- Sokongan berbilang bahasa dan format output untuk pengimbasan yang cekap.
- Penyepaduan mudah dengan Python (Pytesseract) dan ekosistem .NET.
- IronOCR membawakan prapemprosesan dan API peringkat tinggi kepada Tesseract.
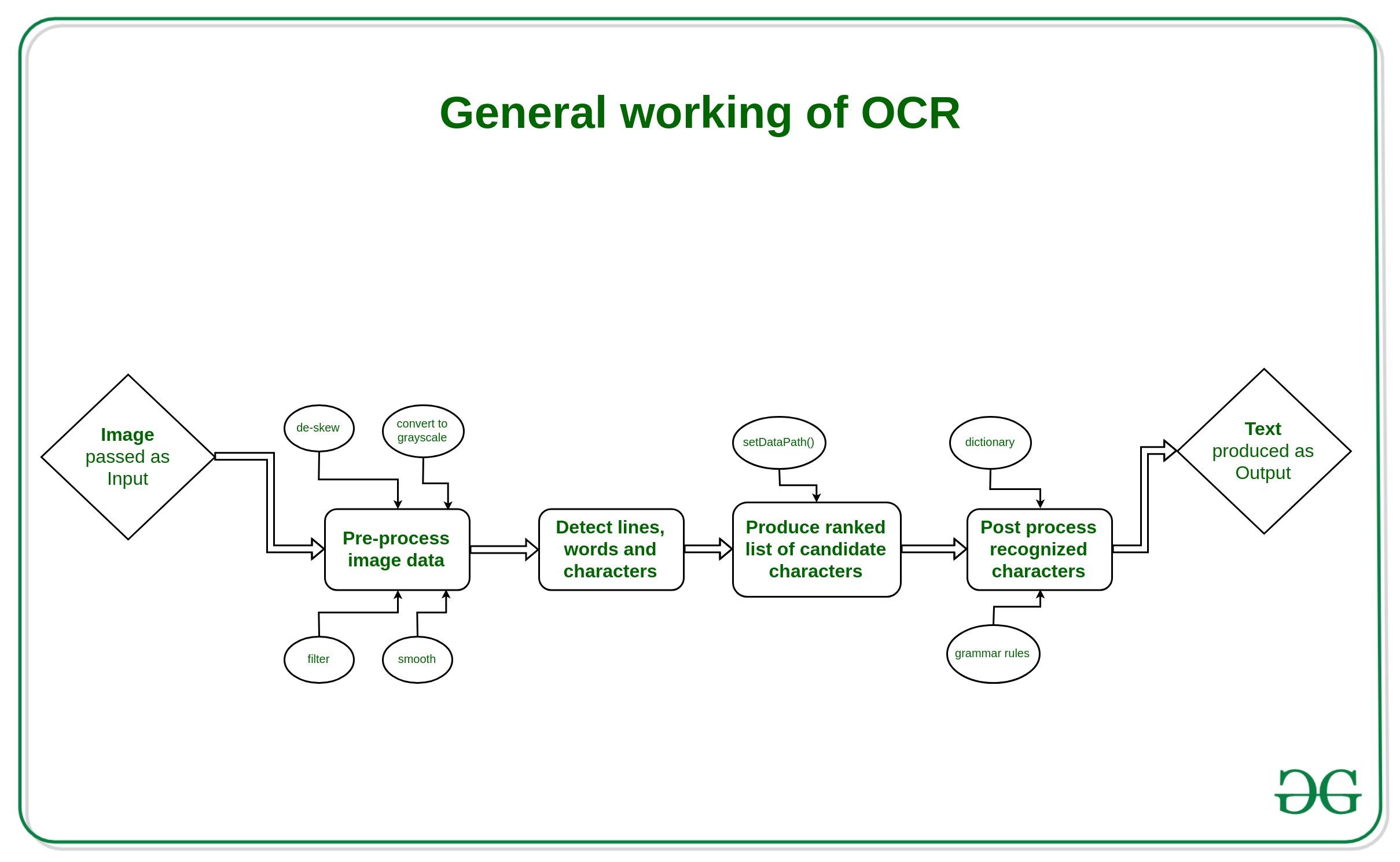
Jika anda berminat untuk menukar imej atau PDF kepada teks boleh diedit tanpa bergelut dengan alatan yang kompleks, atau Ekstrak teks daripada imej dalam Windows 11, berita baiknya ialah hari ini Tesseract OCR ialah penyelesaian yang berkuasa, percuma dan sangat fleksibelDalam panduan praktikal ini, kami menyemak apa itu, cara memasangnya Windows, cara mengesahkannya daripada konsol, dan cara mengintegrasikannya dengan Python (melalui Pytesseract) dan .NET, serta alternatif yang digunakan secara meluas dalam ekosistem itu: IronOCR.
