- gdbserver agisce come agente remoto di GDB per controllare i processi su un'altra macchina tramite TCP o seriale.
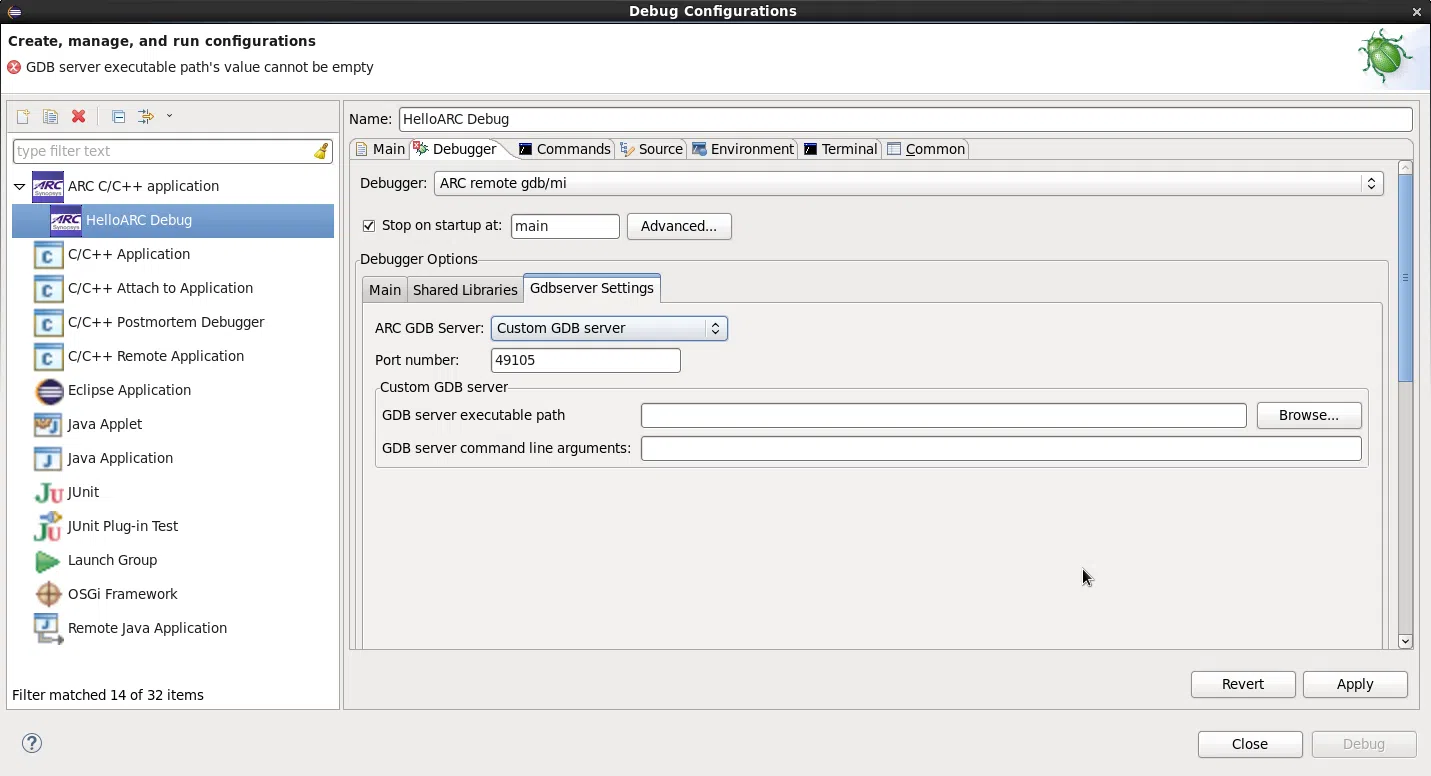
- Per eseguire il debug in remoto, è fondamentale compilare con SimboliUtilizzare il gdb appropriato e configurare correttamente i percorsi dei simboli e dei font.
- gdbserver offre la modalità a processo singolo e la modalità multiprocesso, integrandosi anche con WinDbg e QEMU per il debug del kernel.
- Opzioni come --debug, sysroot e limiti di dimensione del valore aiutano a diagnosticare i problemi e a stabilizzare le sessioni.
Se programmi in C o C++ in Linux e non hai mai toccato gdbserverTi stai perdendo uno degli strumenti più utili per il debug dei processi da remoto, che sia su un server, un sistema embedded o persino all'interno di una macchina virtuale o WSL. Lungi dall'essere qualcosa di "magico" o riservato agli esperti, gdbserver è semplicemente un piccolo programma che comunica con gdb e controlla l'esecuzione del processo di destinazione.
