- I microservizi consentono lo sviluppo di applicazioni modulari e scalabili, in cui ogni servizio è autonomo e distribuibile in modo indipendente.
- Docker semplifica la creazione di contenitori leggeri e portatili che impacchettano ogni microservizio con tutte le sue dipendenze.
- Kubernetes orchestra i container, gestendo la distribuzione, il ridimensionamento, il networking e il ripristino automatico dei microservizi nel cluster.
- L'applicazione di buone pratiche di sicurezza, monitoraggio e automazione è fondamentale per il corretto funzionamento dei microservizi in produzione.
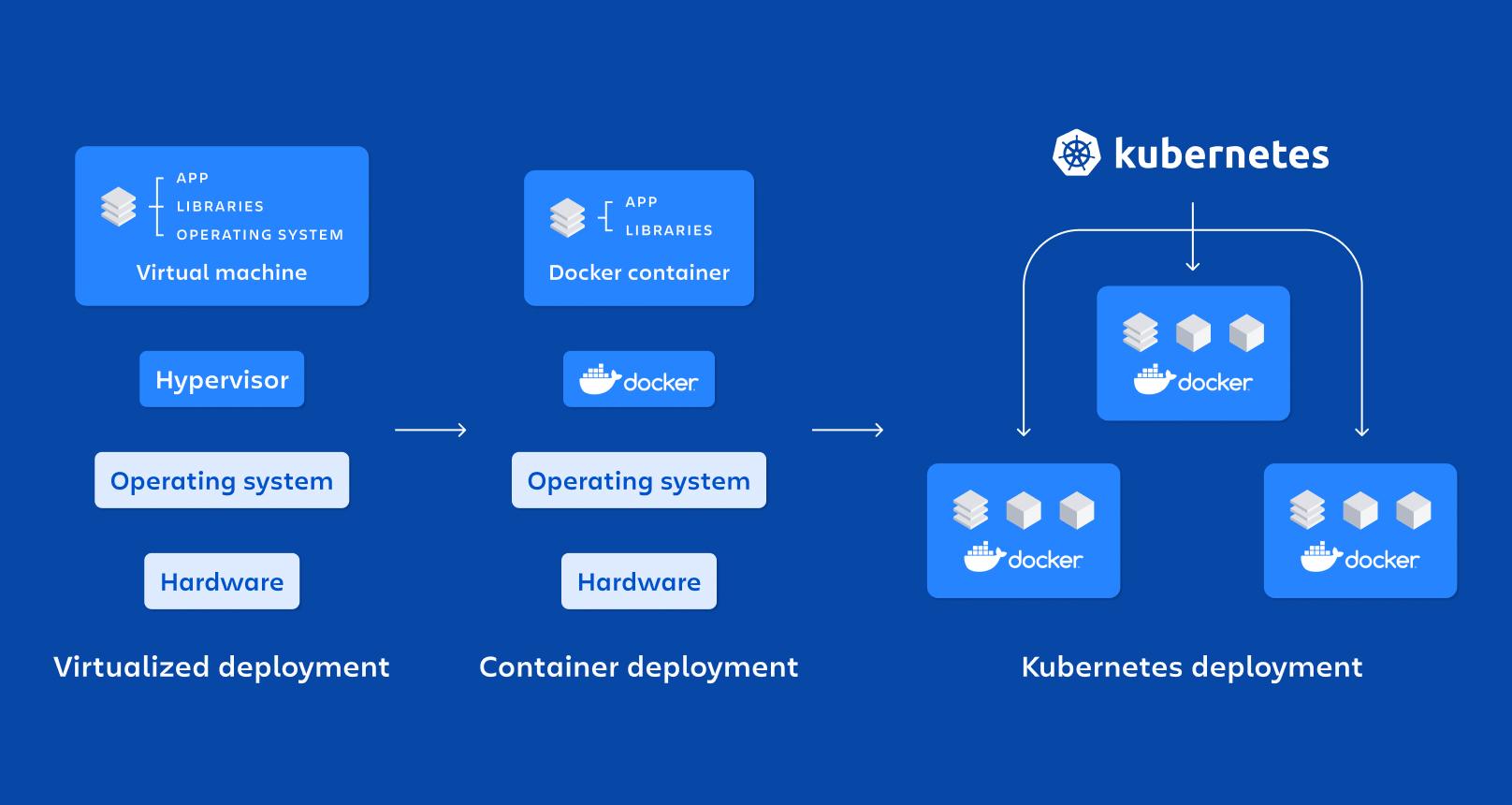
Negli ultimi anni, la combinazione di microservizi, Docker e Kubernetes È diventato lo standard de facto per l'implementazione di applicazioni moderne, scalabili e facili da gestire. Sempre più aziende stanno abbandonando le applicazioni monolitiche a favore di architetture distribuite, più adatte ad ambienti in continua evoluzione e strategie DevOps.
