- Mikrotjenester tillater utvikling av modulære og skalerbare applikasjoner, der hver tjeneste er autonom og kan distribueres uavhengig.
- Docker gjør det enkelt å lage lette, bærbare containere som pakker hver mikrotjeneste med alle dens avhengigheter.
- Kubernetes orkestrerer containerne, administrerer distribusjon, skalering, nettverksbygging og automatisk gjenoppretting av mikrotjenester i klyngen.
- Å bruke gode sikkerhets-, overvåkings- og automatiseringspraksiser er nøkkelen til å lykkes med å drive mikrotjenester i produksjon.
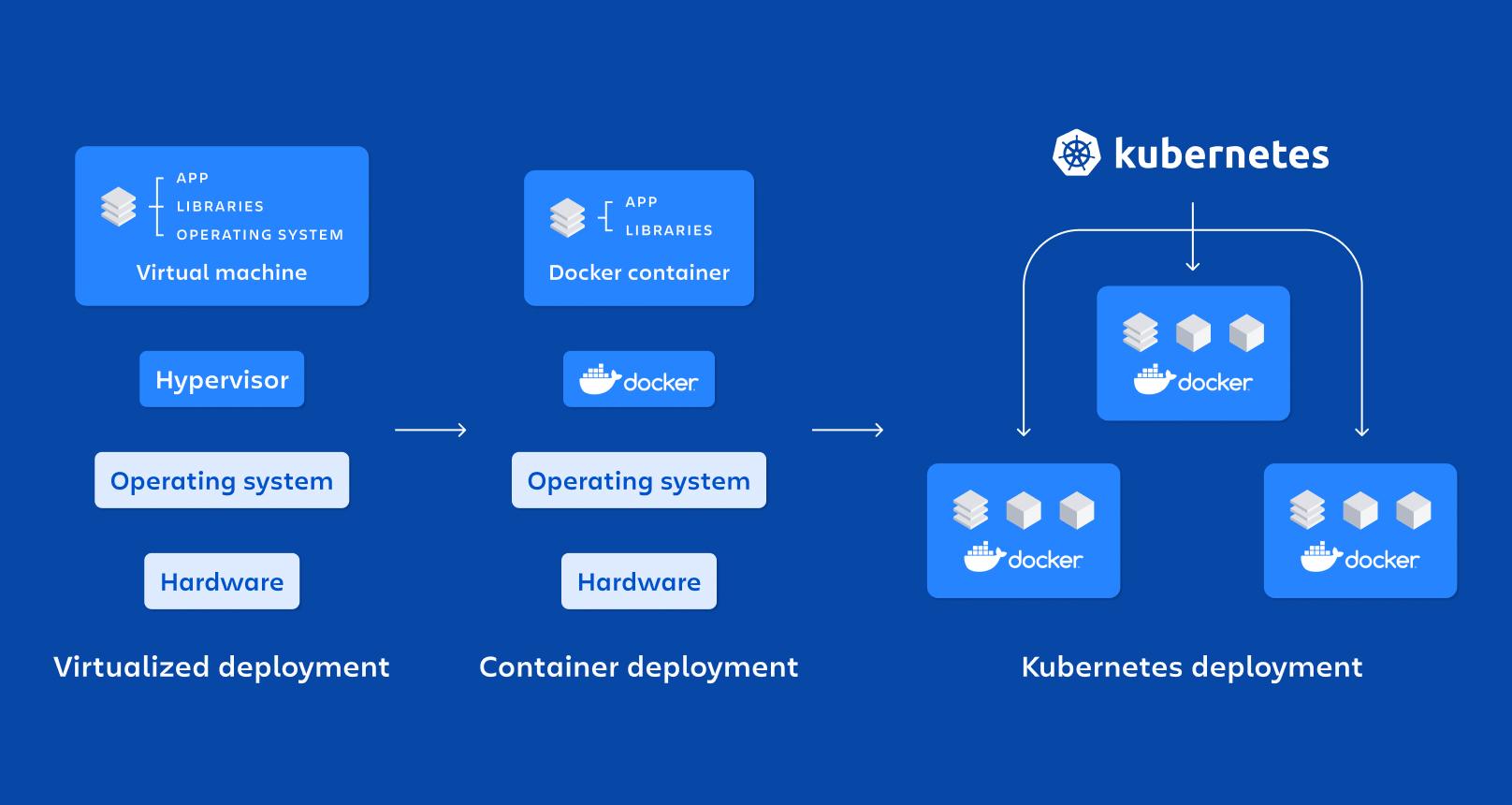
De siste årene kombinasjonen av mikrotjenester, Docker og Kubernetes Det har blitt de facto-standarden for utrulling av moderne, skalerbare og vedlikeholdsvennlige applikasjoner. Flere og flere selskaper beveger seg bort fra monolittiske applikasjoner til fordel for distribuerte arkitekturer som er bedre egnet til skiftende miljøer og DevOps-strategier.