L'idea chiave è molto semplice.: sulla macchina in cui è in esecuzione il binario di cui si desidera eseguire il debug (il bersaglio) avvii gdbserver; sul tuo computer di lavoro (il hostSi avvia gdb o anche WinDbg con il supporto per il protocollo gdb. Entrambi si connettono tramite TCP o una porta seriale, e da lì è possibile impostare punti di interruzione, ispezionare le variabili, visualizzare lo stack o seguire l'esecuzione passo dopo passo come se il programma fosse in esecuzione sulla propria macchina.
Che cos'è gdbserver e quando ha senso utilizzarlo?
gdbserver è un "agente" di debug remoto per GNU gdbLa sua funzione è molto specifica: viene eseguito sulla macchina in cui è in esecuzione il programma da analizzare, controlla quel processo (o quei processi) e comunica con un client gdb situato su un'altra macchina (o sulla stessa) tramite una connessione remota.
Nell'uso quotidiano, gdbserver viene utilizzato in due scenari tipiciSoftware di debug che funziona in ambienti embedded (router, schede con Linux ridotto, dispositivi) IoTecc.) e processi di debug su macchine Linux remote, dove non è conveniente o semplicemente non è possibile avere un gdb "grasso" con tutte le librerie e i simboli.
A livello pratico, gdbserver gestisce attività come Leggere e scrivere registri e memoria di processo, controllare l'esecuzione (continua, pausa, passaggio successivo), gestire i breakpoint e inviare tutti questi dati a gdb utilizzando il protocollo remoto GDB. Questa filosofia è molto simile a quella di strumenti come OpenOCD, che fungono da ponte tra gdb e un hardware esterno, con la differenza che gdbserver viene eseguito sullo stesso sistema in cui viene eseguito il binario.
Se provieni da ambienti Windows È anche interessante sapere I debugger come WinDbg possono comunicare con un gdbserver su Linux, quindi è possibile eseguire il debug dei processi utente su Linux da WinDbg utilizzando il supporto di debug remoto tramite il protocollo gdb che Microsoft ha incorporato nelle versioni recenti.
Requisiti di base per il debug con gdb e gdbserver
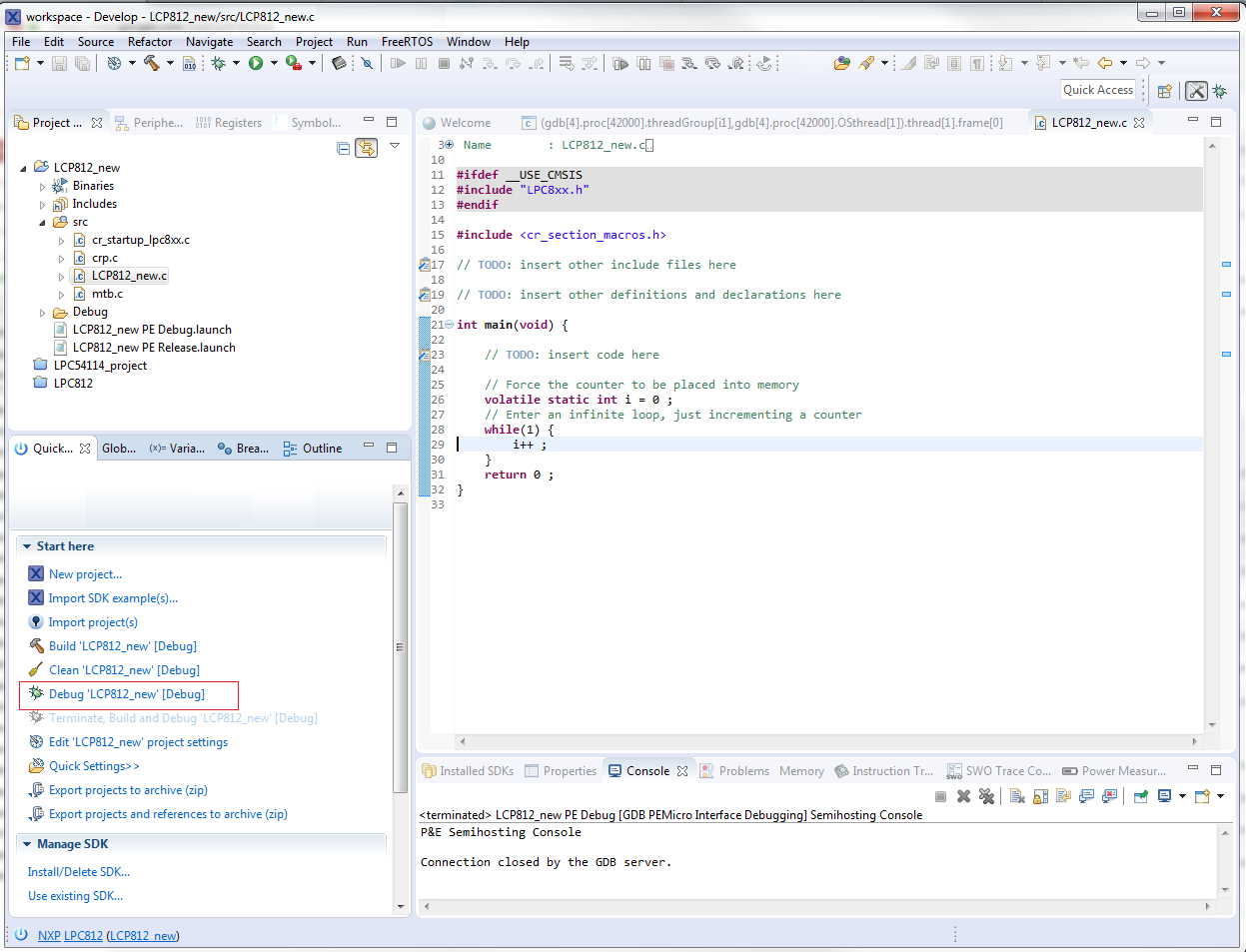
Prima di iniziare il debug in remoto, è necessario comprendere la relazione host/destinazione.. Il bersaglio È la macchina su cui viene eseguito il programma da sottoporre a debug e su cui verrà eseguito gdbserver; host Questa è la macchina da cui eseguirai gdb (o WinDbg) e dove avrai il codice sorgente e, preferibilmente, i simboli di debug.