Se lo chiedi Come implementare i microservizi con Docker e Kubernetes nella praticaQuesto contenuto sarà perfetto per te: esamineremo i concetti chiave, i vantaggi e le sfide, come creare container, come orchestrarli in un cluster e quali passaggi seguire per installarli. Windows y Linuxoltre a una serie di suggerimenti per utilizzarli saggiamente in ambienti reali.
Cos'è un'architettura di microservizi e in cosa si differenzia da un'architettura monolitica?
Un'architettura di microservizi si basa su dividere un'applicazione in più servizi piccoli, autonomi e distribuibili in modo indipendenteognuno focalizzato su una funzionalità specifica (utenti, pagamenti, catalogo, ordini, ecc.), che comunicano principalmente tramite API leggere (HTTP/REST, gRPC, messaggistica, ecc.).
In un'applicazione monolitica, d'altra parte, Tutta la logica aziendale, il livello di presentazione e l'accesso ai dati sono raggruppati in un unico blocco di distribuzione.Ogni modifica richiede la ricompilazione, il test e la distribuzione dell'intero sistema, il che complica l'evoluzione e aumenta il rischio di introdurre errori in produzione.
Con i microservizi, ogni servizio ha il suo ciclo di vita: Può essere sviluppato, testato, distribuito, ridimensionato e sottoposto a versioning in modo indipendente.Ciò consente a più team di lavorare in parallelo, semplifica l'adozione di nuove tecnologie e facilita l'integrazione con le pratiche CI/CD.
Inoltre, questa architettura introduce il concetto di scalabilità indipendente dai componentiInvece di ridimensionare un'intera applicazione monolitica per supportare un carico maggiore su un modulo specifico, vengono ridimensionati solo i microservizi che ne hanno realmente bisogno, ottimizzando al meglio le risorse dell'infrastruttura.
Vantaggi e sfide reali dei microservizi
Il passaggio ai microservizi non è solo una moda passeggera: Offre vantaggi tangibili in termini di scalabilità, resilienza e velocità di distribuzione.Ma introduce anche una complessità operativa che deve essere gestita.
Tra i vantaggi più notevoli c'è il scalabilità indipendente di ogni servizioSe, ad esempio, il modulo dei pagamenti riceve più traffico del modulo di amministrazione, è possibile aumentare solo le repliche del microservizio dei pagamenti, senza toccare il resto dell'applicazione o sprecare risorse.
Si guadagna molto anche in distribuzione continua e consegne frequentiIsolando ogni servizio, è possibile rilasciare nuove versioni in modo incrementale, senza dover interrompere o ridistribuire l'intera applicazione, riducendo le finestre di manutenzione e migliorando il time-to-market.
Un altro punto fondamentale è il resilienza e tolleranza ai guastiSe progettato correttamente, il guasto di un microservizio non dovrebbe causare il crash dell'intero sistema. Grazie a schemi come timeout, nuovi tentativi e interruzioni di servizio, gli altri servizi possono continuare a rispondere, limitando l'impatto dei guasti.