Selain memasang dan mengklik butang, anda akan melihat cara menyediakan persekitaran, tempat untuk menambah laluan boleh laku, apa yang perlu dilakukan jika ralat biasa muncul TesseractNotFoundError dalam Python, dan cara memproses teks dalam pelbagai bahasa (Sepanyol, Inggeris, Perancis, Portugis, dan juga pakej seperti Matematik) dalam aplikasi. Matlamatnya adalah untuk anda mendapat aliran kerja OCR sedia pengeluaran yang stabil., meliputi daripada barisan arahan sehingga digunakan dalam C# dengan perpustakaan tertentu.
Apakah Tesseract OCR?
Tesseract ialah enjin OCR sumber terbuka, diterbitkan di bawah lesen Apache 2.0. Ia dilahirkan pada tahun 80-an di Hewlett‑Packard dan kini diselenggara oleh komuniti dengan dorongan kuat untuk GoogleMisinya jelas: menganalisis piksel dalam imej (TIFF, PNG, JPEG, antara lain) untuk mengesan aksara, perkataan dan baris serta mengeluarkan kandungan sebagai teks yang boleh dibaca mesin.
Ia boleh digunakan secara bebas dari baris arahan, menjadikan automasi dan skrip lebih mudah. Di samping itu, ia menyokong pelbagai bahasa dan boleh dilatih untuk fon atau abjad baharu., itulah sebabnya ia adalah perkara biasa dalam pendigitalan dokumen, pemprosesan invois, pengarkiban atau kebolehaksesan.
Muat turun dan pasang Tesseract pada Windows
Pada Windows, laluan paling langsung ialah menggunakan pemasang pra-disusun. Sumber utama ialah repositori rasmi di GitHub (tesseract-ocr/tesseract), di mana anda akan menemui binari yang ditandatangani dan versi terkini.
Antara pemasang yang tersedia, adalah biasa untuk melihat pakej seperti tesseract-ocr-w64-setup-5.3.0.20221222.exe (64 bit). Muat turun dan jalankannyaWizard akan membimbing anda melalui persediaan langkah demi langkah, termasuk memilih bahasa pemasang dan pek bahasa.
Bahasa pemasang dan data bahasa
Semasa pemasangan, wizard akan meminta anda memilih bahasa anda. Bahasa Inggeris biasanya lalai, tetapi anda boleh menambah pakej tambahan seperti bahasa Sepanyol, Perancis atau modul khusus seperti Matematik jika anda memerlukannya. Pemilihan ini menentukan model mana yang disalin ke direktori data (tessdata).
Lesen, pengguna dan komponen
Tesseract diedarkan dengan Lesen Apache 2.0, supaya anda boleh menggunakan dan mengedarkannya semula secara fleksibel. Pemasang akan meminta anda menerima lesen, memilih sama ada untuk memasang untuk pengguna tunggal atau untuk semua pengguna dan pilih komponen. Elemen berguna dipilih secara lalai, seperti ScrollView, alatan latihan, pintasan dan data bahasa.
Laluan pemasangan dan folder menu Mula
Wizard akan membenarkan anda memilih folder destinasi. Tulis laluan itu, anda akan memerlukannya untuk pembolehubah persekitaran. Anda kemudiannya boleh menamakan folder menu Mula tempat pintasan dibuat. Setelah selesai, klik Pasang, dan setelah selesai, klik Selesai untuk menutup.
Tambahkan Tesseract pada pembolehubah persekitaran pada Windows
Untuk menjalankan arahan tesseract dari mana-mana tetingkap cmd o PowerShell, ia adalah mudah tambah folder pemasangan ke laluan sistem. Dengan cara ini Windows akan tahu di mana untuk mencari boleh laku tanpa laluan mutlak.
