caché. Y ahora, con la aparición de soluciones modernas como Pogocache, ese acelerón es todavía más notable. La combinación de conceptos clásicos de caching con nuevas implementaciones eficientes marca la diferencia entre una app normalita y otra que vuela.
Más allá del típico almacenamiento temporal, la caché es toda una capa de arquitectura que afecta a navegadores, proxies, APIs, bases de datos y al edge de la red. Entender cada nivel, sus cabeceras y sus patrones de uso te permite rebajar carga de servidores, acortar latencias y ahorrar costes, sin renunciar a datos confiables.
Qué es Pogocache y por qué está dando que hablar
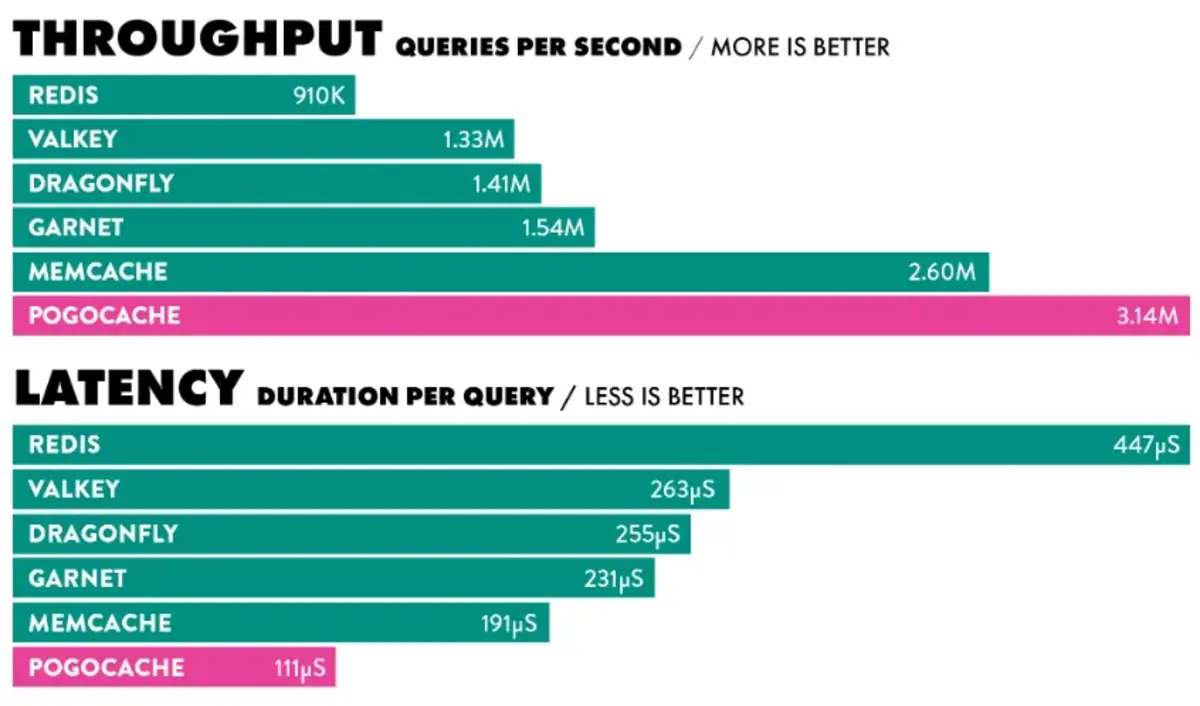
Pogocache es un software de caché construido desde cero con un objetivo claro: minimizar la latencia y el uso de CPU. Su propuesta es ser más veloz que soluciones populares como Memcached, Valkey, Redis, Garnet o Dragonfly, y hacerlo con una arquitectura moderna y ligera.
Uno de sus puntos fuertes es la compatibilidad de protocolos: entiende los wire protocols de Memcache, Redis, HTTP y PostgreSQL, lo que abre la puerta a integraciones sencillas con stacks existentes. Eso significa que puede actuar como sustituto en escenarios donde ya hablas con Redis o Memcache, o ser consultado desde clientes que se comunican vía HTTP o con el protocolo de Postgres.
