- Les microservices permettent le développement d'applications modulaires et évolutives, où chaque service est autonome et déployable indépendamment.
- Docker facilite la création de conteneurs légers et portables qui regroupent chaque microservice avec toutes ses dépendances.
- Kubernetes orchestre les conteneurs, gérant le déploiement, la mise à l'échelle, la mise en réseau et la récupération automatique des microservices au sein du cluster.
- L'application de bonnes pratiques en matière de sécurité, de surveillance et d'automatisation est essentielle au bon fonctionnement des microservices en production.
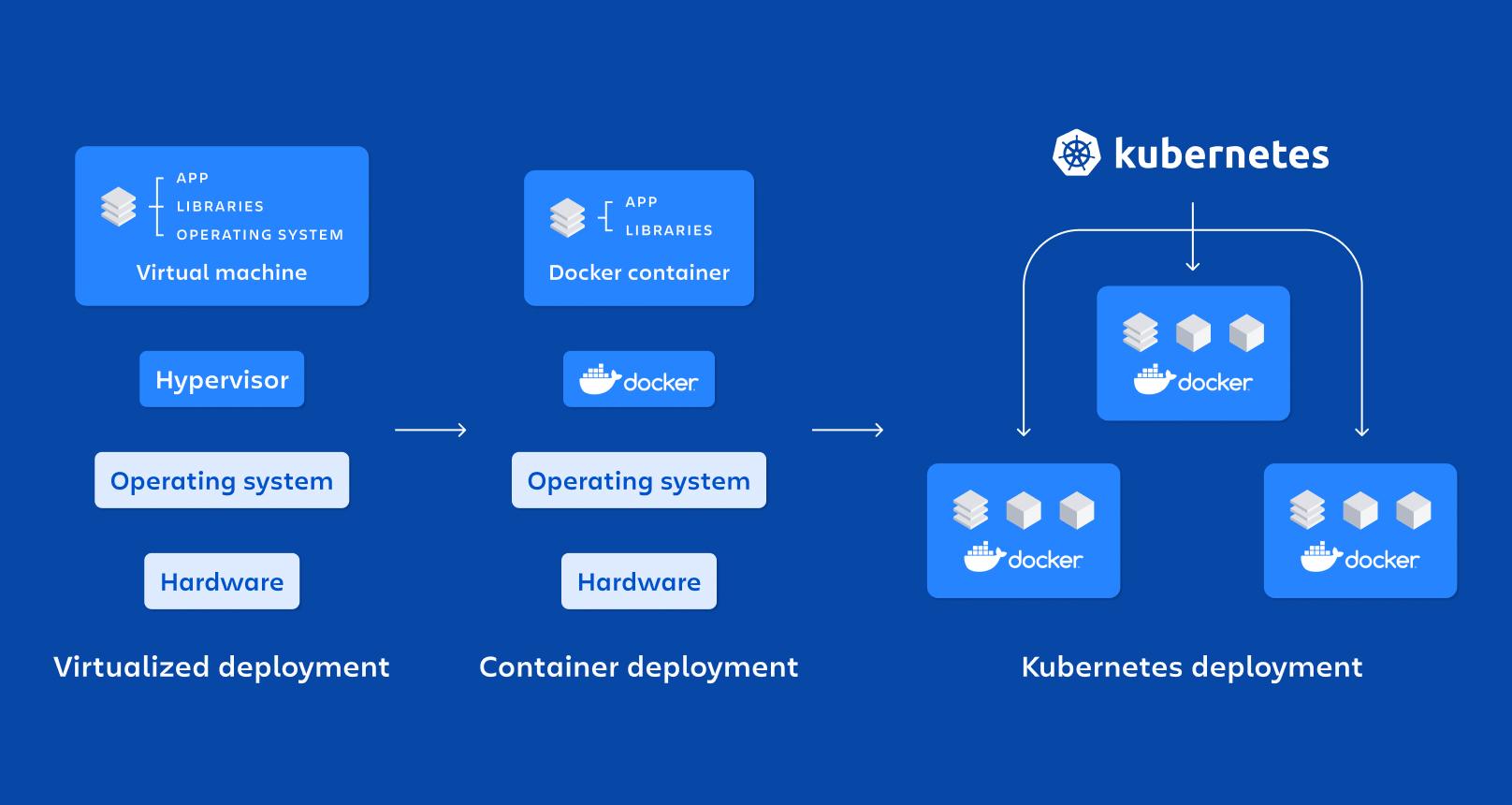
Au cours des dernières années, la combinaison de microservices, de Docker et de Kubernetes Elle est devenue la norme de facto pour le déploiement d'applications modernes, évolutives et faciles à maintenir. De plus en plus d'entreprises abandonnent les applications monolithiques au profit d'architectures distribuées, mieux adaptées aux environnements changeants et aux stratégies DevOps.
