- Mikrodienste ermöglichen die Entwicklung modularer und skalierbarer Anwendungen, bei denen jeder Dienst autonom und unabhängig einsetzbar ist.
- Docker macht es einfach, leichtgewichtige, portable Container zu erstellen, die jeden Microservice mit all seinen Abhängigkeiten verpacken.
- Kubernetes orchestriert die Container und verwaltet die Bereitstellung, Skalierung, Vernetzung und automatische Wiederherstellung von Microservices im Cluster.
- Die Anwendung bewährter Sicherheits-, Überwachungs- und Automatisierungspraktiken ist der Schlüssel zum erfolgreichen Betrieb von Microservices in der Produktion.
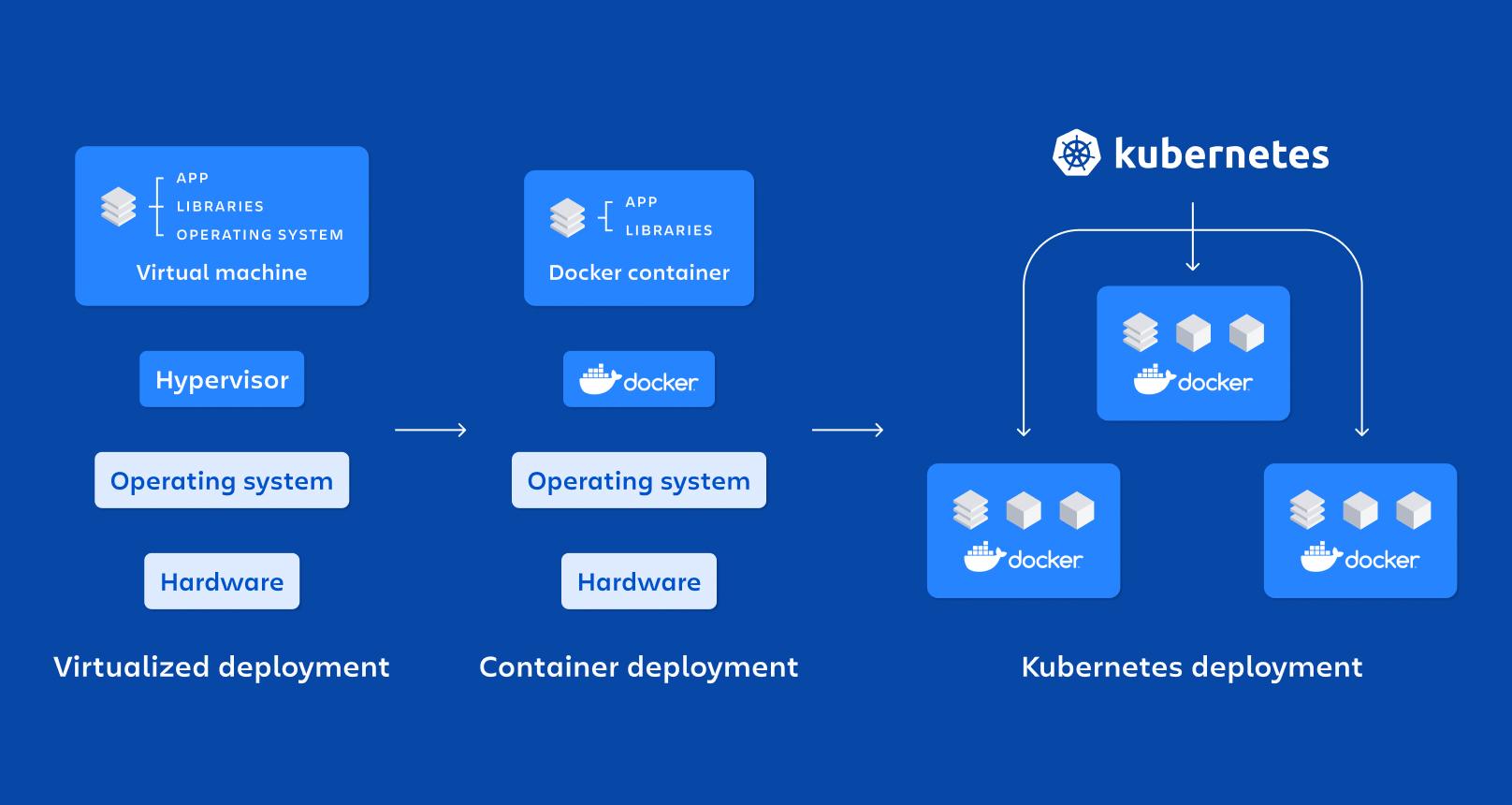
In den letzten Jahren, die Kombination aus Microservices, Docker und Kubernetes Es hat sich zum De-facto-Standard für die Bereitstellung moderner, skalierbarer und wartungsfreundlicher Anwendungen entwickelt. Immer mehr Unternehmen verabschieden sich von monolithischen Anwendungen und setzen stattdessen auf verteilte Architekturen, die besser für sich verändernde Umgebungen und DevOps-Strategien geeignet sind.