Inoltre, i microservizi consentono flessibilità tecnologicaOgni team può scegliere il linguaggio, il framework o il database più appropriato per il proprio servizio, purché rispetti i contratti di comunicazione e le policy globali della piattaforma.
Dall'altro lato della medaglia troviamo il complessità operativa e di osservabilitàLa gestione di decine o centinaia di servizi implica la gestione di reti distribuite, tracce tra servizi, registrazione centralizzata, sicurezza, controllo delle versioni delle API e coerenza dei dati, il che richiede strumenti avanzati e processi maturi.
Diventa anche complicato gestione della comunicazione tra i serviziÈ essenziale progettare attentamente il modo in cui i dati vengono scambiati, come vengono gestiti gli errori, come viene gestita la latenza e come impedire che una dipendenza lenta trascini il resto del sistema. Test e debug non sono più banali, perché Non viene testato un singolo blocco, ma un insieme di servizi interconnessi..
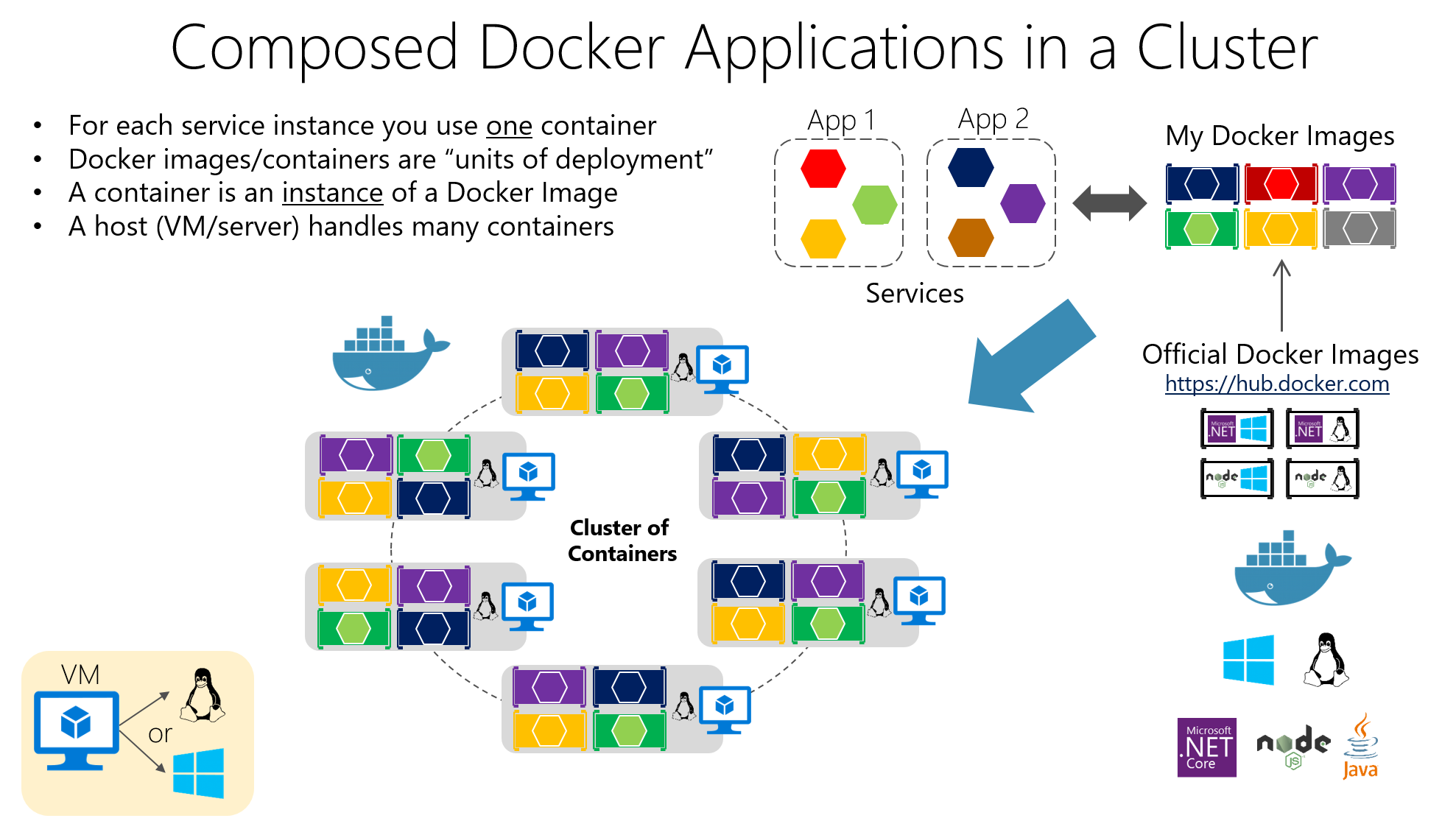
Contenitori: la base per l'esecuzione di microservizi in isolamento
La tecnologia dei container è diventata il supporto ideale per i microservizi perché Consente di impacchettare un'applicazione e tutte le sue dipendenze in un'unità standardizzata e portabile.Invece di installare librerie, runtime e strumenti su ogni server, tutto viaggia all'interno del contenitore.