Hvis du lurer på det Hvordan implementere mikrotjenester med Docker og Kubernetes i praksisDette innholdet vil være perfekt for deg: vi gjennomgår hovedkonseptene, fordelene og utfordringene, hvordan du oppretter containere, hvordan du orkestrerer dem i en klynge, og hvilke trinn du må følge for å installere dem. Windows y Linuxsamt en rekke tips for å bruke dem klokt i virkelige miljøer.
Hva er en mikrotjenestearkitektur, og hvordan skiller den seg fra en monolitt?
En mikrotjenestearkitektur er basert på dele en applikasjon inn i flere små, autonome og uavhengig utrullbare tjenesterhver av dem fokuserte på en spesifikk funksjonalitet (brukere, betalinger, katalog, bestillinger osv.), som kommuniserer hovedsakelig gjennom lette API-er (HTTP/REST, gRPC, meldinger osv.).
I en monolittisk applikasjon, derimot, All forretningslogikk, presentasjonslag og datatilgang er pakket i én distribusjonsblokk.Enhver endring krever rekompilering, testing og distribusjon av hele systemet, noe som kompliserer utviklingen og øker risikoen for å introdusere feil i produksjonen.
Med mikrotjenester har hver tjeneste sin egen livssyklus: Den kan utvikles, testes, distribueres, skaleres og versjoneres uavhengig.Dette gjør at flere team kan jobbe parallelt, forenkler adopsjonen av ny teknologi og legger til rette for integrering med CI/CD-praksiser.
Videre introduserer denne arkitekturen konseptet med komponentuavhengig skalerbarhetI stedet for å skalere en hel monolittisk applikasjon for å støtte mer belastning på en bestemt modul, skaleres bare mikrotjenestene som virkelig trenger det, noe som optimaliserer infrastrukturressursene bedre.
Reelle fordeler og utfordringer med mikrotjenester
Å gå over til mikrotjenester er ikke bare en mote: Det gir konkrete fordeler innen skalerbarhet, robusthet og distribusjonshastighet.Men det introduserer også en operasjonell kompleksitet som må håndteres.
Blant de mest bemerkelsesverdige fordelene er uavhengig skalerbarhet for hver tjenesteHvis for eksempel betalingsmodulen mottar mer trafikk enn administrasjonsmodulen, kan du bare øke replikaene av betalingsmikrotjenesten, uten å berøre resten av applikasjonen eller sløse med ressurser.
Du tjener også mye på kontinuerlig utplassering og hyppige leveranserVed å isolere hver tjeneste er det mulig å utgi nye versjoner trinnvis, uten å måtte stoppe eller distribuere hele applikasjonen på nytt, noe som reduserer vedlikeholdsvinduer og forbedrer tiden det tar før den kommer på markedet.
Et annet nøkkelpoeng er robusthet og feiltoleranseNår den er riktig utformet, bør ikke feil i én mikrotjeneste føre til at hele systemet faller ned. Med mønstre som tidsavbrudd, nye forsøk og sikringsbrytere kan de andre tjenestene fortsette å reagere, noe som begrenser virkningen av feilene.