En despliegue, es flexible: puede ejecutarse como servicio gestionado, instalarse en local o integrarse como biblioteca embebida dentro de tu aplicación. Esa versatilidad facilita usarlo como caché compartida, caché de proceso o incluso en topologías híbridas donde conviven edge y backend. Además, es software libre con licencia AGPL.
En la práctica, Pogocache encaja en casos como cacheado de respuestas de API, resultados de consultas frecuentes, sesiones temporales o estructuras de datos que se consultan en caliente. Al ser eficiente en CPU y latencia, brilla especialmente en cargas con gran volumen de lecturas y claves de alta rotación.
La idea de caché: una metáfora sencilla que lo explica todo
Imagina que compras online y vas a recoger el pedido. Si cada producto hay que buscarlo en el almacén, tardas; si el pedido está ya en una bolsa con tu nombre, sales en segundos. Eso mismo hace la caché: prepara respuestas por adelantado para entregarlas sin esperas.
Servicios a escala planetaria, como los buscadores, aprovechan esta lógica: muchas de las respuestas que ves ya se calcularon antes y se guardaron preparadas. Cuando haces la petición, solo hay que devolver el resultado almacenado, no repetir el cálculo cada vez.
Esta idea también aplica a aplicaciones del día a día. Apps de mensajería guardan archivos descargados para no repetir la transferencia; herramientas creativas mantienen copias de trabajo para hacerlo todo más fluido. Eso sí, cuando la caché crece demasiado o se estropea, hay que purgarla para recuperar el rendimiento.
La caché no es eterna: tiene una caducidad configurada. Definir tiempos de vida, invalidaciones y regeneraciones es clave para equilibrar frescura y velocidad, evitando servir datos caducados cuando no toca.
Capas y ubicaciones de caché en un sistema moderno
La caché no vive en un único sitio. Se reparte por capas que se complementan entre sí, desde el dispositivo del usuario hasta la base de datos o el edge de la red.
- Cliente (navegador o app): guarda recursos estáticos como imágenes, CSS o JS para agilizar visitas posteriores.
- DNS: los resolvers almacenan la conversión de nombres de dominio a IP para responder más rápido.
- Web y CDN (edge): réplicas cercanas a los usuarios reducen la latencia y descargan el origen.
- Aplicaciones: cachean respuestas de API, vistas y cálculos intensivos.
- Bases de datos: capas internas y externas minimizan lecturas repetitivas y latencia de almacenamiento.
En el edge, las CDNs actuales añaden estrategias como el caching por niveles, con capas intermedias entre el punto más cercano al usuario y el origen. Esto reduce el número de viajes al servidor y mejora la disponibilidad incluso si el origen falla.
HTTP caching: la base del rendimiento en la web
El protocolo HTTP integra mecanismos de caché para reutilizar respuestas previas cuando es seguro hacerlo. El proceso típico consiste en buscar primero en caché, servir si hay acierto y, si no, ir al origen y almacenar la copia para la siguiente vez.
Existen varias ubicaciones de HTTP caching: navegador (privada), proxy compartido intermedio y gateway o proxy inverso delante de la aplicación. Cada una obedece directivas que se envían mediante cabeceras, cruciales para controlar caducidad, validación y compartición.
Las directivas más habituales del encabezado ‘Cache-Control’ incluyen:
- public / private: indica si la respuesta puede guardarse en cachés compartidas o solo en el cliente.
- max-age: segundos de frescura permitida en cualquier caché; s-maxage hace lo propio solo para cachés compartidas.
- no-cache: obliga a revalidar antes de usar la copia; no-store impide almacenar la respuesta.
- must-revalidate / proxy-revalidate: exige respetar el vencimiento y revalidar al expirar.
- max-stale: acepta contenido caducado hasta un límite, útil ante fallos o intermitencias.
- min-fresh: pide contenido que se mantenga fresco al menos cierto tiempo.
- only-if-cached: el cliente solo quiere una copia ya cacheada; si no la hay, 504.
- no-transform: prohíbe que la caché modifique el cuerpo (por ejemplo, recomprimir).