Wenn Sie sich fragen, Wie man Microservices mit Docker und Kubernetes in der Praxis implementiertDieser Inhalt ist genau das Richtige für Sie: Wir besprechen die wichtigsten Konzepte, Vorteile und Herausforderungen, wie man Container erstellt, wie man sie in einem Cluster orchestriert und welche Schritte zur Installation erforderlich sind. Windows y Linuxsowie eine Reihe von Tipps für deren sinnvolle Anwendung in realen Umgebungen.
Was ist eine Microservices-Architektur und wie unterscheidet sie sich von einer monolithischen Architektur?
Eine Microservices-Architektur basiert auf Eine Anwendung in mehrere kleine, autonome und unabhängig einsetzbare Dienste aufteilenJede dieser Lösungen konzentrierte sich auf eine bestimmte Funktionalität (Benutzer, Zahlungen, Katalog, Bestellungen usw.), die hauptsächlich über schlanke APIs (HTTP/REST, gRPC, Messaging usw.) kommunizierten.
In einer monolithischen Anwendung hingegen Die gesamte Geschäftslogik, die Präsentationsschicht und der Datenzugriff sind in einem einzigen Bereitstellungsblock zusammengefasst.Jede Änderung erfordert das erneute Kompilieren, Testen und Bereitstellen des gesamten Systems, was die Weiterentwicklung erschwert und das Risiko erhöht, Fehler in die Produktion einzuführen.
Bei Microservices hat jeder Dienst seinen eigenen Lebenszyklus: Es kann unabhängig entwickelt, getestet, bereitgestellt, skaliert und versioniert werden.Dies ermöglicht es mehreren Teams, parallel zu arbeiten, vereinfacht die Einführung neuer Technologien und erleichtert die Integration mit CI/CD-Praktiken.
Darüber hinaus führt diese Architektur das Konzept von Komponentenunabhängige SkalierbarkeitAnstatt eine gesamte monolithische Anwendung zu skalieren, um eine höhere Last auf einem bestimmten Modul zu bewältigen, werden nur die Microservices skaliert, die dies wirklich benötigen, wodurch die Infrastrukturressourcen besser optimiert werden.
Reale Vorteile und Herausforderungen von Microservices
Der Umstieg auf Microservices ist nicht nur eine Modeerscheinung: Es bietet konkrete Vorteile in Bezug auf Skalierbarkeit, Ausfallsicherheit und Bereitstellungsgeschwindigkeit.Dies bringt jedoch auch eine operative Komplexität mit sich, die bewältigt werden muss.
Zu den bemerkenswertesten Vorteilen gehört die unabhängige Skalierbarkeit jedes DienstesWenn beispielsweise das Zahlungsmodul mehr Datenverkehr empfängt als das Verwaltungsmodul, können Sie einfach die Anzahl der Replikate des Zahlungs-Mikrodienstes erhöhen, ohne den Rest der Anwendung zu beeinträchtigen oder Ressourcen zu verschwenden.