Videre tillater mikrotjenester teknologisk fleksibilitetHvert team kan velge språket, rammeverket eller databasen som er mest passende for tjenesten sin, så lenge de respekterer kommunikasjonskontraktene og plattformens globale retningslinjer.
På den andre siden av mynten finner vi operasjonell og observerbarhetskompleksitetÅ administrere dusinvis eller hundrevis av tjenester innebærer håndtering av distribuerte nettverk, sporing mellom tjenester, sentralisert logging, sikkerhet, API-versjonering og datakonsistens, noe som krever avanserte verktøy og modne prosesser.
Det blir også komplisert håndtering av kommunikasjon mellom tjenesterDet er viktig å nøye utforme hvordan data utveksles, hvordan feil håndteres, hvordan latens styres, og hvordan man kan forhindre at en langsom avhengighet drar ned resten av systemet. Testing og feilsøking slutter å være trivielt, fordi Det er ikke en enkelt blokk som testes, men et sett med sammenkoblede tjenester..
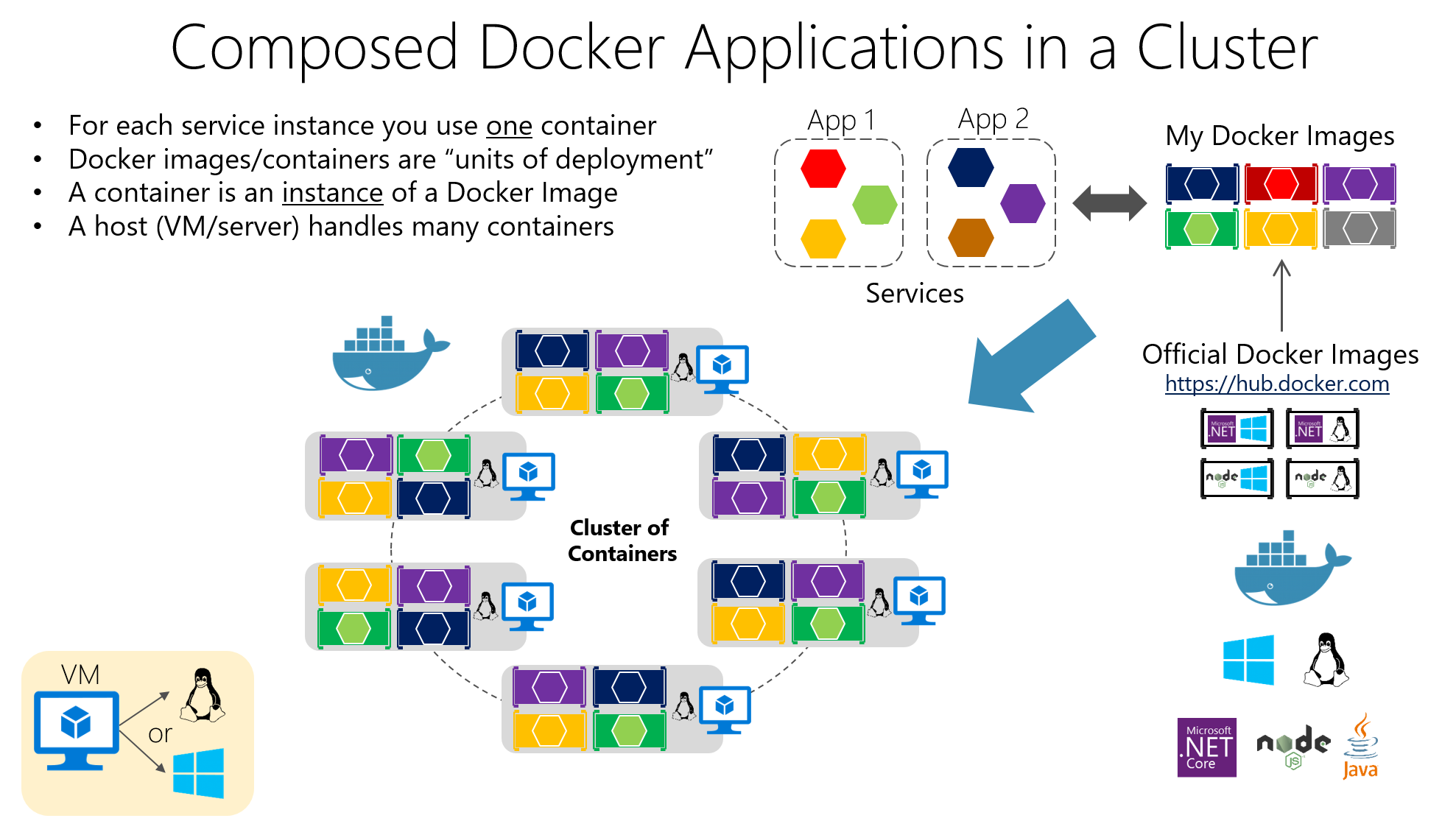
Containere: grunnlaget for å kjøre mikrotjenester isolert
Containerteknologi har blitt den ideelle støtten for mikrotjenester fordi Den lar deg pakke et program og alle dets avhengigheter inn i en standardisert og portabel enhet.I stedet for å installere biblioteker, kjøretider og verktøy på hver server, beveger alt seg innenfor containeren.
En beholder er i bunn og grunn, en lett form for virtualisering på operativsystemnivådeler vertskjernen, men kjører prosesser i isolerte navnerom og med ressurser begrenset av cgroups, noe som gjør at de starter opp raskt og bruker mindre enn en virtuell maskin.
Blant dens viktigste egenskaper er isolasjon, bærbarhet, letthet og modularitetHver mikrotjeneste som kjører i sin egen container blir enklere å distribuere, stoppe, oppdatere eller replikere, noe som passer perfekt til prinsippene for distribuerte arkitekturer.
Sammenlignet med virtuelle maskiner for produksjonbeholderne De trenger ikke et komplett operativsystem per instans.men heller dele vertens. Dette reduserer størrelsen på bildene drastisk og tiden de bootslik at du kan løfte eller ødelegge containere på sekunder.