Pergi ke carian menu Mula dan taip "pembolehubah persekitaran" atau "tetapan sistem lanjutan." Dalam tetingkap System Properties, pergi ke tab Advanced dan klik Pemboleh ubah Persekitaran.
Dalam blok Pembolehubah Sistem, pilih Jalan, klik Edit dan kemudian Baharu. Tampal laluan di mana Tesseract dipasang (contohnya, C:\Program Files\Tesseract-OCR) dan sahkan dengan OK dalam semua tetingkap.
Semak pemasangan dari konsol
Buka cmd atau PowerShell dan jalankan: tesseractJika semuanya teratur, anda akan melihat mesej penggunaan, versi yang dipasang dan senarai pilihan yang disokong oleh utiliti. Ujian ini mengesahkan bahawa Path adalah betul dan binari bertindak balas.
Pasang Tesseract pada macOS
Pada macOS, anda boleh memasang utiliti daripada pengurus pakej. Dengan Homebrew, jalankan bru pasang tesseract. Jika anda menggunakan MacPorts, arahan yang sama ialah sudo port memasang tesseract. Kedua-dua laluan muat turun dan daftarkan boleh laku untuk menggunakannya daripada Terminal.
Perbezaan antara Tesseract dan Pytesseract
Adalah mudah untuk memisahkan konsep: Tesseract ialah enjin OCR, binari yang melakukan pengiktirafan. Pytesseract ialah pembungkus untuk Python yang memanggil enjin itu dan memformatkan output untuk skrip anda. Jika anda bekerja dalam Python, anda memerlukan Tesseract dipasang pada sistem anda dan Pytesseract dalam persekitaran anda.
Penggunaan asas dengan Python dan penyelesaian kepada TesseractNotFoundError
Salah satu kesilapan yang paling biasa apabila anda mula menggunakan Python ialah TesseractNotFoundError. Ia berlaku apabila Pytesseract tidak mengesan enjin boleh laku, biasanya kerana ia tidak berada dalam Laluan atau laluan belum ditetapkan dalam skrip.
Untuk mengelakkan ini pada Windows, anda boleh menetapkan laluan secara eksplisit dalam kod anda dengan menunjuk pada boleh laku. Contoh minimum dengan Pytesseract:
import pytesseract
from PIL import Image
# Ajusta esta ruta a tu instalación real en Windows
pytesseract.pytesseract.tesseract_cmd = r'C:\\Program Files\\Tesseract-OCR\\tesseract.exe'
texto = pytesseract.image_to_string(Image.open('mi_imagen.png'), lang='spa')
print(texto)Juga, pastikan bahawa pek bahasa yang anda perlukan tersedia (contohnya, spa untuk bahasa Sepanyol). Jika tidak, pasang data terlatih itu dalam direktori tessdata yang betul. Ini menyelesaikan kebanyakan insiden. apabila bermula dengan Python.
OCR berbilang bahasa: Konsep dan Amalan
Dalam projek dengan dokumentasi berbilang bahasa (invois, kontrak atau arkib sejarah), Tesseract membolehkan anda menggabungkan bahasa untuk meningkatkan pengesanan apabila teks heterogen wujud bersama. Perkara utama ialah mempunyai fail .traineddata yang sesuai dalam tessdata.
Apabila kandungan bercampur, contohnya, Inggeris, Sepanyol dan Perancis, anda boleh memberitahu enjin untuk melakukan ini. pertimbangkan berbilang abjad dan corak secara serentakIni juga terpakai kepada perpustakaan peringkat tinggi seperti IronOCR dalam .NET.
Buat projek dalam Visual Studio dan gunakan Tesseract.NET
Jika anda bekerja dalam persekitaran Microsoft, buka Visual Studio dan buat a Aplikasi Konsol (atau apa sahaja templat yang anda suka). Namakan projek anda, pilih versi .NET dan dengan penyelesaian anda dibuat, anda sudah bersedia untuk mengurus pakej dengan NuGet.
Pasang Tesseract pada komputer anda (seperti yang kami jelaskan) dan dalam projek tambah pakej Tesseract atau Tesseract.NET daripada Pengurus Pakej NuGet. Ini menambah pembungkus untuk berinteraksi dengan enjin daripada C#.