Si vous demandez Comment implémenter des microservices avec Docker et Kubernetes en pratiqueCe contenu est fait pour vous : nous passerons en revue les concepts clés, les avantages et les défis, comment créer des conteneurs, comment les orchestrer dans un cluster et quelles étapes suivre pour les installer. Windows y Linuxainsi qu'une série de conseils pour les utiliser judicieusement dans des situations réelles.
Qu'est-ce qu'une architecture de microservices et en quoi diffère-t-elle d'une architecture monolithique ?
Une architecture de microservices est basée sur diviser une application en plusieurs petits services autonomes et déployables indépendammentchacune était axée sur une fonctionnalité spécifique (utilisateurs, paiements, catalogue, commandes, etc.), qui communiquaient principalement via des API légères (HTTP/REST, gRPC, messagerie, etc.).
Dans une application monolithique, en revanche, Toute la logique métier, la couche de présentation et l'accès aux données sont regroupés dans un seul bloc de déploiement.Toute modification nécessite la recompilation, le test et le déploiement de l'ensemble du système, ce qui complique l'évolution et augmente le risque d'introduire des erreurs en production.
Avec les microservices, chaque service a son propre cycle de vie : Il peut être développé, testé, déployé, mis à l'échelle et versionné indépendamment.Cela permet à plusieurs équipes de travailler en parallèle, simplifie l'adoption de nouvelles technologies et facilite l'intégration avec les pratiques CI/CD.
De plus, cette architecture introduit le concept de évolutivité indépendante des composantsAu lieu de dimensionner une application monolithique entière pour supporter une charge plus importante sur un module spécifique, seuls les microservices qui en ont réellement besoin sont dimensionnés, ce qui permet une meilleure optimisation des ressources d'infrastructure.
Avantages et défis réels des microservices
Le passage aux microservices n'est pas qu'une mode passagère : Elle offre des avantages concrets en termes d'évolutivité, de résilience et de rapidité de déploiement.Mais cela introduit également une complexité opérationnelle qu'il faut gérer.
Parmi les avantages les plus notables, on trouve évolutivité indépendante de chaque serviceSi, par exemple, le module de paiement reçoit plus de trafic que le module d'administration, vous pouvez augmenter uniquement le nombre de répliques du microservice de paiement, sans toucher au reste de l'application ni gaspiller de ressources.
Vous y gagnez également beaucoup. déploiement continu et livraisons fréquentesEn isolant chaque service, il est possible de publier de nouvelles versions progressivement, sans avoir à arrêter ou à redéployer l'intégralité de l'application, ce qui réduit les fenêtres de maintenance et améliore le délai de mise sur le marché.
Un autre point clé est le résilience et tolérance aux pannesCorrectement conçue, une défaillance d'un microservice ne devrait pas entraîner l'arrêt complet du système. Grâce à des mécanismes tels que les délais d'attente, les tentatives de reconnexion et les disjoncteurs, les autres services peuvent continuer à répondre, limitant ainsi l'impact des défaillances.
De plus, les microservices permettent flexibilité technologiqueChaque équipe peut choisir le langage, le framework ou la base de données les plus appropriés à son service, à condition de respecter les contrats de communication et les politiques globales de la plateforme.