Il punto di partenza essenziale è compilare il binario con i simboliIn GCC o g++ questo si ottiene con il flag -ge di solito è consigliabile disattivare anche le ottimizzazioni (ad esempio con -O0Ciò consente al debugger di visualizzare con maggiore precisione variabili, macro e struttura del codice. Per macro specifiche, è possibile utilizzare livelli di debug più elevati, ad esempio -g3.
Sul lato host avrai bisogno di una versione compatibile di gdb con l'architettura di destinazione. Per eseguire il debug di un sistema embedded MIPS, ARM o di altra architettura, è necessario utilizzare il gdb della cross-toolchain corrispondente (ad esempio) arm-none-eabi-gdb o gdb-multiarch) e, se necessario, configurare l'architettura e l'endianness con comandi come set arch y set endian.
Per quanto riguarda la connessione, gdbserver supporta due tipi principaliUn collegamento seriale (molto comune nell'hardware embedded, tramite UART) e TCP/IP, più comodo quando il target si trova sulla stessa rete o è una macchina Linux accessibile tramite rete. In entrambi i casi, il comando viene utilizzato da gdb. target remote per connettersi all'endpoint esposto da gdbserver.
Modalità di avvio di gdbserver: modalità a processo singolo e multiprocesso
gdbserver può funzionare in due modi principali Quando parliamo di debug in modalità utente: associato direttamente a un singolo processo o come "server di processo" che consente l'elenco e l'associazione a diversi processi di sistema.
In modalità a processo singolo Avvia gdbserver, specificando host:porta e il programma da eseguire. In un semplice esempio su un computer desktop Linux, potresti fare qualcosa del genere:
comando: gdbserver localhost:3333 foo
Con questo comando, gdbserver avvia il binario. foo e rimane in ascolto sulla porta 3333Finché un gdb remoto non si connette, il programma rimane arrestato; quando gdb si connette con target remote localhost:3333, il processo inizia ad essere controllato dal descrusher.
In modalità multiprocesso (process server) viene utilizzata l'opzione --multiIn questo caso, gdbserver non avvia direttamente alcun programma, ma semplicemente ascolta le connessioni in arrivo e consente al client (gdb o WinDbg) di gestire quale processo creare o a cui collegarsi:
comando: gdbserver --multi localhost:1234
Quando si lavora con WinDbg su Linux, questa modalità multipla risulta particolarmente interessante.Poiché da WinDbg stesso è possibile elencare i processi sul sistema remoto, vedere PID, utente e riga di comando e collegarsi a quello a cui si è interessati, in modo simile a come viene fatto con il server di processo dbgsrv.exe e Windows.