Sie gewinnen auch viel durch kontinuierliche Bereitstellung und häufige LieferungenDurch die Isolation der einzelnen Dienste ist es möglich, neue Versionen schrittweise zu veröffentlichen, ohne die gesamte Anwendung anhalten oder neu bereitstellen zu müssen. Dies reduziert die Wartungsfenster und verbessert die Markteinführungszeit.
Ein weiterer wichtiger Punkt ist der Resilienz und FehlertoleranzBei korrekter Konzeption sollte der Ausfall eines einzelnen Microservices nicht das gesamte System lahmlegen. Mithilfe von Mechanismen wie Timeouts, Wiederholungsversuchen und Circuit Breakern können die anderen Services weiterhin reagieren, wodurch die Auswirkungen der Ausfälle begrenzt werden.
Darüber hinaus ermöglichen Mikrodienste Folgendes: technologische FlexibilitätJedes Team kann die für seinen Dienst am besten geeignete Sprache, das Framework oder die Datenbank wählen, solange es die Kommunikationsverträge und die globalen Richtlinien der Plattform einhält.
Auf der anderen Seite der Medaille finden wir die Betriebs- und BeobachtbarkeitskomplexitätDie Verwaltung von Dutzenden oder Hunderten von Diensten erfordert den Umgang mit verteilten Netzwerken, dienstübergreifenden Traces, zentralisierter Protokollierung, Sicherheit, API-Versionierung und Datenkonsistenz, was fortgeschrittene Werkzeuge und ausgereifte Prozesse erfordert.
Es wird auch kompliziert Management der Kommunikation zwischen DienstenEs ist unerlässlich, sorgfältig zu konzipieren, wie der Datenaustausch erfolgt, wie Fehler behandelt werden, wie Latenzzeiten gemanagt werden und wie verhindert wird, dass eine langsame Abhängigkeit das restliche System beeinträchtigt. Testen und Debuggen werden dadurch nicht mehr trivial, denn Es wird nicht ein einzelner Block getestet, sondern ein Satz von miteinander verbundenen Diensten..
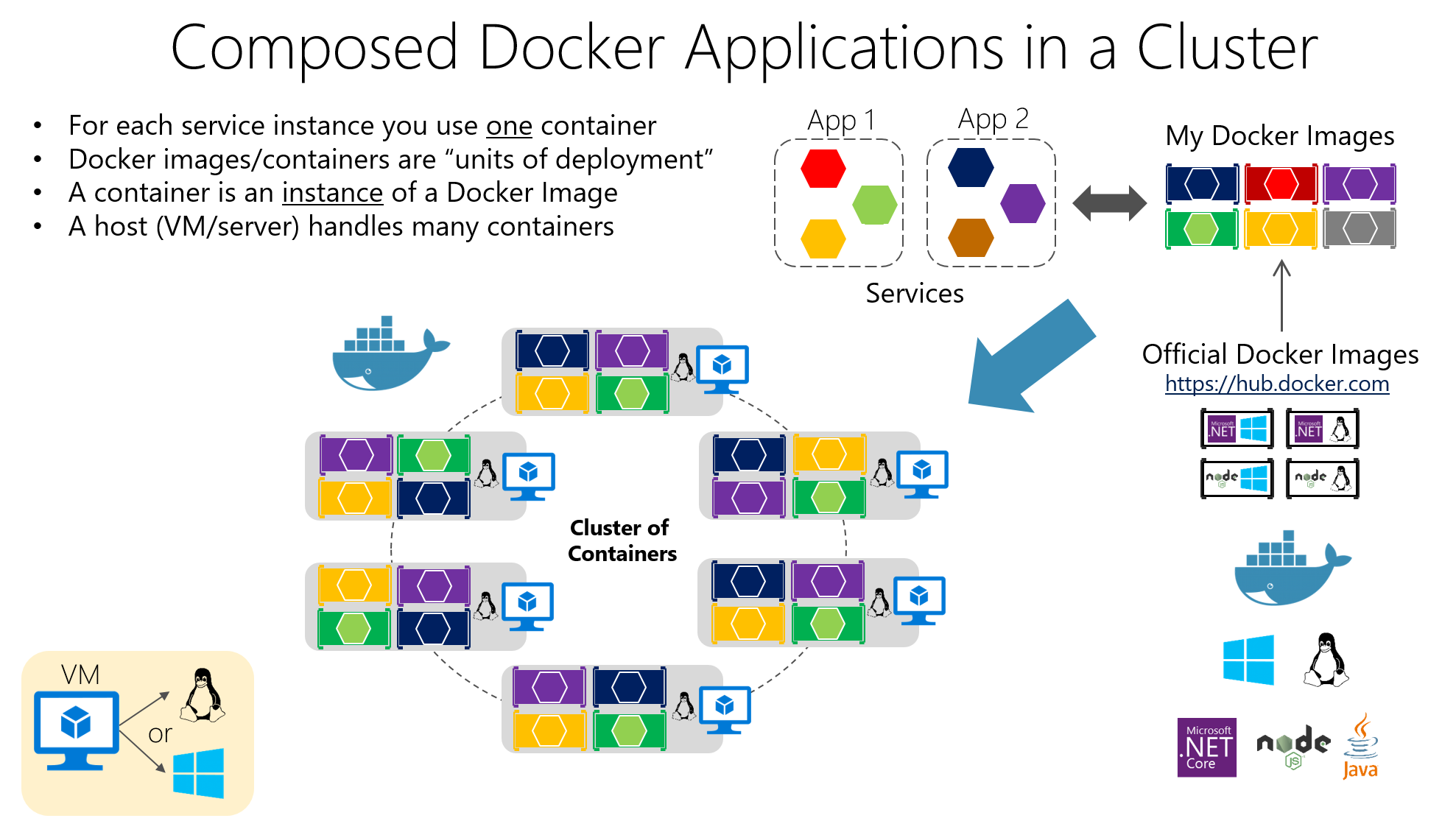
Container: Die Grundlage für den isolierten Betrieb von Microservices