De l'autre côté de la médaille, nous trouvons le complexité opérationnelle et d'observabilitéLa gestion de dizaines, voire de centaines de services, implique de traiter des réseaux distribués, des traces inter-services, une journalisation centralisée, la sécurité, le versionnage des API et la cohérence des données, ce qui nécessite des outils avancés et des processus éprouvés.
Cela se complique aussi. gestion de la communication entre les servicesIl est essentiel de concevoir avec soin la manière dont les données sont échangées, dont les erreurs sont gérées, dont la latence est maîtrisée et comment empêcher qu'une dépendance lente ne pénalise le reste du système. Les tests et le débogage ne sont plus triviaux, car Ce n'est pas un bloc isolé qui est testé, mais un ensemble de services interconnectés..
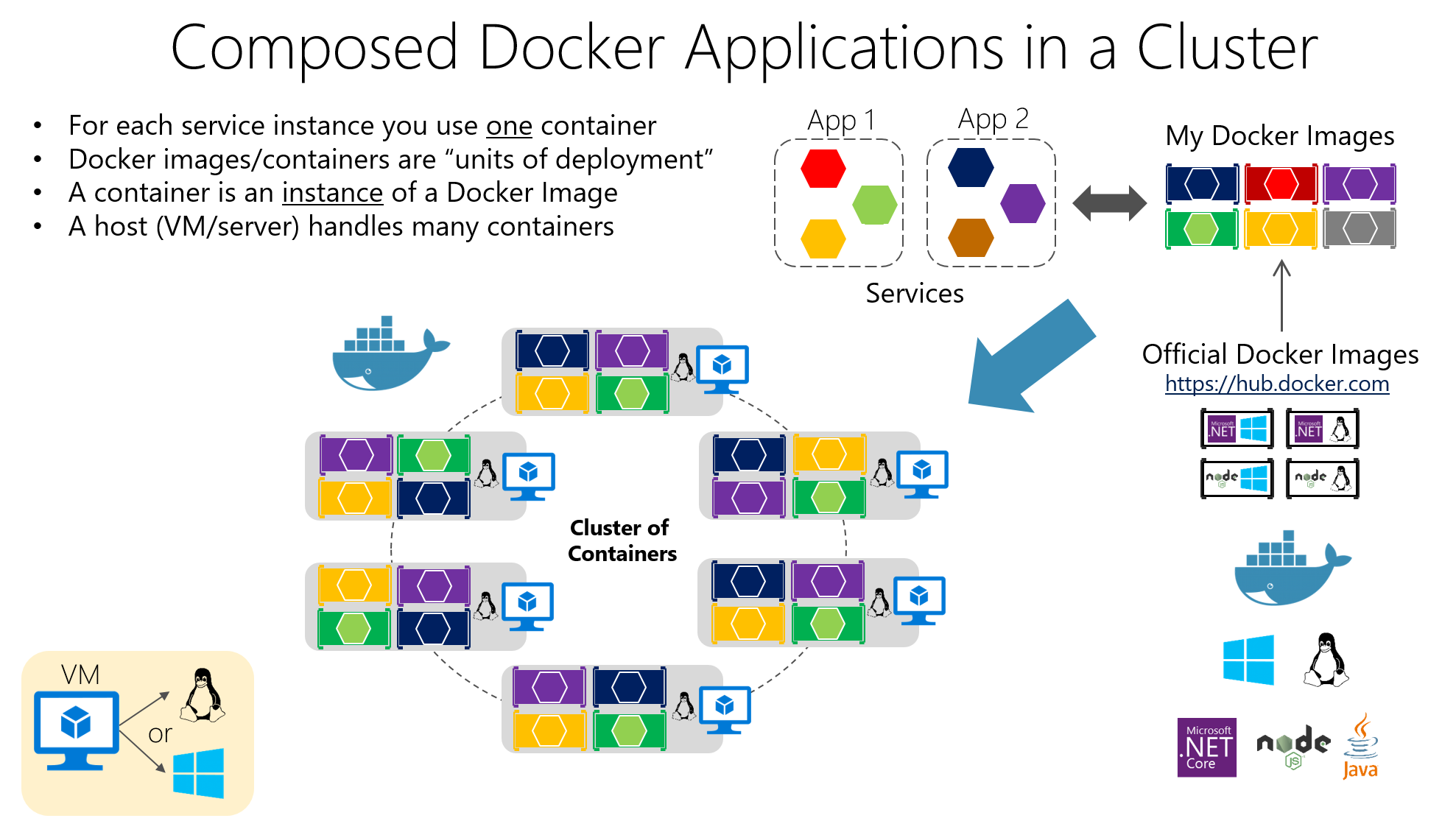
Les conteneurs : la base de l'exécution de microservices isolés
La technologie des conteneurs est devenue le support idéal pour les microservices car Il vous permet de regrouper une application et toutes ses dépendances dans une unité standardisée et portable.Au lieu d'installer des bibliothèques, des environnements d'exécution et des outils sur chaque serveur, tout se déplace à l'intérieur du conteneur.