Docker: referanseplattformen for containerisering av mikrotjenester
Docker er det mest populære verktøyet for å jobbe med containere, fordi Det forenkler opprettelse, pakking, distribusjon og utførelse av containeriserte applikasjoner både i utviklingsmiljøer og i testing og produksjon.
Hovedideen deres er å pakke programvaren inn i Docker-bilderDette er uforanderlige artefakter som inkluderer applikasjonskoden, bibliotekene den trenger, systemverktøy og grunnleggende konfigurasjoner. Applikasjoner opprettes fra disse avbildningene. containere i drift, som er isolerte tilfeller basert på det bildet.
Bildekonstruksjon er definert i en Dockerfile, en tekstfil som spesifiserer instruksjoner som basisbildet, arbeidskatalogen, hvilke filer som skal kopieres, hvilke avhengigheter som skal installeres, hvilke porter som skal eksponeres og hvilken kommando som skal kjøres når containeren startes.
Tenk deg at du har et API skrevet i Node.js. Du kan opprette en Dockerfile som ligner på følgende, der Med utgangspunkt i et offisielt Node-bilde kopieres filene, avhengighetene installeres og oppstartskommandoen defineres.:
FROM node:14
WORKDIR /app
COPY . .
RUN npm install
EXPOSE 3000
CMD
Denne filen indikerer at programmet vil kjøre i katalogen /app inne i beholderen, at avhengighetene vil bli installert med npm, at port 3000 vil bli eksponert, og at den vil kjøres når containeren startes npm start.
For å bygge og starte den containeren, kjør ganske enkelt kommandoen fra prosjektmappen. dockerbygg og deretter docker kjørekartlegging av portene for å tillate tilgang fra verten, eller for bruk av applikasjoner med flere containere Docker-komponere:
docker build -t mi-app .
docker run -p 3000:3000 mi-app
Takket være denne modellen, Det klassiske problemet med «det fungerer på maskinen min» er redusert til et minimum.Fordi kjøretidsmiljøet følger med applikasjonen. Videre integreres Docker sømløst med CI/CD-systemer, private registre og orkestreringsverktøy som Kubernetes.