Die Containertechnologie hat sich zur idealen Unterstützung für Microservices entwickelt, weil Es ermöglicht Ihnen, eine Anwendung und alle ihre Abhängigkeiten in eine standardisierte und portable Einheit zu verpacken.Anstatt Bibliotheken, Laufzeitumgebungen und Tools auf jedem Server zu installieren, wird alles innerhalb des Containers übertragen.
Ein Behälter ist im Wesentlichen eine leichtgewichtige Form der Virtualisierung auf Betriebssystemebene: teilt sich den Host-Kernel, führt Prozesse aber in isolierten Namensräumen und mit durch cgroups begrenzten Ressourcen aus, wodurch sie schnell hochfahren und weniger Ressourcen verbrauchen als eine virtuelle Maschine.
Zu seinen wichtigsten Eigenschaften gehören die Isolierung, Tragbarkeit, geringes Gewicht und ModularitätJeder in einem eigenen Container laufende Mikrodienst lässt sich einfacher bereitstellen, stoppen, aktualisieren oder replizieren, was perfekt zu den Prinzipien verteilter Architekturen passt.
Im Vergleich zu Virtuelle Maschinen für die Produktiondie Behälter Sie benötigen kein vollständiges Betriebssystem pro Instanz.sondern teilen sich die Dateien des Hosts. Dadurch wird die Größe der Bilder drastisch reduziert und die zeit de Startenermöglicht es Ihnen, Container in Sekundenschnelle anzuheben oder zu zerstören.
Docker: Die Referenzplattform für die Containerisierung von Microservices
Docker ist das beliebteste Tool für die Arbeit mit Containern, weil Es erleichtert die Erstellung, Verpackung, Verteilung und Ausführung von containerisierten Anwendungen. sowohl in Entwicklungsumgebungen als auch in Test- und Produktionsumgebungen.
Ihre zentrale Idee besteht darin, die Software zu verpacken in Docker-ImagesHierbei handelt es sich um unveränderliche Artefakte, die den Anwendungscode, die benötigten Bibliotheken, Systemwerkzeuge und grundlegende Konfigurationen enthalten. Aus diesen Images werden Anwendungen erstellt. Container im Betrieb, die isolierte Instanzen basierend auf diesem Bild darstellen.
