- マイクロサービスにより、各サービスが自律的で独立して展開可能な、モジュール式でスケーラブルなアプリケーションの開発が可能になります。
- Docker を使用すると、各マイクロサービスとその依存関係をパッケージ化する軽量でポータブルなコンテナーを簡単に作成できます。
- Kubernetes はコンテナをオーケストレーションし、クラスター内のマイクロサービスのデプロイメント、スケーリング、ネットワーク、自動リカバリを管理します。
- 適切なセキュリティ、監視、自動化のプラクティスを適用することが、本番環境でマイクロサービスを正常に運用するための鍵となります。
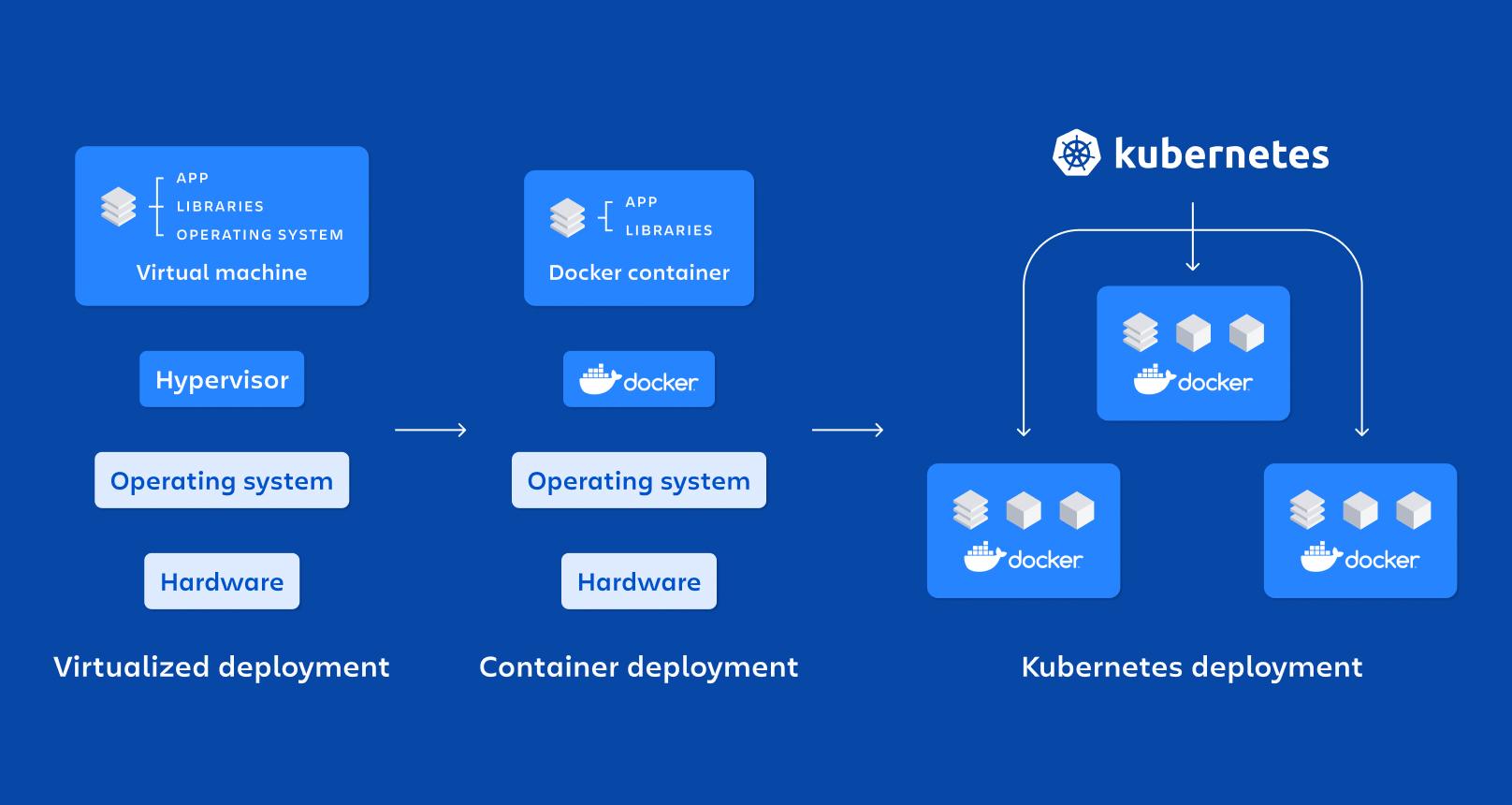
近年、 マイクロサービス、Docker、Kubernetesの組み合わせ スケーラブルでメンテナンスが容易な最新アプリケーションの導入における事実上の標準となっています。ますます多くの企業がモノリシックアプリケーションから脱却し、変化する環境やDevOps戦略に適した分散アーキテクチャへと移行しています。
もし疑問に思うなら DockerとKubernetesを使ったマイクロサービスの実践的な実装方法このコンテンツはあなたにぴったりです。主要な概念、利点と課題、コンテナの作成方法、コンテナをクラスターでオーケストレーションする方法、コンテナをインストールするための手順を確認します。 Windows y Linuxまた、実際の環境でそれらを賢く使用するためのヒントもいくつか紹介します。
マイクロサービス アーキテクチャとは何ですか? モノリスとどう違うのですか?
マイクロサービスアーキテクチャは、 アプリケーションを複数の小さな、自律的で独立して展開可能なサービスに分割するそれぞれが特定の機能(ユーザー、支払い、カタログ、注文など)に重点を置いており、主に軽量 API(HTTP/REST、gRPC、メッセージングなど)を介して通信します。
一方、モノリシックアプリケーションでは、 すべてのビジネス ロジック、プレゼンテーション層、およびデータ アクセスは、単一のデプロイメント ブロックにパッケージ化されます。あらゆる変更には、システム全体の再コンパイル、テスト、および展開が必要となり、進化が複雑化し、本番環境にエラーが導入されるリスクが増大します。
マイクロサービスでは、各サービスには独自のライフサイクルがあります。 独立して開発、テスト、展開、スケーリング、バージョン管理を行うことができます。これにより、複数のチームが並行して作業できるようになり、新しいテクノロジーの導入が簡素化され、CI/CD プラクティスとの統合が容易になります。