Otras cabeceras relacionadas son igualmente importantes. ‘Expires’ fija una fecha de caducidad absoluta. ‘ETag’ aporta una etiqueta única por versión del recurso para validación condicional. ‘Last-Modified’ señala la fecha de última modificación. ‘Vary’ instruye a la caché para mantener variantes según encabezados como ‘Accept-Encoding’ o ‘User-Agent’. Combinadas, permiten precisión: servir rápido sin perder coherencia.
Cachear APIs: cuándo merece la pena y cómo hacerlo bien
Gran parte de las aplicaciones modernas se articulan en torno a APIs HTTP. No todas las peticiones requieren calcular lógica de negocio o acudir a base de datos cada vez; si la naturaleza del dato lo permite, es preferible devolver una copia en caché.
La clave está en alinear los TTL con el ritmo de cambio de los datos. Si la lista de categorías se actualiza una vez al día, cachear esa respuesta 24 horas es razonable. Así reduces la presión sobre servidores de aplicaciones y bases de datos, mejoras la latencia y recortas costes.
En entornos gestionados, hay servicios que facilitan este patrón. Plataformas de gateway de API permiten publicar, monitorizar, asegurar y cachear endpoints a cualquier escala. Activar caché a la entrada de la plataforma descarga al backend y simplifica la operación.
Para endpoints muy dinámicos, las técnicas de revalidación (ETag/If-None-Match, Last-Modified/If-Modified-Since) ayudan a evitar recalcular respuestas cuando no ha cambiado nada. Se devuelven 304 y el cliente reutiliza su copia, ahorrando transferencia y tiempo.
Caché en bases de datos: local, externa y en la nube
El almacenamiento en caché de resultados de consultas y datos de acceso frecuente es una de las vías más efectivas para mejorar el rendimiento. Consiste en mantener en memoria de alta velocidad aquello que se pide a menudo, reduciendo accesos al almacenamiento principal.
Muchas bases de datos incorporan cachés internas (por ejemplo, de páginas de disco o de resultados) y además es habitual usar soluciones externas especializadas como Redis o Memcached. Estas capas externas sirven clave-valor en memoria con latencias de micro/milisegundos, ideales para lecturas calientes.
Los proveedores cloud suelen ofrecer motores gestionados con opciones de caché y ajustes finos, desde relacionales a NoSQL. Esto facilita desplegar estrategias de caché sin montar toda la infraestructura por tu cuenta, manteniendo métricas y escalado automático.
El patrón operativo es simple: si una consulta es un acierto, se devuelve inmediatamente; si es un fallo, se consulta a la base y se almacena la respuesta con su TTL. Se apoya en la localidad temporal: lo que se pidió hace poco es probable que vuelva a pedirse.
Casos típicos incluyen fichas de producto, listados con filtros habituales o resultados de búsquedas populares en comercio electrónico. Especialmente cuando el dato cambia poco entre consultas, la mejora de latencia es notable.
Dónde implementar la caché en tu arquitectura
Hay tres lugares muy prácticos para empezar si construyes servicios web.
Navegador
Controla cómo cachea el cliente mediante ‘Cache-Control’ (por ejemplo, ‘max-age’ para definir vida útil). La validación condicional con ‘ETag’ y ‘Last-Modified’ evita descargar lo que no ha cambiado. Bien configurado, el front gana mucha agilidad entre visitas.
Reverse proxy o gateway
Colocar una capa intermedia delante del backend (proxy inverso) permite cachear respuestas públicas y reducir el número de solicitudes que llegan a tu aplicación. Puedes combinarlo con CDNs y estrategias por niveles para ganar escala global con latencias mínimas.
Aplicación
Integrar caché en las capas de tu servicio (controlador, casos de uso, repositorios) te da control fino sobre qué guardar y cuándo invalidar. Soluciones en memoria como Redis o el propio Pogocache encajan perfectamente aquí, con TTL dinámicos y etiquetado por claves.
Ventajas claras… y límites que conviene conocer
Los motivos para cachear son contundentes: tiempos de respuesta menores, menos carga en la base de datos y mejor experiencia de usuario. Además, se recortan viajes de red, ancho de banda y factura de infraestructura en escenarios de alto tráfico.