Debug remoto con gdbserver e gdb passo dopo passo
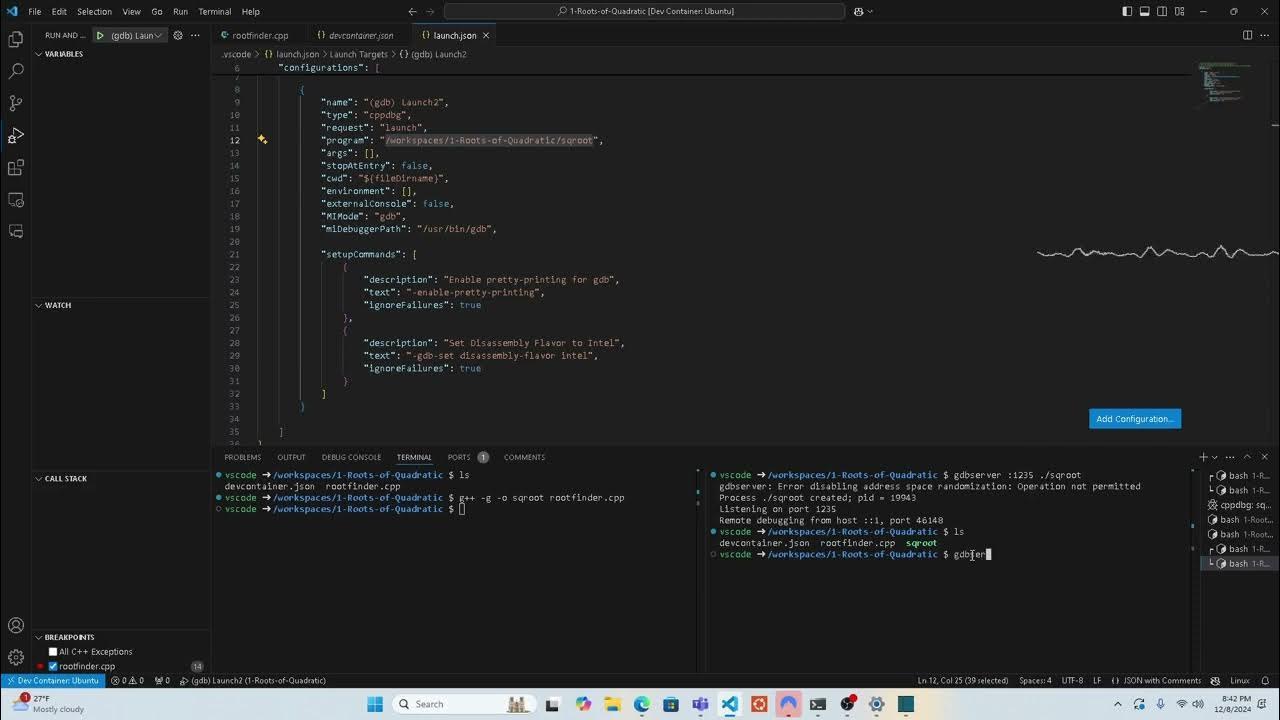
Facciamo un esempio molto tipico.: Esegui il debug di una semplice applicazione sulla stessa macchina (host e destinazione corrispondono) utilizzando gdbserver per simulare lo scenario remoto.
Per prima cosa scrivi e compili un piccolo programmaAd esempio, un ciclo assurdo che stampa un contatore:
comando: gcc -g foo.c -o foo
La chiave qui è la bandiera -gCiò aggiunge le informazioni di debug necessarie al binario in modo che gdb possa visualizzare righe di codice, nomi di variabili, tipi, ecc. In un ambiente di cross-compilazione "reale", questa compilazione verrebbe eseguita con la cross-toolchain e quindi si copierebbero sia il binario che le sue dipendenze nella destinazione.
Il passo successivo è avviare gdbserver sul targetSe host e target sono la stessa macchina, allora:
comando: gdbserver localhost:3333 foo
Vedrai un messaggio simile a "Processo foo creato; pid = XXXX; In ascolto sulla porta 3333". Questo indica che gdbserver ha creato il processo ed è in attesa della connessione di gdb. Se ci si trova su un sistema in cui sono richiesti più privilegi (ad esempio, per connettersi ai processi di sistema), potrebbe essere necessario eseguire il comando con sudoMa è sempre saggio essere cauti quando si concede un permesso. radice al desolforatore.
Sull'host, si avvia gdb specificando l'eseguibile locale (lo stesso in esecuzione sul target o una copia identica con simboli):
comando: gdb foo
Una volta dentro gdb, stabilisci la connessione remota con:
comando: target remote localhost:3333
A quel punto, gdb carica i simboli dal binario locale.Si sincronizza con gdbserver e prende il controllo del processo effettivamente in esecuzione su gdbserver. Da lì, il flusso è quello consueto: comandi come break per stabilire punti di rottura, continue, step, next, print per ispezionare le variabili, backtrace per vedere la batteria, ecc.