Un conteneur est, essentiellement, une forme légère de virtualisation au niveau du système d'exploitation: partage le noyau hôte mais exécute les processus dans des espaces de noms isolés et avec des ressources limitées par des cgroups, ce qui leur permet de démarrer rapidement et de consommer moins qu'une machine virtuelle.
Parmi ses principales caractéristiques figurent les isolation, portabilité, légèreté et modularitéChaque microservice exécuté dans son propre conteneur devient plus facile à déployer, à arrêter, à mettre à jour ou à répliquer, ce qui correspond parfaitement aux principes des architectures distribuées.
Comparé au machines virtuelles pour la productionles conteneurs Ils n'ont pas besoin d'un système d'exploitation complet par instance.mais plutôt partager celui de l'hôte. Cela réduit considérablement la taille des images et le temps de Bottevous permettant de soulever ou de détruire des conteneurs en quelques secondes.
Docker : la plateforme de référence pour la conteneurisation des microservices
Docker est l'outil le plus populaire pour travailler avec des conteneurs, car Il facilite la création, le conditionnement, la distribution et l'exécution d'applications conteneurisées aussi bien dans les environnements de développement que dans les environnements de test et de production.
Leur idée centrale est d'intégrer le logiciel dans un emballage Images DockerCe sont des artefacts immuables qui comprennent le code de l'application, les bibliothèques nécessaires, les outils système et les configurations de base. Les applications sont créées à partir de ces images. conteneurs en service, qui sont des cas isolés basés sur cette image.
La construction d'images est définie dans un Dockerfile, un fichier texte qui spécifie des instructions telles que l'image de base, le répertoire de travail, les fichiers à copier, les dépendances à installer, les ports à exposer et la commande à exécuter lors du démarrage du conteneur.
Imaginez que vous ayez une API écrite en Node.js. Vous pourriez créer un Dockerfile similaire à celui-ci, où À partir d'une image Node officielle, les fichiers sont copiés, les dépendances sont installées et la commande de démarrage est définie.:
FROM node:14
WORKDIR /app
COPY . .
RUN npm install
EXPOSE 3000
CMD
Ce fichier indique que l'application s'exécutera dans le répertoire /app à l'intérieur du conteneur, que les dépendances seront installées avec npm, que le port 3000 sera exposé et que, lors du démarrage du conteneur, celui-ci exécutera npm début.
Pour créer et lancer ce conteneur, il suffit d'exécuter la commande depuis le dossier du projet. construction de menu fixe et alors docker courirmapper les ports pour permettre l'accès depuis l'hôte, ou pour les applications multi-conteneurs utiliser docker-compose:
docker build -t mi-app .
docker run -p 3000:3000 mi-app
Grâce à ce modèle, Le problème classique du « ça marche sur ma machine » est réduit au minimum.L'environnement d'exécution étant lié à l'application, Docker s'intègre parfaitement aux systèmes CI/CD, aux registres privés et aux outils d'orchestration comme Kubernetes.