Un contenitore è, essenzialmente, una forma leggera di virtualizzazione a livello di sistema operativo: condivide il kernel host ma esegue processi in namespace isolati e con risorse limitate dai cgroup, il che li fa avviare rapidamente e consumare meno di una macchina virtuale.
Tra le sue proprietà principali ci sono: isolamento, portabilità, leggerezza e modularitàOgni microservizio eseguito nel proprio contenitore diventa più facile da distribuire, arrestare, aggiornare o replicare, adattandosi perfettamente ai principi delle architetture distribuite.
Rispetto al macchine virtuali per la produzionei contenitori Non necessitano di un sistema operativo completo per ogni istanza.ma piuttosto condividere l'host. Questo riduce drasticamente le dimensioni delle immagini e il tempo de Bootconsentendo di sollevare o distruggere i contenitori in pochi secondi.
Docker: la piattaforma di riferimento per la containerizzazione dei microservizi
Docker è lo strumento più popolare per lavorare con i container, perché Facilita la creazione, il confezionamento, la distribuzione e l'esecuzione di applicazioni containerizzate sia negli ambienti di sviluppo che in quelli di test e produzione.
La loro idea centrale è quella di confezionare il software in Immagini DockerSi tratta di artefatti immutabili che includono il codice dell'applicazione, le librerie necessarie, gli strumenti di sistema e le configurazioni di base. Le applicazioni vengono create a partire da queste immagini. contenitori in funzione, che sono istanze isolate basate su quell'immagine.
La costruzione dell'immagine è definita in un Dockerfile, un file di testo che specifica istruzioni quali l'immagine di base, la directory di lavoro, quali file copiare, quali dipendenze installare, quali porte esporre e quale comando eseguire all'avvio del contenitore.
Immagina di avere un'API scritta in Node.js. Potresti creare un Dockerfile simile al seguente, dove Partendo da un'immagine ufficiale del Node, i file vengono copiati, le dipendenze vengono installate e il comando di avvio viene definito.:
FROM node:14
WORKDIR /app
COPY . .
RUN npm install
EXPOSE 3000
CMD
Questo file indica che l'applicazione verrà eseguita nella directory /app all'interno del contenitore, che le dipendenze saranno installate con npm, che la porta 3000 sarà esposta e che, all'avvio del contenitore, verrà eseguito inizio npm.
Per creare e avviare il contenitore, è sufficiente eseguire il comando dalla cartella del progetto. build docker poi run dockermappatura delle porte per consentire l'accesso dall'host o per l'uso di applicazioni multi-contenitore finestra mobile-composizione:
docker build -t mi-app .
docker run -p 3000:3000 mi-app
Grazie a questo modello, Il classico problema "funziona sulla mia macchina" è ridotto al minimo.Perché l'ambiente di runtime viaggia insieme all'applicazione. Inoltre, Docker si integra perfettamente con sistemi CI/CD, registri privati e strumenti di orchestrazione come Kubernetes.