Contoh untuk membaca imej dengan pelbagai bahasa mungkin kelihatan seperti ini, menunjukkan laluan ke tessdata dan senarai bahasa:
using System;
using System.Drawing;
using Tesseract;
class Program
{
static void Main()
{
// Ruta a los archivos de datos de idioma (.traineddata)
string tessDataPath = @"./tessdata";
// Imagen a procesar
string imagePath = @"ruta_a_tu_imagen.png";
using (var img = Pix.LoadFromFile(imagePath))
using (var engine = new TesseractEngine(tessDataPath, "eng+spa+fra", EngineMode.Default))
using (var page = engine.Process(img))
{
string text = page.GetText();
Console.WriteLine("Recognized Text:");
Console.WriteLine(text);
}
}
}Pastikan yang berikut wujud dalam folder tessdata: .data terlatih untuk setiap bahasa yang anda isytiharkan. Suite ujian biasa ialah eng+spa+fra, tetapi anda boleh mengembangkannya mengikut keperluan anda.
IronOCR: Pustaka .NET berasaskan Tesseract
Dalam ekosistem .NET terdapat pilihan berorientasikan produktiviti yang dipanggil IronOCR, yang bergantung pada Tesseract tetapi menawarkan API peringkat tinggi, dokumentasi yang luas dan utiliti prapemprosesan. Ia dipasang daripada NuGet dalam Visual Studio menggunakan pencari pakej.
Penggunaan asasnya untuk membaca teks imej adalah sangat langsung. Contoh mudah:
using IronOcr;
var ocr = new IronTesseract();
string texto = ocr.Read(@"test-files/redacted-employmentapp.png").Text;
Console.WriteLine(texto);Jika anda lebih suka kawalan ke atas input (berbilang imej, pelarasan, dll.), anda boleh membina OcrInput dan menghantarnya ke enjin. Contoh dengan menggunakan corak:
using IronOcr;
var Ocr = new IronTesseract();
using (var Input = new OcrInput())
{
Input.AddImage("test-files/redacted-employmentapp.png");
var Result = Ocr.Read(Input);
Console.WriteLine(Result.Text);
}Kelebihan utama ialah itu IronOCR menyokong lebih 120 bahasa, menyepadukan pengesanan automatik dan menambah pembersihan imej, pengurangan hingar dan alat pembetulan artifak yang, dalam amalan, meningkatkan ketepatan pada dokumen yang sukar.
Pasang IronOCR dengan NuGet dan pek bahasa
Untuk menambahkannya pada penyelesaian anda, buka Visual Studio dan navigasi ke Alat > Pengurus Pakej NuGet > Urus Pakej untuk Penyelesaian. Cari "IronOCR" dan pilih pakej utamaJika anda bercadang untuk menggunakan bahasa tambahan, pasang juga pek bahasa yang diperlukan.
Dalam projek berbilang bahasa, ingat bahawa bahasa Inggeris biasanya tersedia secara lalai, tetapi Untuk bahasa Sepanyol atau Perancis anda mesti menambah pakej merekaIni akan menjimatkan masa anda apabila menetapkan sifat Bahasa dalam enjin.
Membaca Pelbagai Bahasa dengan IronOCR (C#)
Contoh berikut menunjukkan cara menggabungkan tiga bahasa dan memproses imej. Ia adalah persediaan semula jadi apabila anda tidak pasti bahasa mana yang dominan dalam setiap dokumen:
using IronOcr;
class Program
{
static void Main(string[] args)
{
var Ocr = new IronTesseract();
Ocr.Language = OcrLanguage.English + OcrLanguage.Spanish + OcrLanguage.French;
var inputFile = @"ruta\\a\\tu\\imagen.png";
using (var input = new OcrInput(inputFile))
{
var result = Ocr.Read(input);
Console.WriteLine("Text:");
Console.WriteLine(result.Text);
}
}
}Sebagai tambahan kepada API mudah, IronOCR menonjol untuk disertakan prapemprosesan imej (deskew, binarization, edge cleaning), yang biasanya menghasilkan lebih banyak kejayaan dengan dokumen yang diimbas atau foto dengan pencahayaan yang tidak sekata.
Kelebihan dan pertimbangan IronOCR berbanding Tesseract "tulen".