さらに、このアーキテクチャでは、 コンポーネントに依存しないスケーラビリティ特定のモジュールの負荷をさらにサポートするためにモノリシック アプリケーション全体をスケーリングするのではなく、本当に必要なマイクロサービスのみがスケーリングされ、インフラストラクチャ リソースがより適切に最適化されます。
マイクロサービスの本当の利点と課題
マイクロサービスへの移行は単なる流行ではありません。 スケーラビリティ、復元力、展開速度において具体的なメリットをもたらします。しかし、これにより管理しなければならない運用上の複雑さも生じます。
最も注目すべき利点は、 各サービスの独立したスケーラビリティたとえば、支払いモジュールが管理モジュールよりも多くのトラフィックを受信する場合、アプリケーションの残りの部分に影響を与えたりリソースを無駄にしたりせずに、支払いマイクロサービスのレプリカのみを増やすことができます。
また、多くのことが得られます 継続的なデプロイメントと頻繁な配信各サービスを分離することで、アプリケーション全体を停止したり再デプロイしたりすることなく、新しいバージョンを段階的にリリースすることができ、メンテナンス期間が短縮され、市場投入までの時間が短縮されます。
もう一つのキーポイントは、 回復力とフォールトトレランス適切に設計されていれば、1つのマイクロサービスの障害がシステム全体のダウンを引き起こすことはありません。タイムアウト、再試行、サーキットブレーカーなどのパターンを活用することで、他のサービスは応答を継続し、障害の影響を最小限に抑えることができます。
さらに、マイクロサービスにより 技術的な柔軟性各チームは、通信契約とプラットフォームのグローバル ポリシーを尊重する限り、自社のサービスに最も適した言語、フレームワーク、またはデータベースを選択できます。
コインの裏側には 運用と観測の複雑さ数十または数百のサービスを管理するには、分散ネットワーク、サービス間トレース、集中ログ、セキュリティ、API のバージョン管理、データの一貫性に対処する必要があり、高度なツールと成熟したプロセスが必要です。
複雑になる サービス間の通信の管理データの交換方法、障害の処理方法、レイテンシの管理方法、そして低速な依存関係がシステムの他の部分に悪影響を与えないようにする方法を慎重に設計することが不可欠です。テストとデバッグはもはや容易ではありません。なぜなら、 テストされるのは単一のブロックではなく、相互接続されたサービスのセットです。.