Componenti chiave in Docker e il loro ruolo nei microservizi
In una tipica distribuzione, stiamo parlando di un Host Dockerche è il sistema (fisico o virtuale) su cui è installato Docker; viene eseguito su di esso. Motore Docker, il demone che gestisce immagini, reti, volumi e il ciclo di vita del contenitore.
I contenitori contengono il applicazione e le sue dipendenze impacchettate in un'immagineCiò consente a qualsiasi server con Docker di eseguire l'immagine in modo coerente. Questa coerenza è fondamentale quando si hanno molti microservizi distribuiti in diversi ambienti (sviluppo, controllo qualità, produzione, ecc.).
Tra i vantaggi più interessanti di Docker ci sono: portabilità tra ambienti, automazione della distribuzione, modularità dei processi e supporto per la stratificazione e il controllo delle versioni nelle immaginiche rende più facile invertire le modifiche e ottimizzare il immagazzinamento.
Kubernetes: l'orchestratore per governare centinaia di container
Quando si passa da pochi contenitori a decine o centinaia di essi, Gestirli manualmente diventa una folliaEd è qui che entra in gioco Kubernetes, una piattaforma open source progettata per orchestrare container su larga scala.
Kubernetes automatizza attività critiche come distribuzione, scalabilità, ripristino degli errori, configurazione di rete e archiviazione di applicazioni containerizzate. È progettato per funzionare in cloud pubblici, cloud privati, ambienti ibridi e persino on-premise.
Il suo obiettivo è la gestione di cluster composti da più nodi (macchine) in cui vengono eseguiti i container. L'obiettivo è garantire che le applicazioni sono sempre nello stato desiderato: numero di repliche, versioni distribuite, risorse allocate e connettività tra i servizi.
Elementi fondamentali di Kubernetes
L'unità più piccola in Kubernetes è la BaccelloUn Pod rappresenta una o più istanze di container che devono essere eseguite insieme (ad esempio, un container applicativo e un container sidecar per la registrazione). I Pod sono temporanei. Vengono creati, distrutti e sostituiti in base alle esigenze del cluster.
Per esporre i tuoi Pod, Kubernetes offre la risorsa Servizioche funge da livello di astrazione della rete. Un servizio raggruppa un insieme di Pod e Fornisce un indirizzo IP stabile, un nome DNS e un bilanciamento del carico interno.in modo che i clienti non abbiano bisogno di conoscere i dettagli di ogni Pod.
La risorsa Distribuzione Viene utilizzato per definire come distribuire e aggiornare i Pod: quante repliche, quale immagine utilizzare, quali tag applicare e quale strategia di aggiornamento seguire. Kubernetes gestisce tutto questo. mantenere sempre in esecuzione il numero desiderato di Pod e per eseguire aggiornamenti o rollback continui quando si modifica la configurazione.
Ci sono anche risorse come ConfigMap e SecretQueste funzionalità consentono di esternalizzare la configurazione e di archiviare dati sensibili (password, token, chiavi API) senza doverli impacchettare all'interno delle immagini. Ciò semplifica notevolmente la gestione sicura della configurazione in diversi ambienti.
Come organizzare un cluster Kubernetes
La “testa” del cluster è il Piano di controllo di Kubernetesche raggruppa diversi componenti responsabili dell'orchestrazione dell'intero sistema. Tra questi c'è il Server APIche è il gateway per la gestione del cluster; qualsiasi azione (creare una distribuzione, elencare i pod, modificare un servizio) passa attraverso questa API.
El Scheduler È responsabile della decisione su quale nodo viene eseguito ogni Pod, tenendo conto delle risorse disponibili, delle affinità e dei vincoli; mentre Responsabile del controllore Monitora lo stato del cluster e agisci per garantire che la realtà corrisponda a quanto dichiarato nei manifest (ad esempio, crea nuovi Pod se sono meno di quelli richiesti).