Viktige komponenter i Docker og deres rolle i mikrotjenester
I en typisk utplassering snakker vi om en Docker-vertsom er systemet (fysisk eller virtuelt) der Docker er installert; det kjører oppå det. Docker-motor, daemonen som administrerer bilder, nettverk, volumer og containerens livssyklus.
Beholderne inneholder applikasjon og dens avhengigheter pakket i et bildeDette gjør at enhver server med Docker kan kjøre det bildet konsekvent. Denne konsistensen er avgjørende når du har mange mikrotjenester distribuert i ulike miljøer (utvikling, QA, produksjon osv.).
Blant de mest interessante fordelene med Docker er portabilitet mellom miljøer, distribusjonsautomatisering, prosessmodularitet og støtte for lagdeling og versjonskontroll i bildernoe som gjør det enklere å reversere endringer og optimalisere lagring.
Kubernetes: orkestratoren for å styre hundrevis av containere
Når du går fra noen få containere til dusinvis eller hundrevis av dem, Å administrere dem manuelt blir galskapDet er her Kubernetes kommer inn i bildet, en åpen kildekode-plattform designet for å orkestrere containere i stor skala.
Kubernetes automatiserer kritiske oppgaver som distribusjon, skalering, feilgjenoppretting, nettverkskonfigurasjon og lagring av containeriserte applikasjoner. Den er designet for å fungere i offentlige skyer, private skyer, hybridmiljøer og til og med lokale applikasjoner.
Fokuset er på å administrere klynger som består av flere noder (maskiner) der containere kjører. Målet er å sikre at applikasjonene er alltid i ønsket tilstandantall replikaer, distribuerte versjoner, tildelte ressurser og tilkobling mellom tjenester.
Grunnleggende elementer i Kubernetes
Den minste enheten i Kubernetes er PodEn Pod representerer én eller flere containerinstanser som må kjøres sammen (for eksempel en applikasjonscontainer og en sidecarcontainer for logging). Poder er flyktige. De opprettes, ødelegges og erstattes i henhold til klyngens behov.
For å eksponere podene dine tilbyr Kubernetes ressursen Servicesom fungerer som et nettverksabstraksjonslag. En tjeneste grupperer et sett med Pods og Den gir en stabil IP-adresse, et DNS-navn og intern lastbalansering.slik at kundene ikke trenger å vite detaljene om hver pod.
Ressursen Utplassering Den brukes til å definere hvordan Pods skal distribueres og oppdateres: hvor mange replikaer, hvilket image som skal brukes, hvilke tagger som skal brukes, og hvilken oppdateringsstrategi som skal følges. Kubernetes håndterer dette. alltid holde ønsket antall Pods i gang og for å utføre rullerende oppdateringer eller tilbakestillinger når du endrer konfigurasjonen.
Det finnes også ressurser som ConfigMap og hemmelighetDisse funksjonene lar deg eksternalisere konfigurasjon og lagre sensitive data (passord, tokens, API-nøkler) uten å måtte pakke dem inn i avbildningene. Dette forenkler sikker konfigurasjonsadministrasjon på tvers av ulike miljøer betraktelig.
Slik organiserer du en Kubernetes-klynge
«Hodet» til klyngen er Kubernetes-kontrollplansom grupperer sammen flere komponenter som er ansvarlige for å orkestrere hele systemet. Blant dem er API-serversom er inngangsporten til å administrere klyngen; enhver handling (opprette en distribusjon, liste opp poder, endre en tjeneste) går gjennom dette API-et.
El Scheduler Den er ansvarlig for å bestemme hvilken node hver Pod kjører på, tatt i betraktning tilgjengelige ressurser, tilhørigheter og begrensninger; mens Kontrollørsjef Overvåk klyngens status og iverksett tiltak for å sikre at virkeligheten samsvarer med det du har oppgitt i manifestene (for eksempel opprett nye Poder hvis det er færre enn du ba om).