コンテナ: マイクロサービスを分離して実行するための基盤
コンテナ技術はマイクロサービスにとって理想的なサポートとなっている。 アプリケーションとそのすべての依存関係を標準化された移植可能なユニットにパッケージ化できます。各サーバーにライブラリ、ランタイム、ツールをインストールする代わりに、すべてがコンテナ内で移動します。
コンテナとは、本質的には 軽量なオペレーティングシステムレベルの仮想化: ホストカーネルを共有しますが、プロセスは分離された名前空間で実行され、リソースは cgroup によって制限されるため、起動が速く、仮想マシンよりも消費量が少なくなります。
その主な特性としては、 断熱性、携帯性、軽量性、モジュール性独自のコンテナで実行される各マイクロサービスは、分散アーキテクチャの原則に完全に適合し、デプロイ、停止、更新、複製が容易になります。
と比較すると 実稼働用の仮想マシンコンテナ インスタンスごとに完全なオペレーティング システムは必要ありません。ホストの共有ではなく、画像のサイズを大幅に削減します。 時間 de ブーツ数秒でコンテナを持ち上げたり破壊したりすることができます。
Docker: マイクロサービスをコンテナ化するためのリファレンスプラットフォーム
Dockerはコンテナを扱うための最も人気のあるツールです。 コンテナ化されたアプリケーションの作成、パッケージ化、配布、実行を容易にします。 開発環境、テスト、本番環境の両方で使用できます。
彼らの中心的なアイデアは、ソフトウェアをパッケージ化することです Dockerイメージこれらは、アプリケーションコード、必要なライブラリ、システムツール、基本設定を含む不変のアーティファクトです。アプリケーションはこれらのイメージから作成されます。 稼働中のコンテナ、そのイメージに基づく分離されたインスタンスです。
画像構築は次のように定義されます ドッカーファイルベースイメージ、作業ディレクトリ、コピーするファイル、インストールする依存関係、公開するポート、コンテナの起動時に実行するコマンドなどの指示を指定するテキスト ファイルです。
Node.jsで書かれたAPIがあるとします。次のようなDockerfileを作成できます。 公式の Node イメージから開始して、ファイルがコピーされ、依存関係がインストールされ、ブート コマンドが定義されます。:
FROM node:14
WORKDIR /app
COPY . .
RUN npm install
EXPOSE 3000
CMD
このファイルは、アプリケーションがディレクトリ内で実行されることを示します。 コンテナ内の/app依存関係はnpmでインストールされ、ポート3000が公開され、コンテナを起動すると、 npmスタート.