Composants clés de Docker et leur rôle dans les microservices
Dans un déploiement typique, on parle d'un Hôte DockerIl s'agit du système (physique ou virtuel) sur lequel Docker est installé ; il s'exécute par-dessus. Docker Engine, le démon qui gère les images, les réseaux, les volumes et le cycle de vie des conteneurs.
Les conteneurs contiennent les application et ses dépendances empaquetées dans une imageCela permet à tout serveur utilisant Docker d'exécuter cette image de manière cohérente. Cette cohérence est cruciale lorsque de nombreux microservices sont déployés dans différents environnements (développement, assurance qualité, production, etc.).
Parmi les avantages les plus intéressants de Docker, on peut citer : portabilité entre environnements, automatisation du déploiement, modularité des processus et prise en charge de la mise en couches et du contrôle de version des imagesce qui facilite l'annulation des modifications et l'optimisation du stockage.
Kubernetes : l’orchestrateur pour la gestion de centaines de conteneurs
Lorsque vous passez de quelques conteneurs à des dizaines ou des centaines, Les gérer manuellement devient de la folie.C'est là qu'intervient Kubernetes, une plateforme open source conçue pour orchestrer des conteneurs à grande échelle.
Kubernetes automatise des tâches critiques telles que déploiement, mise à l'échelle, récupération après panne, configuration réseau et stockage pour les applications conteneurisées. Il est conçu pour fonctionner dans les clouds publics, les clouds privés, les environnements hybrides et même sur site.
Il se concentre sur la gestion de clusters composés de plusieurs nœuds (machines) sur lesquels s'exécutent des conteneurs. L'objectif est de garantir que les applications sont toujours dans l'état souhaité: nombre de répliques, versions déployées, ressources allouées et connectivité entre les services.
Éléments fondamentaux de Kubernetes
La plus petite unité dans Kubernetes est le CosseUn pod représente une ou plusieurs instances de conteneur qui doivent s'exécuter ensemble (par exemple, un conteneur d'application et un conteneur sidecar pour la journalisation). Les pods sont éphémères. Ils sont créés, détruits et remplacés en fonction des besoins du groupe..
Pour exposer vos Pods, Kubernetes propose la ressource Servicesqui fait office de couche d'abstraction réseau. Un service regroupe un ensemble de pods et Il fournit une adresse IP stable, un nom DNS et un équilibrage de charge interne.afin que les clients n'aient pas besoin de connaître les détails de chaque Pod.
La ressource Déploiement Il sert à définir comment les pods doivent être déployés et mis à jour : le nombre de réplicas, l’image à utiliser, les étiquettes à appliquer et la stratégie de mise à jour à suivre. Kubernetes gère cela. Maintenez toujours le nombre souhaité de pods en cours d'exécution. et d'effectuer des mises à jour progressives ou des restaurations lorsque vous modifiez la configuration.
Il existe également des ressources telles que ConfigMap et SecretCes fonctionnalités permettent d'externaliser la configuration et de stocker les données sensibles (mots de passe, jetons, clés API) sans avoir à les intégrer aux images. Cela simplifie considérablement la gestion sécurisée de la configuration dans différents environnements.
Comment organiser un cluster Kubernetes
La « tête » du groupe est le Plan de contrôle Kubernetesqui regroupe plusieurs composants chargés d'orchestrer l'ensemble du système. Parmi eux se trouve le Serveur APIqui constitue la passerelle pour la gestion du cluster ; toute action (créer un déploiement, lister les pods, modifier un service) passe par cette API.
El Planificateur Il est chargé de décider sur quel nœud chaque Pod s'exécute, en tenant compte des ressources disponibles, des affinités et des contraintes ; tandis que Gestionnaire de contrôleur Surveillez l'état du cluster et prenez les mesures nécessaires pour que la réalité corresponde à ce que vous avez indiqué dans les manifestes (par exemple, créez de nouveaux pods s'il y en a moins que ce que vous avez demandé).