Die Bildkonstruktion ist in einem definiert. Dockerfile, eine Textdatei, die Anweisungen wie das Basis-Image, das Arbeitsverzeichnis, die zu kopierenden Dateien, die zu installierenden Abhängigkeiten, die freizugebenden Ports und den beim Starten des Containers auszuführenden Befehl enthält.
Stellen Sie sich vor, Sie haben eine in Node.js geschriebene API. Sie könnten ein Dockerfile ähnlich dem folgenden erstellen, wobei Ausgehend von einem offiziellen Node-Image werden die Dateien kopiert, die Abhängigkeiten installiert und der Boot-Befehl definiert.:
FROM node:14
WORKDIR /app
COPY . .
RUN npm install
EXPOSE 3000
CMD
Diese Datei gibt an, dass die Anwendung im Verzeichnis ausgeführt wird. /app innerhalb des Containersdass die Abhängigkeiten mit npm installiert werden, dass Port 3000 freigegeben wird und dass beim Start des Containers Folgendes ausgeführt wird npm starten.
Um diesen Container zu erstellen und zu starten, führen Sie einfach den Befehl im Projektordner aus. Docker-Build und dann AndocklaufDie Ports werden so zugeordnet, dass der Zugriff vom Host aus möglich ist, oder für Anwendungen mit mehreren Containern wird Folgendes verwendet: Docker-komponieren:
docker build -t mi-app .
docker run -p 3000:3000 mi-app
Dank dieses Modells Das klassische Problem „Es funktioniert auf meinem Rechner“ wird auf ein Minimum reduziert.Weil die Laufzeitumgebung mit der Anwendung übertragen wird. Darüber hinaus lässt sich Docker nahtlos in CI/CD-Systeme, private Registries und Orchestrierungstools wie Kubernetes integrieren.
Wichtige Komponenten von Docker und ihre Rolle in Microservices
Bei einem typischen Einsatz sprechen wir von einem Docker-HostDas ist das System (physisch oder virtuell), auf dem Docker installiert ist; darauf läuft es. Docker-Engine, der Daemon, der Images, Netzwerke, Volumes und den Container-Lebenszyklus verwaltet.
Die Behälter enthalten die Anwendung und ihre Abhängigkeiten in einem Image verpacktDadurch kann jeder Server mit Docker dieses Image konsistent ausführen. Diese Konsistenz ist entscheidend, wenn viele Microservices in verschiedenen Umgebungen (Entwicklung, Qualitätssicherung, Produktion usw.) bereitgestellt werden.
Zu den interessantesten Vorteilen von Docker gehören die Portabilität zwischen Umgebungen, Bereitstellungsautomatisierung, Prozessmodularität und Unterstützung für Layering und Versionskontrolle in Imageswas es einfacher macht, Änderungen rückgängig zu machen und die Optimierung zu ermöglichen Lagerung.
Kubernetes: Der Orchestrator zur Steuerung hunderter Container
Wenn man von wenigen Behältern auf Dutzende oder Hunderte davon umsteigt, Die manuelle Verwaltung wird zum Wahnsinn.Hier kommt Kubernetes ins Spiel, eine Open-Source-Plattform, die für die Orchestrierung von Containern in großem Umfang entwickelt wurde.
Kubernetes automatisiert kritische Aufgaben wie zum Beispiel Bereitstellung, Skalierung, Fehlerbehebung, Netzwerkkonfiguration und Speicherung Es ist für containerisierte Anwendungen konzipiert. Es ist für den Einsatz in öffentlichen Clouds, privaten Clouds, hybriden Umgebungen und sogar On-Premises-Umgebungen geeignet.
Der Schwerpunkt liegt auf der Verwaltung von Clustern, die aus mehreren Knoten (Maschinen) bestehen, auf denen Container ausgeführt werden. Ziel ist es, sicherzustellen, dass Die Anwendungen befinden sich stets im gewünschten Zustand.: Anzahl der Replikate, bereitgestellte Versionen, zugewiesene Ressourcen und Konnektivität zwischen Diensten.