そのコンテナをビルドして起動するには、プロジェクト フォルダーからコマンドを実行するだけです。 Dockerビルド その後 ドッカーランホストからのアクセスを許可するポートをマッピングするか、マルチコンテナアプリケーションの場合は ドッカーの作成:
docker build -t mi-app .
docker run -p 3000:3000 mi-app
このモデルのおかげで、 典型的な「私のマシンでは動作する」という問題は最小限に抑えられます。ランタイム環境はアプリケーションと共に移動するためです。さらに、DockerはCI/CDシステム、プライベートレジストリ、Kubernetesなどのオーケストレーションツールとシームレスに統合されます。
Dockerの主要コンポーネントとマイクロサービスにおけるその役割
典型的な展開では、 ドッカーホストこれは Docker がインストールされているシステム (物理または仮想) であり、その上で実行されます。 ドッカーエンジンイメージ、ネットワーク、ボリューム、コンテナのライフサイクルを管理するデーモン。
コンテナには、 アプリケーションとその依存関係をイメージにパッケージ化したものこれにより、Docker を導入したあらゆるサーバーで、そのイメージを一貫して実行できるようになります。この一貫性は、開発環境、QA 環境、本番環境など、さまざまな環境に多数のマイクロサービスをデプロイしている場合に非常に重要です。
Dockerの最も興味深い利点は、 環境間の移植性、デプロイメントの自動化、プロセスのモジュール化、イメージ内の階層化とバージョン管理のサポートこれにより、変更を元に戻し、最適化することが容易になります。 ストレージ.
Kubernetes: 数百のコンテナを管理するオーケストレーター
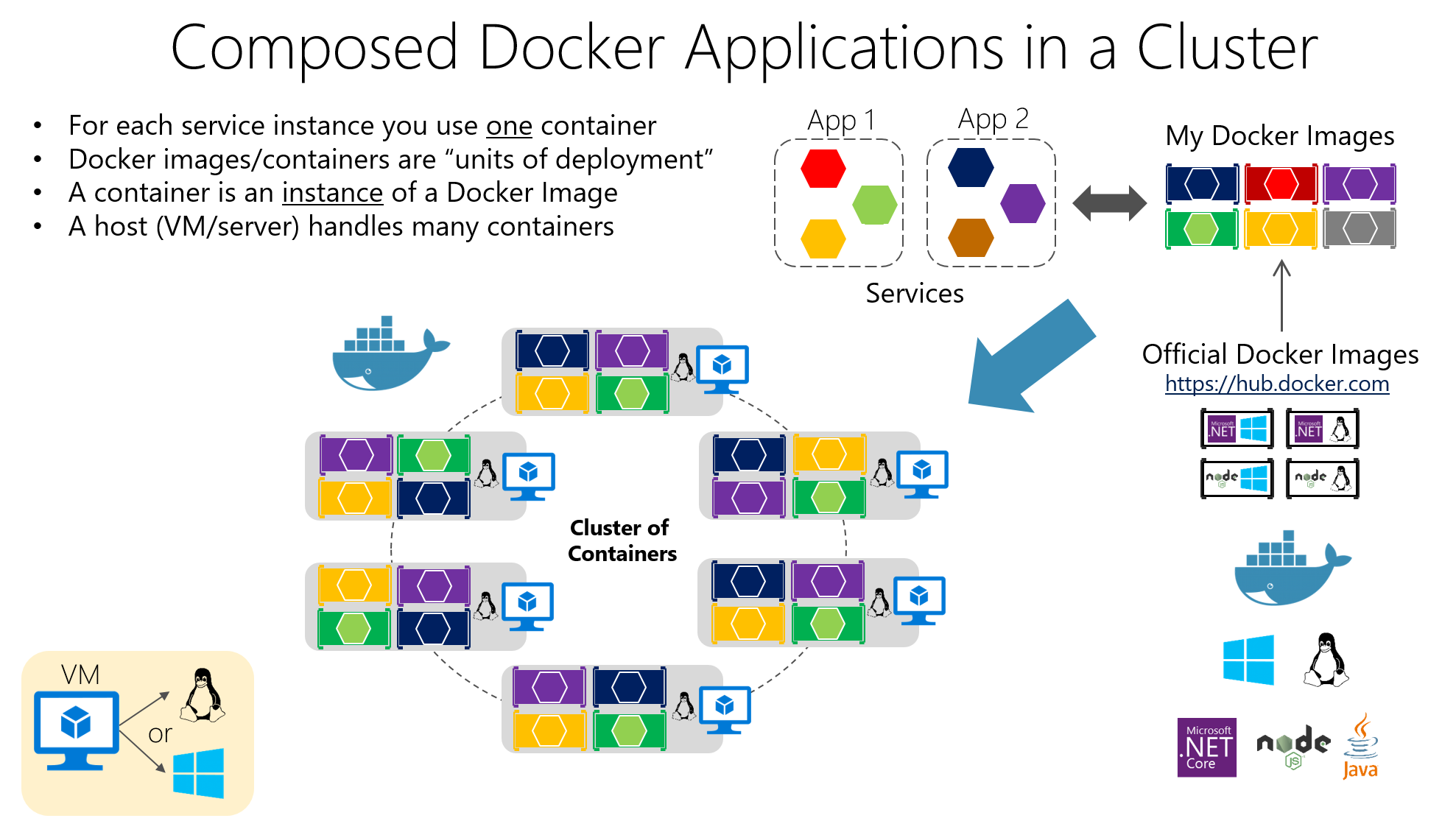
コンテナが数個から数十個、数百個に増えると、 手動で管理するのは大変ここで、大規模なコンテナをオーケストレーションするために設計されたオープンソース プラットフォームである Kubernetes が登場します。
Kubernetesは次のような重要なタスクを自動化します。 展開、スケーリング、障害回復、ネットワーク構成、ストレージ コンテナ化されたアプリケーションの。パブリッククラウド、プライベートクラウド、ハイブリッド環境、さらにはオンプレミスでも動作するように設計されています。
コンテナが実行される複数のノード(マシン)で構成されるクラスタの管理に重点を置いています。目標は、 アプリケーションは常に望ましい状態にあります: レプリカの数、デプロイされたバージョン、割り当てられたリソース、およびサービス間の接続。
Kubernetesの基本要素
Kubernetesの最小単位は ポッドポッドは、一緒に実行する必要がある1つ以上のコンテナインスタンスを表します(例:アプリケーションコンテナとログ用のサイドカーコンテナ)。ポッドは一時的なものです。 それらはクラスターのニーズに応じて作成、破棄、置き換えられます.
ポッドを公開するためにKubernetesはリソースを提供します サービスこれはネットワーク抽象化レイヤーとして機能します。サービスはポッドのセットをグループ化し、 安定した IP アドレス、DNS 名、内部負荷分散を提供します。顧客が各ポッドの詳細を知る必要がないようにするためです。