Le stockage de l'état est délégué à etcdUne base de données distribuée stocke la configuration et les informations de toutes les ressources du cluster. De plus, des processus tels que les suivants s'exécutent sur chaque nœud de calcul : Kubelet (agent qui assure la communication entre le nœud et le serveur API), le Kube-proxy (qui gère le trafic réseau et l'équilibrage de charge) et le exécution du conteneur (Docker, containerd, CRI-O, etc.).
Déploiement de microservices dans Kubernetes avec des fichiers YAML
Pour déployer un microservice dans Kubernetes, il est courant de le décrire avec un Manifeste YAML, où vous définissez le déploiement (modèle de pod, image, ports, nombre de réplicas, étiquettes) et le service correspondant pour l'exposer à l'intérieur ou à l'extérieur du cluster.
Un exemple de déploiement de base pour une application appelée « my-app » pourrait ressembler à ceci : Trois répliques et le port 3000 sont définis. comme port de conteneur :
apiVersion: apps/v1
kind: Deployment
metadata:
name: mi-app
spec:
replicas: 3
selector:
matchLabels:
app: mi-app
template:
metadata:
labels:
app: mi-app
spec:
containers:
- name: mi-app
image: mi-app:latest
ports:
- containerPort: 3000
Ce manifeste indique que le groupe doit maintenir trois capsules en service L'image « my-app:latest » permet d'étiqueter tous les pods avec app=my-app, afin qu'un service puisse les localiser et répartir le trafic entre eux. Kubernetes gère automatiquement la logique de mise à l'échelle, les mises à jour et le remplacement des pods en cas de panne.
Outre les déploiements, il est courant de définir des services de type ClusterIP, NodePort ou équilibreur de chargeSelon que le microservice doive être accessible uniquement au sein du cluster, depuis les nœuds ou depuis Internet, toute cette configuration est versionnée dans des référentiels, s'intégrant parfaitement aux pipelines CI/CD.
Mise à l'échelle, mises à niveau et auto-réparation dans Kubernetes
L'une des principales raisons d'utiliser Kubernetes est sa capacité à Mise à l'échelle et mise à jour des microservices sans interruption de l'applicationVous pouvez modifier le nombre de réplicas dans le manifeste (ou avec une commande kubectl) et le cluster se chargera de créer ou de supprimer des Pods jusqu'à ce que la valeur souhaitée soit atteinte.
Cette mise à l'échelle peut être manuelle ou automatique, à l'aide de ressources telles que Autoscaler horizontal à pods (HPA)Cette fonctionnalité ajuste dynamiquement le nombre de réplicas en fonction de paramètres tels que l'utilisation du processeur ou de la mémoire. Ainsi, la capacité est augmentée lors des pics de demande et les ressources sont libérées lorsque la charge diminue.
En ce qui concerne les mises à jour, Kubernetes implémente mises à jour continues Par défaut : il crée des pods avec la nouvelle version et supprime progressivement ceux de la version précédente, sans coupure brutale. En cas de problème, une rollback Il vous permet de récupérer rapidement la version précédente.
Une autre fonctionnalité essentielle est la auto-réparationSi un conteneur ou un Pod tombe en panne, Kubernetes le recrée automatiquement ; si un nœud cesse de répondre, les Pods concernés sont reprogrammés sur d’autres nœuds disponibles, ce qui permet à l’application de rester opérationnelle.
Surveillance et observabilité des microservices dans Kubernetes
Pour faire fonctionner correctement un environnement de microservices, il ne suffit pas de simplement déployer et de mettre à l'échelle : Vous avez besoin d'une visibilité en temps réel sur les performances et l'état des servicesDans Kubernetes, il est très courant d'intégrer des outils comme Prometheus pour collecter les métriques et Grafana pour les visualiser.
Prometheus gère la collecte des métriques des pods, des nœuds et des composants du cluster, leur stockage et vous permet de définir des alertes les concernant ; combiné à Grafana, vous pouvez créer des tableaux de bord où Surveillez l'utilisation du processeur, la mémoire, les erreurs HTTP, la latence, le nombre de réplicas ou l'état des nœuds. très clairement.