Connessione ai processi in esecuzione con gdbserver
Non sempre è opportuno avviare il programma da zero.Spesso sei interessato a partecipare a un processo già in esecuzione (ad esempio, un httpd di un routerun demone di sistema o un servizio di produzione).
Il modello tipico è quello di utilizzare l'opzione --attach da gdbserverpassando la porta su cui ascolterà e il PID del processo di destinazione. Ad esempio, su un router in cui è stato copiato un gdbserver compilato per la sua architettura, è possibile eseguire:
comando: gdbserver localhost:3333 --attach <pid_de_httpd>
Sul lato host, utilizzerai una versione di gdb che supporta l'architettura del router., per esempio gdb-multiarchconfigurare in anticipo l'architettura e l'endianness:
comando: set arch mips
set endian big
Quindi si specifica il file locale che contiene i simboli. del binario remoto (ad esempio file httpd) e, se necessario, dici a gdb dove il binario è effettivamente in esecuzione sul target con set remote exec-file /usr/bin/httpdInfine, proprio come prima, ti connetti con:
comando: target remote 192.168.0.1:3333
Una volta attaccatoÈ possibile impostare punti di interruzione su funzioni specifiche (ad esempio break checkFirmware), continuare l'esecuzione e lasciare che il normale flusso del programma (ad esempio, il caricamento del firmware dall'interfaccia web) attivi il punto di interruzione.
Utilizzo di gdbserver con WinDbg su Linux
Negli ultimi anni Microsoft ha aggiunto il supporto per il debug dei processi Linux in WinDbg Utilizzo di gdbserver come backend. Questa funzionalità è pensata per scenari in cui si lavora su Windows ma il codice viene eseguito su Linux (incluso WSL).
Per eseguire il debug di un processo Linux specifico con WinDbg utilizzando gdbserverIl flusso sarebbe più o meno questo: prima si individua il processo di destinazione sulla macchina Linux con un comando come ps -A (ad esempio un python3 che è in esecuzione), quindi avvia gdbserver sulla destinazione:
comando: gdbserver localhost:1234 python3
Se l'ambiente lo richiede, potrebbe essere necessario utilizzare sudo gdbserver ...con le stesse precauzioni di sicurezza di sempre. Una volta che gdbserver indica di essere "In ascolto sulla porta 1234", in WinDbg vai su "File / Connetti al debugger remoto" e specifica una stringa di connessione del tipo seguente:
comando: gdb:server=localhost,port=1234
WinDbg utilizza un piccolo "driver" del protocollo gdb per comunicare con gdbserver e, una volta stabilita la connessione, rimane fermo nel punto di Boot del processo. Da lì puoi usare le sue finestre di stack, i moduli, la memoria, i punti di interruzione, così come comandi come k per vedere la batteria o lm per elencare i moduli (tenendo presente che alcuni comandi si aspettano il formato PE e non ELF, quindi in alcuni casi potrebbero visualizzare dati strani).
gdbserver e server di processo WinDbg
Oltre al caso di processo singolo, WinDbg può connettersi a un gdbserver che funge da server di processo per funzionare in modo più simile a come funziona con i processi Windows remoti. In questa modalità, gdbserver viene avviato con --multi e senza un processo associato:
comando: sudo gdbserver --multi localhost:1234
Da WinDbg, seleziona "File / Connetti al server di processo" e riutilizzi la stringa di connessione gdb:server=localhost,port=1234Quando la connessione è attiva, puoi elencare i processi Linux disponibili e collegarti a quello desiderato o addirittura avviare un nuovo processo.
C'è un piccolo dettaglio da tenere a mente.WinDbg distingue tra "process server" e "single target" a seconda che gdbserver sia già collegato a un processo al momento della connessione. Se si lascia gdbserver collegato a un processo, si chiude WinDbg e poi si tenta di riconnettersi, potrebbe non essere rilevato come process server e potrebbe essere necessario riavviare gdbserver.
Per terminare una sessione dell'ufficiale giudiziarioDi solito, è sufficiente premere CTRL+D nella console in cui è in esecuzione gdbserver e interrompere il debug da WinDbg. In alcuni casi estremi, in caso di problemi di sincronizzazione, potrebbe essere necessario chiudere completamente il debugger e riavviare gdbserver da zero.
Gestione dei simboli e del codice sorgente nel debug remoto
Una delle chiavi per rendere conveniente il debug remoto è avere la parte dei simboli e dei font ben risoltaSenza simboli, spostarsi nello stack o impostare punti di interruzione su funzioni specifiche diventa una tortura.