リソース 展開 これは、ポッドのデプロイと更新方法(レプリカの数、使用するイメージ、適用するタグ、従う更新戦略など)を定義するために使用されます。Kubernetes がこれを処理します。 常に必要な数のポッドを実行し続ける 構成を変更するときにローリング アップデートまたはロールバックを実行します。
次のようなリソースもあります ConfigMapとシークレットこれらの機能により、設定を外部化し、機密データ(パスワード、トークン、APIキーなど)をイメージ内にパッケージ化することなく保存できます。これにより、異なる環境間での安全な設定管理が大幅に簡素化されます。
Kubernetesクラスターを構成する方法
クラスターの「ヘッド」は Kubernetes コントロールプランこれは、システム全体を調整する役割を担う複数のコンポーネントをまとめたものです。その中には APIサーバーこれはクラスターを管理するためのゲートウェイであり、すべてのアクション (デプロイメントの作成、ポッドの一覧表示、サービスの変更) はこの API を経由します。
El スケジューラ 利用可能なリソース、親和性、制約を考慮して、各ポッドがどのノードで実行されるかを決定する役割を担います。 コントローラーマネージャー クラスターのステータスを監視し、マニフェストで指定した内容が実際と一致するようにアクションを実行します (たとえば、要求した数よりも少ない場合は新しいポッドを作成します)。
状態保存は委任される etcd分散データベースには、クラスターのすべてのリソースの構成と情報が保存されます。さらに、各ワーカーノードでは次のようなプロセスが実行されます。 キューブレット (ノードとAPIサーバーを通信するエージェント)、 キューブプロキシ (ネットワークトラフィックと負荷分散を管理する)と コンテナランタイム (Docker、containerd、CRI-O など)。
YAML ファイルを使用して Kubernetes にマイクロサービスをデプロイする
Kubernetesでマイクロサービスをデプロイするには、次のように記述するのが一般的です。 YAMLマニフェストここで、デプロイメント (ポッド テンプレート、イメージ、ポート、レプリカの数、ラベル) と、それをクラスターの内部または外部に公開するための対応するサービスを定義します。
「my-app」というアプリケーションのデプロイメントの基本的な例は次のようになります。 3つのレプリカとポート3000が定義されています コンテナポートとして:
apiVersion: apps/v1
kind: Deployment
metadata:
name: mi-app
spec:
replicas: 3
selector:
matchLabels:
app: mi-app
template:
metadata:
labels:
app: mi-app
spec:
containers:
- name: mi-app
image: mi-app:latest
ports:
- containerPort: 3000