Walaupun Tesseract adalah percuma dan sangat fleksibel, IronOCR menawarkan a lebih banyak pengalaman langsung dalam .NET, dengan dokumentasi, contoh dan ciri sedia perusahaan. Sumber korporat telah menyebut ketepatan pengesanan sekitar 99,8% dalam keadaan ideal, bersama-sama dengan sokongan multithreading dan penyelenggaraan aktif.
Adakah juga lebih mesra dalam integrasi (hanya persediaan, projek contoh dan API padu), dengan sokongan untuk lebih 120 bahasa, termasuk kes kompleks dan berbilang bahasa dalam dokumen yang sama. Sebagai balasan, IronOCR adalah proprietari dan berbayar, dengan pelesenan seumur hidup dan pilihan sokongan 24/7 untuk pelanggan.
Amalan terbaik untuk meningkatkan ketepatan OCR
Walaupun enjinnya teguh, hasilnya sangat bergantung pada kualiti imej. Cuba gunakan resolusi tinggi, elakkan bunyi bising dan artifak, selaraskan dokumen dengan betul dan perbaiki kontras. Jika anda bekerja dengan foto, berhati-hati dengan pencahayaan dan pencongan yang betul sebelum melakukan OCR.
Dengan Tesseract "tulen", mungkin diperlukan untuk menormalkan imej atau menggunakan pra-penapis untuk mendapatkan hasil yang baik. Alat seperti IronOCR membantu dengan mengautomasikan kebanyakan prapemprosesan ini., yang memudahkan penyampaian teks bersih dalam senario yang menuntut.
Output dan format yang anda boleh hasilkan
Sebagai tambahan kepada teks biasa, Tesseract boleh menghasilkan output dalam HTML/hOCR atau PDF dengan teks yang boleh dipilihIni membuka pintu untuk mengindeks, mencari dan menyerlahkan serpihan dalam dokumen, atau menyepadukannya ke dalam aliran kerja pengarkiban digital di mana keupayaan carian adalah penting.
Selain teks biasa, Tesseract boleh menghasilkan output HTML/hOCR atau PDF dengan teks yang boleh dipilih, menjadikannya mudah untuk menukar PDF kepada Word dan teruskan mengedit.
Dalam penyepaduan tersuai, anda boleh selepas memproses hasilnya, gunakan semakan ejaan atau model NLP untuk memperkayakan entiti, menormalkan nombor dan menyediakan kandungan untuk pangkalan data atau alat analisis.
Pemasangan Berpandu pada Windows: Sorotan Wizard
Jika anda mahukan senarai semak pantas wizard: pilih bahasa pemasang, terima lesen Apache 2.0, tentukan sama ada pemasangan adalah untuk anda atau untuk semua pengguna dan biarkan komponen yang disyorkan diaktifkan (ScrollView, alatan latihan, pintasan dan data bahasa).
Pilih folder destinasi (ingat untuk menyalinnya ke Laluan), namakan folder menu Mula jika berkenaan, dan tekan Pasang. Apabila selesai, sahkan dengan "tesseract" dalam konsol untuk memastikan semuanya bertindak balas dengan betul pada peranti anda.
Pemasangan dengan pakej pra-disusun dan pilihan bahasa
Apabila anda memuat turun daripada GitHub, anda akan melihat beberapa pemasang dan binaan untuk seni bina yang berbeza. Pilih 64-bit jika sistem anda menyokongnya.Dalam wizard, anda boleh memilih bahasa tertentu; ini adalah idea yang baik. pasang yang anda akan gunakan (Bahasa Sepanyol, Portugis, Perancis, Matematik, dsb.) untuk mengelakkan carian seterusnya.
Jika anda kemudiannya perlu mengembangkan kepada bahasa lain, anda boleh menambahkan .traineddata mereka pada folder tessdata. Modulariti adalah salah satu perkara yang kuat enjin untuk menyesuaikan diri dengan domain yang berbeza.

Penulis yang bersemangat tentang dunia bait dan teknologi secara umum. Saya suka berkongsi pengetahuan saya melalui penulisan, dan itulah yang akan saya lakukan dalam blog ini, menunjukkan kepada anda semua perkara yang paling menarik tentang alat, perisian, perkakasan, trend teknologi dan banyak lagi. Matlamat saya adalah untuk membantu anda mengemudi dunia digital dengan cara yang mudah dan menghiburkan.