Negli scenari classici gdb + gdbserver, è ideale conservare una copia dell'eseguibile con i simboli sull'host. (non spogliato) e l'albero sorgente. gdb non richiede che il binario remoto contenga i simboli; è sufficiente che il file locale caricato con file corrisponde all'eseguibile remoto a livello di offset.
Nel mondo del debug di WinDbg e Linux sono emersi anche servizi come DebugInfoD.che espongono simboli e font tramite HTTP. WinDbg può utilizzare percorsi speciali del tipo DebugInfoD*https://debuginfod.elfutils.org entrambi .sympath e .srcpath per scaricare on-demand i simboli DWARF e il codice sorgente dei binari Linux ELF.
In un esempio specifico con WSL, dove il codice utente è sotto C:\Users\Bob\Potresti dire a WinDbg:
comando: .sympath C:\Users\Bob\
.srcpath C:\Users\Bob\
E se vuoi usare DebugInfoD anche per i binari di sistema:
comando: .sympath+ DebugInfoD*https://debuginfod.elfutils.org
.srcpath+ DebugInfoD*https://debuginfod.elfutils.org
Con questa configurazione, quando si ispeziona lo stack o si immettono le funzioni libcWinDbg potrebbe tentare di scaricare i simboli DWARF corrispondenti e, se anche il server espone il codice, visualizzare il codice sorgente in modo notevolmente dettagliato, sebbene internamente la toolchain di Windows non gestisca ELF e DWARF in modo "nativo" come PE e PDB.
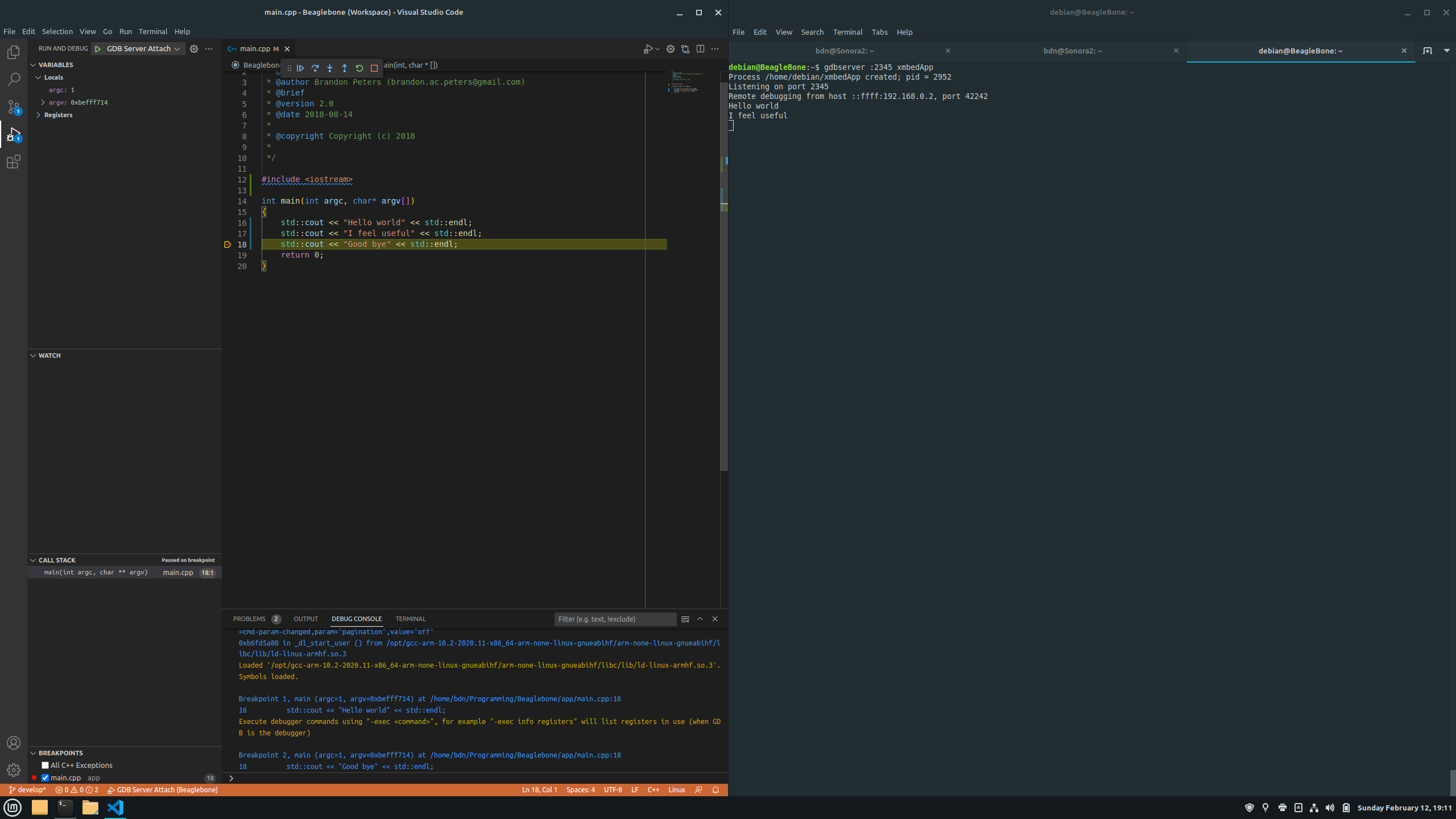
Esempio pratico: debug di un programma C++ con gdbserver e WinDbg
Un esempio illustrativo è una piccola applicazione C++ che scrive un saluto sullo schermo., compilato in WSL con simboli di debug. Immagina un programma che riserva un std::array<wchar_t, 50> e copia un messaggio più lungo al suo interno, causando il troncamento del testo e la visualizzazione dei caratteri ???? alla fine.