この宣言は、クラスターが維持しなければならないことを示しています 3つのポッドが稼働中 「my-app:latest」というイメージでは、すべてのポッドにapp=my-appというタグが付けられているため、Serviceはそれらを見つけてトラフィックを分散できます。Kubernetesは、スケーリング、アップデート、そして障害発生時のポッドの置き換えといったロジックを自動的に処理します。
デプロイメントに加えて、次のようなタイプのサービスを定義するのが一般的です。 ClusterIP、NodePort、またはLoadBalancerマイクロサービスがクラスター内からのみアクセス可能か、ノードからアクセス可能か、インターネットからアクセス可能かに応じて、この構成はすべてリポジトリでバージョン管理され、CI/CD パイプラインとシームレスに統合されます。
Kubernetes におけるスケーリング、アップグレード、自己修復
Kubernetesを使用する大きな理由の1つは、 アプリケーションを停止せずにマイクロサービスを拡張および更新するマニフェスト (または kubectl コマンド) でレプリカの数を変更すると、クラスターは目的の値に達するまでポッドの作成または削除を処理します。
このスケーリングは、次のようなリソースを使用して手動でも自動でも行うことができます。 水平ポッドオートスケーラー (HPA)この機能は、CPUやメモリなどのメトリックに基づいてレプリカを動的に調整します。これにより、需要が高い時期には容量が増加し、負荷が減少するとリソースが解放されます。
アップデートに関しては、Kubernetesは ローリングアップデート デフォルトでは、新しいバージョンのPodを作成し、以前のバージョンのPodを段階的に削除します。突然の削除は行われません。何か問題が発生した場合、 ロールバック 以前のバージョンをすぐに復元できます。
もう一つの重要な機能は 自己修復コンテナまたはポッドが停止した場合、Kubernetes はそれを自動的に再作成します。ノードが応答を停止した場合、影響を受けるポッドは他の利用可能なノードに再スケジュールされ、アプリケーションの稼働が維持されます。
Kubernetes におけるマイクロサービスの監視と可観測性
マイクロサービス環境を正しく運用するには、単にデプロイしてスケーリングするだけでは不十分です。 サービスのパフォーマンスとステータスをリアルタイムで把握する必要があるKubernetes では、メトリクスを収集するための Prometheus や、それらを視覚化するための Grafana などのツールを統合することが非常に一般的です。
Prometheusはポッド、ノード、クラスタコンポーネントからメトリクスを「スクレイピング」し、保存して、それらに関するアラートを定義できるようにします。Grafanaと組み合わせることで、ダッシュボードを作成できます。 CPU 使用率、メモリ、HTTP エラー、レイテンシ、レプリカ数、ノード ステータスを監視します。 非常にはっきりと。
さらに、kubectlは コマンド デプロイメント、サービス、ポッド、その他のリソースのステータスを確認するには、 ログこれには、イベントの記述やデバッグのためのコンテナへのアクセスが含まれます。これらはすべて、マイクロサービスにおける可観測性戦略の一部です。 安らかに眠りたいなら、それは必須です。.