De plus, kubectl offre commandes Pour consulter l'état des déploiements, des services, des pods et autres ressources, voir journauxCela inclut la description d'événements ou l'accès aux conteneurs à des fins de débogage. Tout cela fait partie d'une stratégie d'observabilité qui, dans les microservices, Ce n'est pas une option si vous voulez dormir paisiblement..
Relation entre les microservices, Docker et Kubernetes
Les microservices, Docker et Kubernetes s'imbriquent comme les pièces d'un même puzzle : L'architecture de microservices définit la conception de l'application, Docker gère l'empaquetage et l'exécution de chaque service, et Kubernetes orchestre tous ces conteneurs. en grappe.
Chaque microservice est encapsulé dans une image Docker qui inclut son code et ses dépendancesCela garantit un comportement identique sur l'ordinateur portable d'un développeur, dans un environnement de test ou en production dans le cloud. Cette cohérence dans le packaging est essentielle à la philosophie DevOps.
De son côté, Kubernetes agit comme orchestrateur de conteneursIl détermine le nombre d'instances de chaque microservice qui doivent être exécutées, leur emplacement, la manière dont le trafic leur est réparti, comment elles se rétablissent après une panne et comment elles évoluent lorsque la demande augmente ou diminue.
Dans une application de commerce électronique, par exemple, vous pourriez avoir des microservices pour l'authentification, le catalogue, le panier d'achat et les paiements, chacun avec sa propre image Docker et son déploiement Kubernetes. De cette façon, Vous pouvez adapter le catalogue lors de campagnes massives ou de paiements à des moments critiques sans affecter le reste.et orchestrer l'intégralité de son cycle de vie, des pipelines CI/CD à la surveillance post-production.
Installation de Docker et Kubernetes sous Windows
Si vous travaillez sous Windows, la manière la plus simple de commencer est d'installer Bureau Dockerqui inclut le moteur Docker et des outils supplémentaires, et même des options pour activer Kubernetes intégré à votre machine.
Le processus typique comprend Téléchargez Docker Desktop depuis le site officielExécutez le programme d'installation (Docker Desktop Installer.exe) et suivez l'assistant. Lors de l'installation, vous pouvez choisir entre utiliser Hyper-V ou WSL 2 en tant que technologie de virtualisation ; s'il n'y en a qu'une disponible, c'est celle-ci qui sera utilisée.
Après le redémarrage du système, l'ouverture de Docker Desktop initialise l'environnement de conteneurs ; si la virtualisation n'était pas activée, le programme d'installation propose généralement cette option. l'activer automatiquementÀ partir de là, vous pouvez lancer des conteneurs, par exemple Nginx ou vos propres applications.
Pour utiliser Kubernetes sous Windows, vous devez d'abord activer Docker et la virtualisation. Ensuite, vous pouvez activer Kubernetes depuis Docker Desktop ou Installer et configurer kubectl pour gérer les clusters externes et, le cas échéant, déployer le tableau de bord Kubernetes à l'aide d'un manifeste distant.
Une fois configuré, vous pourrez accéder au tableau de bord via un proxy local, en utilisant un jeton d'authentification généré avec kubectl et pointant, par exemple, vers le fichier de configuration. .kube/config pour gérer l'accès au cluster depuis le navigateur.
Installation de Docker et Kubernetes sous Linux
Sur les systèmes Linux, tels qu'Ubuntu, l'installation de Docker est généralement assez simple : Les paquets sont mis à jour, le moteur Docker est installé et l'environnement est vérifié pour s'assurer de son bon fonctionnement. Exécution d'un conteneur de test.
Les étapes typiques comprennent la mise à jour du système avec apt-get update et apt-get upgradeSupprimez toute version précédente de Docker Desktop, le cas échéant, puis installez docker-ce, docker-ce-cli, containerd.io et le plugin docker-compose à partir des dépôts officiels ou en spécifiant la version souhaitée.