L'archiviazione dello stato è delegata a etcdUn database distribuito memorizza la configurazione e le informazioni di tutte le risorse del cluster. Inoltre, su ogni nodo worker vengono eseguiti processi come i seguenti: cubetto (agente che comunica il nodo con il server API), il kube-proxy (che gestisce il traffico di rete e il bilanciamento del carico) e il runtime del contenitore (Docker, containerd, CRI-O, ecc.).
Distribuzione di microservizi in Kubernetes con file YAML
Per distribuire un microservizio in Kubernetes, è comune descriverlo con un Manifesto YAML, dove si definisce la distribuzione (modello Pod, immagine, porte, numero di repliche, etichette) e il servizio corrispondente per esporlo all'interno o all'esterno del cluster.
Un esempio di base di distribuzione per un'applicazione denominata "my-app" potrebbe essere simile a questo, dove Sono definite tre repliche e la porta 3000 come porto container:
apiVersion: apps/v1
kind: Deployment
metadata:
name: mi-app
spec:
replicas: 3
selector:
matchLabels:
app: mi-app
template:
metadata:
labels:
app: mi-app
spec:
containers:
- name: mi-app
image: mi-app:latest
ports:
- containerPort: 3000
Questo manifesto indica che il cluster deve mantenere tre Pod in funzione Con l'immagine "my-app:latest", tutti i Pod sono taggati con app=my-app, in modo che un Servizio possa individuarli e distribuire il traffico tra di essi. Kubernetes gestisce automaticamente la logica per il ridimensionamento, gli aggiornamenti e la sostituzione dei Pod in caso di errore.
Insieme alle distribuzioni, è comune definire servizi di tipo ClusterIP, NodePort o LoadBalancerA seconda che il microservizio debba essere accessibile solo all'interno del cluster, dai nodi o da Internet, tutta questa configurazione viene sottoposta a versioning nei repository, integrandosi perfettamente con le pipeline CI/CD.
Scalabilità, aggiornamenti e auto-riparazione in Kubernetes
Uno dei motivi principali per utilizzare Kubernetes è la sua capacità di ridimensionare e aggiornare i microservizi senza arrestare l'applicazioneÈ possibile modificare il numero di repliche nel manifesto (o con un comando kubectl) e il cluster si occuperà di creare o rimuovere i Pod finché non verrà raggiunto il valore desiderato.
Questo ridimensionamento può essere manuale o automatico, utilizzando risorse come Autoscaler a pod orizzontale (HPA)Questa funzionalità regola dinamicamente le repliche in base a parametri quali CPU o memoria. In questo modo, la capacità viene aumentata durante i periodi di elevata domanda e le risorse vengono liberate quando il carico diminuisce.
Per quanto riguarda gli aggiornamenti, Kubernetes implementa aggiornamenti continui Di default: crea Pod con la nuova versione ed elimina gradualmente quelli della versione precedente, senza effettuare un taglio brusco. Se qualcosa va storto, un rollback Permette di recuperare rapidamente la versione precedente.
Un'altra funzionalità critica è la autoriparazioneSe un contenitore o un Pod non funziona più, Kubernetes lo ricrea automaticamente; se un nodo smette di rispondere, i Pod interessati vengono riprogrammati su altri nodi disponibili, mantenendo l'applicazione operativa.
Monitoraggio e osservabilità dei microservizi in Kubernetes
Per gestire correttamente un ambiente di microservizi, non è sufficiente semplicemente distribuire e scalare: Hai bisogno di visibilità in tempo reale sulle prestazioni e sullo stato dei serviziIn Kubernetes è molto comune integrare strumenti come Prometheus per raccogliere metriche e Grafana per visualizzarle.
Prometheus gestisce le metriche di "scraping" dai Pod, dai nodi e dai componenti del cluster, memorizzandole e consentendo di definire avvisi su di esse; in combinazione con Grafana, è possibile creare dashboard in cui Monitora l'utilizzo della CPU, la memoria, gli errori HTTP, la latenza, il numero di repliche o lo stato del nodo molto chiaramente.