マイクロサービス、Docker、Kubernetesの関係
マイクロサービス、Docker、Kubernetes は、同じパズルのピースのように組み合わさります。 マイクロサービス アーキテクチャはアプリケーションの設計方法を定義し、Docker は各サービスのパッケージ化と実行を処理し、Kubernetes はそれらすべてのコンテナーを調整します。 クラスター内。
各マイクロサービスは、 コードと依存関係を含むDockerイメージこれにより、開発者のラップトップ、テスト環境、クラウド本番環境のいずれにおいても、同じ動作が保証されます。この一貫したパッケージングは、DevOpsの理念にとって不可欠です。
Kubernetesは、 コンテナオーケストレーター各マイクロサービスのインスタンスをいくつ実行するか、どこに配置するか、インスタンスへのトラフィックをどのように分散するか、インスタンスが障害からどのように回復するか、需要が増加または減少したときにどのようにスケーリングするかを決定します。
例えば、eコマースアプリケーションでは、認証、カタログ、ショッピングカート、決済といったマイクロサービスがそれぞれ独自のDockerイメージとKubernetesデプロイメントで構成されている可能性があります。このようにして、 重要な時期に大規模なキャンペーンや支払いでカタログを拡大しても、他の部分に影響を与えることはありません。CI/CD パイプラインからポストプロダクション監視までのライフサイクル全体を調整します。
Windows に Docker と Kubernetes をインストールする
Windowsで作業する場合、最も簡単な方法はインストールすることです Dockerデスクトップこれには、Docker エンジンと追加のツール、さらにはマシンに統合された Kubernetes を有効にするオプションも含まれています。
典型的なプロセスは 公式サイトからDocker Desktopをダウンロードするインストーラ(Docker Desktop Installer.exe)を実行し、ウィザードに従ってください。インストール中に、Hyper-Vを使用するか、 WSL 2 仮想化テクノロジーとして、利用可能なものが 1 つしかない場合は、それが使用されます。
システムの再起動後、Docker Desktopを開くとコンテナ環境が初期化されます。仮想化が有効になっていない場合は、インストーラ自体が通常、 自動的に有効にするそこから、Nginx や独自のアプリケーションなどのコンテナを起動できます。
WindowsでKubernetesを使用するには、まずDockerと仮想化機能を有効にする必要があります。その後、Docker Desktopまたは kubectlをインストールして設定する 外部クラスターを管理し、必要に応じてリモート マニフェストを介して Kubernetes ダッシュボードをデプロイします。
設定が完了すると、kubectl で生成され、たとえば設定ファイルを指す認証トークンを使用して、ローカル プロキシ経由でダッシュボードにアクセスできるようになります。 .kube/config ブラウザからクラスターへのアクセスを管理します。
LinuxにDockerとKubernetesをインストールする
Ubuntu などの Linux システムでは、Docker のインストールは通常非常に簡単です。 パッケージが更新され、Docker エンジンがインストールされ、環境が正しく動作しているかどうかがチェックされます。 テストコンテナを実行しています。
典型的な手順としては、システムの更新が含まれます。 apt-get update と apt-get upgrade以前のバージョンの Docker Desktop がある場合は削除し、公式リポジトリから、または必要なバージョンを指定して、docker-ce、docker-ce-cli、containerd.io、および docker-compose プラグインをインストールします。
すべてが正常であることを確認するために、通常は「hello-world」コンテナが起動されます。 最小限のイメージをダウンロードして実行します。メッセージが正しく表示されたら、Docker が起動して実行されており、マイクロサービスのコンテナ化を開始する準備ができています。