Pero no todo vale: si necesitas datos estrictamente en tiempo real o hay alta sensibilidad a la frescura, hay riesgo de servir copias obsoletas. También aumenta la complejidad operativa: invalidaciones, coherencia y seguridad hay que pensarlas bien.
Otro punto es la depuración: con cachés interpuestas, reproducir errores puede ser más difícil. Y ojo con datos sensibles: según dónde y cómo caches, debes cumplir políticas y cifrar para evitar filtraciones involuntarias.
HTTP headers en detalle: cómo hablar con las cachés
Diseñar bien las cabeceras hace que todas las capas se comporten como esperas. Un recurso estático puede ir con ‘public, max-age=31536000, immutable’ para estirar su vida en clientes y proxies. Una respuesta privada con datos de usuario debería marcarse ‘private, no-store’.
Para contenido que cambia a menudo pero no en cada petición, combina ‘max-age’ moderado con validación (‘ETag’ o ‘Last-Modified’). Así, mientras esté fresco se sirve desde caché y, al expirar, se revalida muy rápido con 304 si no hay cambios.
Cuando hay variantes por idioma, compresión o dispositivo, usa ‘Vary’ adecuadamente. Evitas servir la versión equivocada guardando una copia por combinación relevante de encabezados. Bien aplicado, mantiene la caché efectiva sin mezclar respuestas.
Edge caching: llevar la velocidad cerca del usuario
El edge caching almacena respuestas en nodos distribuidos globalmente para minimizar la distancia a los usuarios. Reduce latencias, acelera entregas y absorbe picos sin estresar tu origen, tanto para archivos estáticos como para streaming en vivo o bajo demanda.
Con una arquitectura de proxy inverso y caching por niveles, el contenido viajará menos veces al origen. Incluso si el servidor original sufre una caída temporal, muchas peticiones seguirán sirviéndose desde las capas intermedias o de borde.
Buenas prácticas al usar Pogocache junto al resto del ecosistema
Planifica los TTL según el patrón de cambios de tus datos, no por intuición. Usa claves con nombres consistentes y, cuando sea posible, invalidación selectiva (por etiquetas o prefijos) para no vaciar toda la caché ante cambios puntuales.
Aprovecha la compatibilidad de protocolos: si tu aplicación ya habla Redis o Memcache, evalúa el encaje como sustituto drop-in; si prefieres HTTP, expón endpoints cacheables con cabeceras correctas; si te conviene integrarlo a bajo nivel, usa la opción embebida. Esa flexibilidad permite probar sin rehacer toda tu arquitectura.
Mide aciertos y fallos de caché, colisiones de claves y consumos de CPU y memoria. La observabilidad es esencial para ajustar TTL, tamaños y políticas de expulsión (LRU, LFU, FIFO, etc.) a tu patrón de tráfico real.
Ten presente la licencia AGPL: es software libre, pero con obligaciones específicas si distribuyes o prestas servicio. Consulta a tu equipo legal para confirmar cómo afecta a tu modelo de despliegue en SaaS o productos redistribuidos.
Para datos muy dinámicos, combina cacheado corto con revalidación y prewarming de claves calientes. El precalentamiento reduce los picos de latencia conocidos tras despliegues o caducidades masivas, y evita avalanchas al origen.
El rendimiento real nace de la suma: una caché de aplicación eficaz (por ejemplo, con Pogocache), cabeceras HTTP bien pensadas, una CDN/edge que absorba el grueso del tráfico y, en la base, una política de caché de datos que quite presión a tu almacenamiento. Con esas piezas alineadas ganarás velocidad, resiliencia y coste por petición sin sacrificar frescura cuando importa.
Redactor apasionado del mundo de los bytes y la tecnología en general. Me encanta compartir mis conocimientos a través de la escritura, y eso es lo que haré en este blog, mostrarte todo lo más interesante sobre gadgets, software, hardware, tendencias tecnológicas, y más. Mi objetivo es ayudarte a navegar por el mundo digital de forma sencilla y entretenida.