Inoltre, kubectl offre comandi Per ispezionare lo stato di distribuzioni, servizi, pod e altre risorse, vedere i registriCiò include la descrizione di eventi o l'accesso ai container per il debug. Tutto ciò fa parte di una strategia di osservabilità che, nei microservizi, Non è facoltativo se vuoi dormire sonni tranquilli..
Relazione tra microservizi, Docker e Kubernetes
Microservizi, Docker e Kubernetes si incastrano come pezzi dello stesso puzzle: L'architettura dei microservizi definisce il modo in cui si progetta l'applicazione, Docker gestisce il packaging e l'esecuzione di ciascun servizio e Kubernetes orchestra tutti questi container. in un gruppo.
Ogni microservizio è incapsulato in un'immagine Docker che include il suo codice e le sue dipendenzeCiò garantisce che il sistema si comporti allo stesso modo sul laptop di uno sviluppatore, in un ambiente di test o nella produzione cloud. Questo packaging coerente è fondamentale per la filosofia DevOps.
Da parte sua, Kubernetes agisce come orchestratore di contenitoriDecide quante istanze di ciascun microservizio devono essere eseguite, dove sono ubicate, come viene bilanciato il traffico, come vengono ripristinate in caso di guasti e come vengono ridimensionate quando la domanda aumenta o diminuisce.
In un'applicazione di e-commerce, ad esempio, si potrebbero avere microservizi per l'autenticazione, il catalogo, il carrello e i pagamenti, ognuno con la propria immagine Docker e distribuzione Kubernetes. In questo modo, È possibile ridimensionare il catalogo in campagne o pagamenti massivi in momenti critici senza influire sul restoe orchestrarne l'intero ciclo di vita, dalle pipeline CI/CD al monitoraggio post-produzione.
Installazione di Docker e Kubernetes su Windows
Se lavori con Windows, il modo più semplice per iniziare è installare Desktop mobileche include il motore Docker e strumenti aggiuntivi, nonché opzioni per abilitare l'integrazione di Kubernetes nella tua macchina.
Il processo tipico prevede Scarica Docker Desktop dal sito ufficialeEseguire il programma di installazione (Docker Desktop Installer.exe) e seguire la procedura guidata. Durante l'installazione, è possibile scegliere se utilizzare Hyper-V o WSL 2 come tecnologia di virtualizzazione; se ce n'è una sola disponibile, sarà quella che verrà utilizzata.
Dopo il riavvio del sistema, l'apertura di Docker Desktop inizializza l'ambiente del contenitore; se la virtualizzazione non è stata abilitata, il programma di installazione stesso di solito offre abilitarlo automaticamenteDa lì puoi avviare contenitori, ad esempio Nginx o le tue applicazioni.
Per utilizzare Kubernetes su Windows, è necessario innanzitutto abilitare Docker e le funzionalità di virtualizzazione. Successivamente, è possibile abilitare Kubernetes da Docker Desktop o installare e configurare kubectl per gestire cluster esterni e, se opportuno, distribuire la dashboard di Kubernetes tramite un manifesto remoto.
Una volta configurata, potrai accedere alla dashboard tramite un proxy locale, utilizzando un token di autenticazione generato con kubectl e puntando, ad esempio, al file di configurazione. .kube/config per gestire l'accesso al cluster dal browser.
Installazione di Docker e Kubernetes su Linux
Sui sistemi Linux, come Ubuntu, l'installazione di Docker è solitamente piuttosto semplice: I pacchetti vengono aggiornati, il motore Docker viene installato e l'ambiente viene controllato per garantirne il corretto funzionamento. esecuzione di un contenitore di prova.
I passaggi tipici includono l'aggiornamento del sistema con apt-get update e apt-get upgradeRimuovere eventuali versioni precedenti di Docker Desktop, quindi installare docker-ce, docker-ce-cli, containerd.io e il plugin docker-compose dai repository ufficiali o specificando la versione desiderata.