Kubernetesに関しては、Linuxでは次のようなツールを使用してインストールできます。 クビーズ一般的なワークフローには、Kubernetes リポジトリ キーの追加、パッケージ リスト ファイルの構成、kubeadm のインストール、バージョンの確認が含まれます。
クラスタはマスターノード上で初期化され、 kubeadm 初期化 (ポッドのネットワーク範囲を指定)、「join」コマンドが取得され、ワーカーノードがクラスターに参加し、ディレクトリを作成してローカルアクセスが設定されます。 $HOME/.kubeadmin.conf ファイルをコピーし、権限を調整します。
これで、基本的なクラスターの準備が整います。 コンテナ化されたマイクロサービスをデプロイする、ポッドのネットワーク (Flannel、Calico など) をインストールし、デプロイメント、サービス、およびその他の Kubernetes リソースの操作を開始します。
DockerとKubernetesの使用に関するベストプラクティスと推奨事項
これらの環境を最大限に活用するには、Dockerの一連のベストプラクティスに従うことをお勧めします。 公式または信頼できる画像を使用するセキュリティ リスクを軽減するために、Docker Hub または検証済みのプライベート リポジトリからインストールします。
強くお勧めします 画像サイズを最適化する 軽量ベースイメージ、多段階ビルド、削除の使用 一時ファイル 不要なアーティファクトが含まれません。イメージが小さいほどダウンロードが速くなり、Kubernetes へのデプロイが高速化されます。
もう一つの重要なポイントは データ永続性のためのボリュームコンテナ内に情報を保存するのではなく、コンテナが失われたり再作成されたりしても重要なデータが失われることはありません。
各コンテナに割り当てられるリソース(CPU、メモリ、I/O)を制限すると、 単一のサービスがホストを独占するのを防ぐ そして、残りの部分を劣化させます。さらに、本番環境でコンテナを制御するには、Docker Statsなどのツールやより高度なソリューションを使用してコンテナを監視する必要があります。
Kubernetesでは、本番環境に移行する前に、クラスタのアーキテクチャとそのコンポーネントを理解することが不可欠です。これにより、多くの問題が軽減されます。
それも良い考えです 可能な限り自動化するレプリケーション コントローラー、オートスケーラー、ジョブを使用してバッチ アップロードを実行し、ローリング アップデートとロールバックを活用し、Git リポジトリでバージョン管理された宣言型マニフェストを定義します。
安全は常に最優先事項です。 API サーバーへのアクセスを制限し、シークレットを使用して資格情報を管理し、転送中および保存中のデータを暗号化します。定期的にパッチを適用し、最小権限の原則に従ってサービス間の通信を制限するネットワーク ポリシーを定義します。
最後に、 優れた集中監視およびログ記録システムまた、変更を本番環境クラスターに導入する前に徹底的にテストできる本番前環境も備えているため、リスクや予期せぬ事態が軽減されます。
マイクロサービス、Dockerコンテナ、Kubernetesオーケストレーションからなるこのエコシステム全体により、従来のモノリスよりもはるかに柔軟でスケーラブル、そして回復力に優れたシステムを構築できます。綿密に検討されたアーキテクチャ、適切なツール、そしてDevOpsのベストプラクティスを組み合わせることで、ワークロードの変化にシームレスに適応し、障害から迅速に回復し、時間の経過とともに容易に進化できるアプリケーションをデプロイできます。

バイトの世界とテクノロジー全般についての情熱的なライター。私は執筆を通じて自分の知識を共有するのが大好きです。このブログでは、ガジェット、ソフトウェア、ハードウェア、技術トレンドなどについて最も興味深いことをすべて紹介します。私の目標は、シンプルで楽しい方法でデジタル世界をナビゲートできるよう支援することです。