Dopo aver compilato con qualcosa come:
comando: g++ DisplayGreeting.cpp -g -o DisplayGreeting
Si avvia gdbserver su quel binario:
comando: gdbserver localhost:1234 DisplayGreeting
In WinDbg ti connetti con la stringa gdb:server=localhost,port=1234 E, una volta stabilita la sessione e configurati i percorsi dei simboli e dei font, si imposta un punto di interruzione in DisplayGreeting!main, Puoi usare dx greeting per ispezionare l'array locale e vederne le dimensioni (50 posizioni) e controllare visivamente nella scheda della memoria o nella vista delle variabili come viene troncato il saluto.
La bellezza di questo esempio è che dimostra che, anche senza il supporto completo per tutti i formati ELF/DWARF in WinDbgÈ possibile attraversare gli stack, ispezionare i tipi, impostare punti di interruzione in base al nome della funzione e navigare nel codice C++ in modo abbastanza agevole utilizzando gdbserver come backend remoto.
Debug del kernel Linux con qemu e gdb
gdbserver non viene utilizzato solo in modalità utente; esistono scenari molto potenti anche in modalità kernel.Soprattutto quando si combina QEMU con il supporto al debug. Sebbene in questo caso il ruolo di "gdbserver" sia svolto dall'opzione di QEMU, l'approccio è identico: un'estremità esegue il sistema da debuggare e apre una porta gdb; l'altra estremità è gdb o un debugger che parla il protocollo remoto.
Per eseguire il debug del kernel, è necessario compilarlo con opzioni di debug specifiche.: attiva la generazione di informazioni di debug (CONFIG_DEBUG_INFO), gli script del kernel GDB (CONFIG_GDB_SCRIPTS) e la modalità di debug del kernel (CONFIG_DEBUG_KERNELÈ inoltre importante disattivare le opzioni che rimuovono i simboli durante il collegamento, come "Rimuovi i simboli generati dall'assembler durante il collegamento".
Dopo la compilazione otterrai un file binario vmlinux "non spogliato"che è quello che userai da gdb. Ti servirà anche un initramfs di base, che puoi generare con un comando come:
comando: mkinitramfs -o ramdisk.img
Quindi avvii QEMU con i parametri di debugUn esempio tipico include l'opzione -gdb tcp::1234 per aprire un endpoint remoto compatibile con gdb e -S in modo che la macchina virtuale parta in pausa dall'inizio. Si specifica anche il kernel con -kernel vmlinux, la -initrd ramdisk.img, la memoria con -m 512 e di solito reindirizzi la console a ttyS0 per gestire tutto dal terminale.
Con QEMU trattenuto in attesa di gdbDalla macchina host, si avvia gdb puntando a vmlinux e ti connetti con target remote localhost:1234Da lì puoi impostare i punti di interruzione iniziali, ad esempio un hb start_kernele controllare l'esecuzione con comandi come c (continua) e CTRL+C per mettere nuovamente in pausa.
Modifiche e sfumature recenti in gdb e gdbserver
Nelle distribuzioni moderne come Red Hat Enterprise Linux 8, ci sono diverse modifiche in gdb e gdbserver che vale la pena tenere a mente.soprattutto se si proviene da versioni precedenti o si hanno script che analizzano l'output del debugger.
Da un lato, gdbserver ora avvia i processi “inferiori” utilizzando una shellProprio come gdb, questo comando consente l'espansione e la sostituzione delle variabili dalla riga di comando. Se per qualsiasi motivo fosse necessario disabilitare questa funzionalità, in RHEL 8 sono disponibili impostazioni specifiche per ripristinare la modalità precedente.