Statlig lagring er delegert til osvEn distribuert database lagrer konfigurasjonen og informasjonen for alle klyngens ressurser. I tillegg kjøres prosesser som følgende på hver arbeidsnode: kubelet (agent som kommuniserer noden med API-serveren), kube-proxy (som administrerer nettverkstrafikk og lastbalansering) og containerkjøringstid (Docker, containerd, CRI-O, osv.).
Distribuere mikrotjenester i Kubernetes med YAML-filer
For å distribuere en mikrotjeneste i Kubernetes er det vanlig å beskrive den med en YAML-manifestet, der du definerer distribusjonen (Pod-mal, bilde, porter, antall replikaer, etiketter) og den tilhørende tjenesten for å eksponere den i eller utenfor klyngen.
Et grunnleggende eksempel på distribusjon for en applikasjon kalt «min-app» kan se omtrent slik ut, der Tre replikaer og port 3000 er definert som containerhavn:
apiVersion: apps/v1
kind: Deployment
metadata:
name: mi-app
spec:
replicas: 3
selector:
matchLabels:
app: mi-app
template:
metadata:
labels:
app: mi-app
spec:
containers:
- name: mi-app
image: mi-app:latest
ports:
- containerPort: 3000
Dette manifestet indikerer at klyngen må opprettholde tre pods i drift Med bildet «my-app:latest» er alle merket med app=my-app, slik at en tjeneste kan finne dem og fordele trafikk mellom dem. Kubernetes håndterer automatisk logikken for skalering, oppdateringer og utskifting av Pods ved feil.
Sammen med distribusjoner er det vanlig å definere tjenester av typen ClusterIP, NodePort eller LoadBalancerAvhengig av om mikrotjenesten bare skal være tilgjengelig i klyngen, fra nodene eller fra internett, versjoneres all denne konfigurasjonen i repositorier, og integreres sømløst med CI/CD-pipelines.
Skalering, oppgraderinger og selvreparasjon i Kubernetes
En av de viktigste grunnene til å bruke Kubernetes er dens evne til å skaler og oppdater mikrotjenester uten å stoppe applikasjonenDu kan endre antall replikaer i manifestet (eller med en kubectl-kommando), og klyngen vil ta seg av å opprette eller fjerne poder til ønsket verdi er nådd.
Denne skaleringen kan være manuell eller automatisk, ved hjelp av ressurser som Horisontal pod-autoskalering (HPA)Denne funksjonen justerer dynamisk replikaer basert på målinger som CPU eller minne. Dermed økes kapasiteten i perioder med høy etterspørsel, og ressurser frigjøres når belastningen reduseres.
Når det gjelder oppdateringer, implementerer Kubernetes rullerende oppdateringer Som standard oppretter den Pods med den nye versjonen og sletter gradvis disse fra den forrige versjonen, uten å gjøre et brått kutt. Hvis noe går galt, en rollback Det lar deg raskt gjenopprette den forrige versjonen.
En annen kritisk funksjonalitet er selvreparasjonHvis en container eller Pod slutter å virke, gjenskaper Kubernetes den automatisk. Hvis en node slutter å svare, blir de berørte Podene omplanlagt på andre tilgjengelige noder, slik at applikasjonen holder seg i drift.
Overvåking og observerbarhet av mikrotjenester i Kubernetes
For å drifte et mikrotjenestemiljø riktig, er det ikke nok å bare distribuere og skalere: Du trenger sanntidsinnsikt i ytelsen og statusen til tjenesteneI Kubernetes er det veldig vanlig å integrere verktøy som Prometheus for å samle inn målinger og Grafana for å visualisere dem.
Prometheus håndterer «skraping» av metrikker fra Pods, noder og klyngekomponenter, lagrer dem og lar deg definere varsler om dem. Kombinert med Grafana kan du opprette dashbord der Overvåk CPU-bruk, minne, HTTP-feil, latens, antall replikaer eller nodestatus veldig tydelig.