Pour vérifier que tout est en ordre, un conteneur « hello-world » est généralement lancé. Il télécharge une image minimale et l'exécute.Si le message s'affiche correctement, Docker est opérationnel et prêt à conteneuriser vos microservices.
Quant à Kubernetes, sous Linux, il peut être installé à l'aide d'outils tels que KubeadmLe flux de travail typique consiste à ajouter la clé du dépôt Kubernetes, à configurer le fichier de liste des paquets, à installer kubeadm et à vérifier sa version.
Le cluster est ensuite initialisé sur le nœud maître avec kubeadm init (en spécifiant la plage réseau pour les Pods), la commande « join » est récupérée afin que les nœuds de travail rejoignent le cluster et l'accès local est configuré en créant le répertoire $HOME/.kubeen copiant le fichier admin.conf et en ajustant les permissions.
Avec cela, vous disposerez d'un cluster de base prêt pour déployer des microservices conteneurisésInstallez un réseau de Pods (Flannel, Calico, etc.) et commencez à travailler avec les déploiements, les services et le reste des ressources Kubernetes.
Bonnes pratiques et recommandations pour l'utilisation de Docker et Kubernetes
Pour tirer le meilleur parti de ces environnements, il est conseillé de suivre une série de bonnes pratiques avec Docker, en commençant par utiliser des images officielles ou fiables, soit depuis Docker Hub, soit depuis des dépôts privés vérifiés, afin de réduire les risques de sécurité.
Il est fortement recommandé optimiser la taille de l'image utilisation d'images de base légères, de constructions multi-étapes et suppression fichiers temporaires ou des artefacts inutiles. Les images plus petites se téléchargent plus rapidement et accélèrent les déploiements sur Kubernetes.
Un autre point clé est d'utiliser volumes pour la persistance des donnéesAu lieu de stocker les informations dans des conteneurs, la perte ou la recréation d'un conteneur n'entraîne pas la perte de données importantes.
Limiter les ressources allouées à chaque conteneur (CPU, mémoire, E/S) permet de empêcher un seul service de monopoliser l'hôte et dégrader le reste. De plus, les conteneurs doivent être surveillés à l'aide d'outils comme Docker Stats ou de solutions plus avancées afin de maintenir le contrôle en production.
Avec Kubernetes, il est essentiel de comprendre l'architecture du cluster et ses composants avant la mise en production. Cela évite bien des problèmes.
C'est aussi une bonne idée automatiser autant que possibleUtilisez des contrôleurs de réplication, des autoscalers et des tâches pour les chargements par lots ; tirez parti des mises à jour progressives et des restaurations ; et définissez des manifestes déclaratifs versionnés dans les dépôts Git.
La sécurité doit toujours être une priorité absolue : Limitez l'accès au serveur API, gérez les identifiants à l'aide de secrets, chiffrez les données en transit et au reposAppliquez régulièrement les correctifs et définissez des politiques réseau qui limitent la communication entre les services selon le principe du moindre privilège.
Enfin, il est essentiel d'avoir bons systèmes de surveillance et d'enregistrement centralisésainsi qu'avec des environnements de préproduction où les modifications peuvent être testées en profondeur avant d'être déployées sur le cluster de production, réduisant ainsi les risques et les mauvaises surprises.
Cet écosystème complet de microservices, de conteneurs Docker et d'orchestration Kubernetes vous permet de concevoir des systèmes bien plus flexibles, évolutifs et résilients que les architectures monolithiques traditionnelles. En combinant une architecture bien pensée, des outils adaptés et les meilleures pratiques DevOps, vous pouvez déployer des applications qui s'adaptent parfaitement aux variations de charge, se rétablissent rapidement après une panne et évoluent plus facilement.

Écrivain passionné par le monde des octets et de la technologie en général. J'aime partager mes connaissances à travers l'écriture, et c'est ce que je vais faire dans ce blog, vous montrer toutes les choses les plus intéressantes sur les gadgets, les logiciels, le matériel, les tendances technologiques et plus encore. Mon objectif est de vous aider à naviguer dans le monde numérique de manière simple et divertissante.