Anche diverse cose sono state rimosse o modificate: supporto al debug per programmi Java compilati con gcj, la modalità di compatibilità HP-UX XDB, comandi come set remotebaud (sostituito da set serial baud) o compatibilità con un certo formato più vecchio di stabsInoltre, la numerazione dei thread non è più globale, ma per thread "inferiore", e appare come inferior_num.thread_num, con nuove variabili di convenienza come $_gthread per fare riferimento all'identificatore globale.
Un'altra novità rilevante è la regolazione max-value-sizeQuesto limita la quantità di memoria che gdb può allocare per visualizzare il contenuto di un valore. Il valore predefinito è 64 KiB, quindi i tentativi di stampare array o strutture di grandi dimensioni potrebbero generare un avviso di "valore troppo grande" anziché visualizzare tutta la memoria disponibile.
È stato anche modificato il modo in cui gdb gestisce il sysrootIl valore predefinito è ora target:Ciò significa che per i processi remoti, tenterà prima di trovare librerie e simboli sul sistema di destinazione. Se si desidera dare priorità ai simboli locali, è necessario eseguire set sysroot con il percorso che ti interessa prima di fare target remote.
Per quanto riguarda la cronologia dei comandi, la variabile d'ambiente ora utilizzata è GDBHISTSIZE al posto di HISTSIZECiò consente di definire con precisione per quanto tempo si desidera conservare i comandi digitati nelle sessioni di debug senza interferire con il comportamento di altre applicazioni che utilizzano la libreria di lettura delle righe.
Suggerimenti sul flusso di lavoro e risoluzione dei problemi con gdbserver
Per avere un flusso di lavoro confortevole, ci sono alcuni schemi che tendono a funzionare molto bene. Quando si sviluppa per sistemi embedded o server remoti, il primo passo è automatizzare il più possibile la compilazione dei simboli e la distribuzione dei binari sul target. In questo modo, si sa sempre quale versione dell'eseguibile è in esecuzione e la copia del simbolo è prontamente disponibile sull'host.
Negli ambienti con molti core che causano crash, vale la pena imparare a usare gdb in modalità batch., con bandiere come --batch, --ex y -x per avviare automaticamente comandi su un elenco di core ed elaborare i loro backtrace dagli script (ad esempio in PythonCiò consente di filtrare rapidamente i problemi ripetuti, raggruppare gli errori in base alla traccia dello stack, ecc.
Quando qualcosa va storto con la connessione remota, l'opzione --debug gdbserver è il tuo migliore amicoSe si avvia, ad esempio, un ufficiale giudiziario con:
comando: gdbserver --debug --multi localhost:1234
La console gdbserver mostrerà tracce dettagliate di ciò che sta accadendo A livello di protocollo remoto, ciò include pacchetti in arrivo, errori di formattazione, problemi di disconnessione, ecc. Ciò è molto utile quando il server gdb si disconnette improvvisamente, un processo si blocca non appena viene impostato un punto di interruzione o la GUI di debug invia qualcosa che gdbserver non comprende.
In contesti come un router TP-Link in cui si collega gdbserver a un processo critico come httpdÈ relativamente comune che determinati breakpoint creino race condition o watchdog che interrompono il processo quando rimane "bloccato" per troppo tempo nel debugger. In queste situazioni, potrebbe essere necessario regolare quali segnali vengono bloccati, quali thread vengono controllati e, se applicabile, modificare la configurazione del sistema stesso (tempi di timeout, watchdog hardware) per consentire sessioni di debug più lunghe.
Usare bene gdbserver implica combinare diversi pezziCompila con simboli appropriati, scegli il gdb corretto per l'architettura, configura i percorsi dei simboli e delle sorgenti, comprendi le due modalità principali di gdbserver (processo singolo e multiprocesso) e non aver paura di estrarre dalla modalità --debug quando la connessione non si comporta come previsto. Con queste premesse, il debug delle applicazioni in esecuzione su un sistema Linux remoto, un router o una macchina virtuale con un kernel personalizzato dal PC diventa un'operazione piuttosto ordinaria e, soprattutto, incredibilmente utile.
Scrittore appassionato del mondo dei byte e della tecnologia in generale. Adoro condividere le mie conoscenze attraverso la scrittura, ed è quello che farò in questo blog, mostrarti tutte le cose più interessanti su gadget, software, hardware, tendenze tecnologiche e altro ancora. Il mio obiettivo è aiutarti a navigare nel mondo digitale in modo semplice e divertente.