I tillegg tilbyr kubectl kommandoer For å inspisere statusen til distribusjoner, tjenester, poder og andre ressurser, se loggerDette inkluderer å beskrive hendelser eller få tilgang til containere for feilsøking. Alt dette er en del av en observerbarhetsstrategi som i mikrotjenester, Det er ikke valgfritt hvis du vil sove fredelig..
Forholdet mellom mikrotjenester, Docker og Kubernetes
Mikrotjenester, Docker og Kubernetes passer sammen som brikker i samme puslespill: Mikroservices-arkitekturen definerer hvordan du designer applikasjonen, Docker håndterer pakking og kjøring av hver tjeneste, og Kubernetes orkestrerer alle disse containerne. i en klynge.
Hver mikrotjeneste er innkapslet i et Docker-bilde som inkluderer koden og avhengigheteneDette sikrer at den oppfører seg på samme måte på en utviklers bærbare datamaskin, i et testmiljø eller i skybasert produksjon. Denne konsistente pakkingen er avgjørende for DevOps-filosofien.
Kubernetes fungerer på sin side som containerorkestratorDen bestemmer hvor mange forekomster av hver mikrotjeneste som skal kjøre, hvor de befinner seg, hvordan trafikken balanseres til dem, hvordan de gjenoppretter seg etter feil, og hvordan de skalerer når etterspørselen øker eller synker.
I en e-handelsapplikasjon kan du for eksempel ha mikrotjenester for autentisering, katalog, handlekurv og betalinger, hver med sitt eget Docker-image og Kubernetes-distribusjon. På denne måten, Du kan skalere katalogen i massive kampanjer eller betalinger på kritiske tidspunkter uten å påvirke restenog orkestrere hele livssyklusen fra CI/CD-rørledninger til overvåking etter produksjon.
Installere Docker og Kubernetes på Windows
Hvis du jobber med Windows, er den enkleste måten å starte på å installere DockerDesktopsom inkluderer Docker-motoren og tilleggsverktøy, og til og med alternativer for å aktivere Kubernetes integrert i maskinen din.
Den typiske prosessen innebærer Last ned Docker Desktop fra det offisielle nettstedetKjør installasjonsprogrammet (Docker Desktop Installer.exe) og følg veiviseren. Under installasjonen kan du velge mellom å bruke Hyper-V eller WSL 2 som en virtualiseringsteknologi; hvis det bare er én tilgjengelig, er det den som vil bli brukt.
Etter at systemet har startet på nytt, initialiserer åpningen av Docker Desktop containermiljøet. Hvis virtualisering ikke var aktivert, tilbyr installasjonsprogrammet vanligvis selv aktiver den automatiskDerfra kan du starte containere, for eksempel Nginx eller dine egne applikasjoner.
For å bruke Kubernetes på Windows må du først ha Docker og virtualiseringsfunksjoner aktivert. Deretter kan du aktivere Kubernetes fra Docker Desktop eller installere og konfigurere kubectl å administrere eksterne klynger og, om aktuelt, distribuere Kubernetes-dashbordet via et eksternt manifest.
Når den er konfigurert, vil du kunne få tilgang til dashbordet via en lokal proxy, ved å bruke et autentiseringstoken generert med kubectl og som for eksempel peker til konfigurasjonsfilen. .kube/konfigurasjon for å administrere tilgang til klyngen fra nettleseren.
Installere Docker og Kubernetes på Linux
På Linux-systemer, som Ubuntu, er det vanligvis ganske enkelt å installere Docker: Pakkene oppdateres, Docker-motoren installeres, og miljøet kontrolleres for å sikre at det fungerer som det skal. kjører en testcontainer.
Typiske trinn inkluderer å oppdatere systemet med apt-get oppdatering og apt-get oppgraderingFjern eventuelle tidligere versjoner av Docker Desktop, og installer deretter docker-ce, docker-ce-cli, containerd.io og docker-compose-pluginen fra de offisielle databasene eller ved å spesifisere ønsket versjon.