Per verificare che tutto sia in ordine, solitamente viene avviato un contenitore "hello-world". Scarica un'immagine minima e la esegue.Se il messaggio viene visualizzato correttamente, Docker è attivo e pronto per iniziare a containerizzare i microservizi.
Per quanto riguarda Kubernetes, su Linux può essere installato utilizzando strumenti come kubeadmIl flusso di lavoro tipico prevede l'aggiunta della chiave del repository Kubernetes, la configurazione del file con l'elenco dei pacchetti, l'installazione di kubeadm e la verifica della sua versione.
Il cluster viene quindi inizializzato sul nodo master con kubeadm init (specificando l'intervallo di rete per i Pod), il comando "join" viene recuperato in modo che i nodi worker si uniscano al cluster e l'accesso locale venga configurato creando la directory $HOME/.kubecopiando il file admin.conf e modificando i permessi.
Con questo, avrai un cluster di base pronto per distribuire microservizi containerizzati, installa una rete di Pod (Flannel, Calico, ecc.) e inizia a lavorare con distribuzioni, servizi e il resto delle risorse Kubernetes.
Best practice e consigli per l'utilizzo di Docker e Kubernetes
Per ottenere il massimo da questi ambienti, è consigliabile seguire una serie di best practice con Docker, a partire da utilizzare immagini ufficiali o attendibili, sia da Docker Hub che da repository privati verificati, per ridurre i rischi per la sicurezza.
È altamente raccomandato ottimizzare la dimensione dell'immagine utilizzando immagini di base leggere, build multi-fase e rimozione File temporanei o artefatti non necessari. Immagini più piccole vengono scaricate più velocemente e velocizzano le distribuzioni su Kubernetes.
Un altro punto chiave è usare volumi per la persistenza dei datiInvece di archiviare le informazioni all'interno di contenitori, la perdita o la ricreazione di un contenitore non comporta la perdita di dati importanti.
Limitare le risorse assegnate a ciascun contenitore (CPU, memoria, I/O) aiuta a impedire a un singolo servizio di monopolizzare l'host e degradare il resto. Inoltre, i container devono essere monitorati con strumenti come Docker Stats o soluzioni più avanzate per mantenere il controllo in produzione.
Con Kubernetes, è essenziale comprendere l'architettura del cluster e i suoi componenti prima di andare in produzione. Questo riduce molti grattacapi.
È anche una buona idea automatizzare il più possibileUtilizza controller di replicazione, autoscaler e Job per caricamenti in batch; sfrutta gli aggiornamenti e i rollback progressivi; e definisci manifest dichiarativi con versione nei repository Git.
La sicurezza deve essere sempre una priorità assoluta: Limitare l'accesso al server API, gestire le credenziali utilizzando i segreti, crittografare i dati in transito e a riposoApplicare regolarmente le patch e definire policy di rete che limitino la comunicazione tra i servizi in base al principio del privilegio minimo.
Infine, è essenziale avere buoni sistemi centralizzati di monitoraggio e registrazionenonché con ambienti di pre-produzione in cui le modifiche possono essere testate approfonditamente prima di essere introdotte nel cluster di produzione, riducendo i rischi e le spiacevoli sorprese.
Questo intero ecosistema di microservizi, container Docker e orchestrazione Kubernetes consente di creare sistemi molto più flessibili, scalabili e resilienti rispetto ai monoliti tradizionali. Combinando un'architettura ben congegnata, strumenti appropriati e best practice DevOps, è possibile distribuire applicazioni che si adattano perfettamente alle variazioni del carico di lavoro, si ripristinano rapidamente in caso di guasti e sono più facili da evolvere nel tempo.

Scrittore appassionato del mondo dei byte e della tecnologia in generale. Adoro condividere le mie conoscenze attraverso la scrittura, ed è quello che farò in questo blog, mostrarti tutte le cose più interessanti su gadget, software, hardware, tendenze tecnologiche e altro ancora. Il mio obiettivo è aiutarti a navigare nel mondo digitale in modo semplice e divertente.