For å bekrefte at alt er i orden, lanseres vanligvis en "hello-world"-container. Den laster ned et minimalt bilde og kjører det.Hvis meldingen vises riktig, har du Docker oppe og kjører, og du er klar til å begynne å containerisere mikrotjenestene dine.
Når det gjelder Kubernetes, kan det installeres på Linux ved hjelp av verktøy som kubeadmDen typiske arbeidsflyten innebærer å legge til Kubernetes-repositorynøkkelen, konfigurere pakkelistefilen, installere kubeadm og sjekke versjonen.
Klyngen initialiseres deretter på masternoden med kubeadm init (spesifiserer nettverksområdet for podene), hentes kommandoen «join» slik at arbeidsnodene blir med i klyngen, og lokal tilgang konfigureres ved å opprette katalogen $HJEM/.kubeved å kopiere admin.conf-filen og justere tillatelsene.
Med dette har du en grunnleggende klynge klar for distribuer containeriserte mikrotjenester, installer et nettverk av poder (Flannel, Calico, osv.) og begynn å jobbe med distribusjoner, tjenester og resten av Kubernetes-ressursene.
Beste praksis og anbefalinger for bruk av Docker og Kubernetes
For å få mest mulig ut av disse miljøene, anbefales det å følge en rekke beste praksiser med Docker, som starter med bruk offisielle eller pålitelige bilder, enten fra Docker Hub eller fra verifiserte private databaser, for å redusere sikkerhetsrisikoer.
Det anbefales på det sterkeste optimalisere bildestørrelsen bruk av lette basisbilder, flertrinnsbygg og fjerning midlertidige filer eller unødvendige artefakter. Mindre bilder lastes ned raskere og øker hastigheten på distribusjoner på Kubernetes.
Et annet viktig poeng er å bruke volumer for datapersistensI stedet for å lagre informasjon i containere, innebærer ikke tap eller gjenskaping av en container tap av viktige data.
Å begrense ressursene som er tildelt hver container (CPU, minne, I/O) bidrar til å forhindre at en enkelt tjeneste monopoliserer verten og degradere resten. Videre må containere overvåkes med verktøy som Docker Stats eller mer avanserte løsninger for å opprettholde kontroll i produksjonen.
Med Kubernetes er det viktig å forstå klyngearkitekturen og dens komponenter før man går i produksjon. Dette reduserer mange problemer.
Det er også en god idé automatisere så mye som muligBruk replikeringskontrollere, autoskaleringer og jobber for batchopplastinger; dra nytte av rullerende oppdateringer og tilbakestillinger; og definer versjonerte deklarative manifester i Git-repositorier.
Sikkerhet må alltid være en topprioritet: Begrens tilgang til API-serveren, administrer legitimasjon ved hjelp av hemmeligheter, krypter data under overføring og i roInstaller oppdateringer regelmessig og definer nettverkspolicyer som begrenser kommunikasjon mellom tjenester i henhold til prinsippet om minste privilegium.
Til slutt er det viktig å ha gode sentraliserte overvåkings- og loggføringssystemersamt med førproduksjonsmiljøer der endringer kan testes grundig før de bringes til produksjonsklyngen, noe som reduserer risikoer og ubehagelige overraskelser.
Hele dette økosystemet av mikrotjenester, Docker-containere og Kubernetes-orkestrering lar deg bygge systemer som er mye mer fleksible, skalerbare og robuste enn tradisjonelle monolitter. Ved å kombinere en gjennomtenkt arkitektur, passende verktøy og beste praksis for DevOps, kan du distribuere applikasjoner som tilpasser seg sømløst til endringer i arbeidsmengden, gjenoppretter raskt fra feil og er enklere å utvikle over tid.

Lidenskapelig forfatter om verden av bytes og teknologi generelt. Jeg elsker å dele kunnskapen min gjennom å skrive, og det er det jeg skal gjøre i denne bloggen, vise deg alle de mest interessante tingene om dingser, programvare, maskinvare, teknologiske trender og mer. Målet mitt er å hjelpe deg med å navigere i den digitale verden på en enkel og underholdende måte.