Grundlegende Elemente von Kubernetes
Die kleinste Einheit in Kubernetes ist die SchoteEin Pod repräsentiert eine oder mehrere Containerinstanzen, die zusammen ausgeführt werden müssen (z. B. ein Anwendungscontainer und ein Sidecar-Container für die Protokollierung). Pods sind kurzlebig. Sie werden je nach Bedarf des Clusters erzeugt, zerstört und ersetzt..
Um Ihre Pods verfügbar zu machen, bietet Kubernetes die Ressource an. Servicedie als Netzwerkabstraktionsschicht fungiert. Ein Service gruppiert eine Gruppe von Pods und Es bietet eine stabile IP-Adresse, einen DNS-Namen und internen Lastausgleich.damit die Kunden die Details der einzelnen Pods nicht kennen müssen.
Die Ressource Einsatz Es dient dazu, festzulegen, wie Pods bereitgestellt und aktualisiert werden sollen: die Anzahl der Replikate, das zu verwendende Image, die anzuwendenden Tags und die zu verfolgende Aktualisierungsstrategie. Kubernetes kümmert sich darum. Die gewünschte Anzahl laufender Pods wird stets aufrechterhalten. und um fortlaufende Aktualisierungen oder Rollbacks durchzuführen, wenn Sie die Konfiguration ändern.
Es gibt auch Ressourcen wie zum Beispiel ConfigMap und GeheimnisDiese Funktionen ermöglichen es Ihnen, Konfigurationen auszulagern und sensible Daten (Passwörter, Tokens, API-Schlüssel) zu speichern, ohne sie in die Images einbinden zu müssen. Dies vereinfacht die sichere Konfigurationsverwaltung in verschiedenen Umgebungen erheblich.
Wie man einen Kubernetes-Cluster organisiert
Der „Kopf“ des Clusters ist der Kubernetes-KontrollplanDiese Gruppe fasst mehrere Komponenten zusammen, die für die Steuerung des gesamten Systems verantwortlich sind. Dazu gehört unter anderem die API-ServerDies ist das Gateway zur Verwaltung des Clusters; jede Aktion (Erstellen eines Deployments, Auflisten von Pods, Ändern eines Services) erfolgt über diese API.
El Scheduler Es ist dafür verantwortlich, zu entscheiden, auf welchem Knoten jeder Pod ausgeführt wird, wobei verfügbare Ressourcen, Affinitäten und Einschränkungen berücksichtigt werden; während die Controller-Manager Überwachen Sie den Status des Clusters und ergreifen Sie Maßnahmen, um sicherzustellen, dass die Realität mit den Angaben in den Manifesten übereinstimmt (z. B. neue Pods erstellen, wenn weniger vorhanden sind als angefordert).
Die Zustandsspeicherung wird delegiert an uswEine verteilte Datenbank speichert die Konfiguration und Informationen für alle Ressourcen des Clusters. Zusätzlich werden auf jedem Worker-Knoten Prozesse wie die folgenden ausgeführt: Kubelet (Agent, der den Knoten mit dem API-Server kommuniziert), der Kube-Proxy (das den Netzwerkverkehr und die Lastverteilung verwaltet) und die Containerlaufzeit (Docker, containerd, CRI-O usw.).
Bereitstellung von Microservices in Kubernetes mit YAML-Dateien
Um einen Microservice in Kubernetes bereitzustellen, ist es üblich, ihn mit einem zu beschreiben YAML-ManifestHier definieren Sie die Bereitstellung (Pod-Vorlage, Image, Ports, Anzahl der Replikate, Labels) und den entsprechenden Dienst, um sie innerhalb oder außerhalb des Clusters bereitzustellen.
Ein einfaches Beispiel für die Bereitstellung einer Anwendung namens „my-app“ könnte etwa so aussehen, wobei Drei Replikate und Port 3000 sind definiert als Container-Port:
apiVersion: apps/v1
kind: Deployment
metadata:
name: mi-app
spec:
replicas: 3
selector:
matchLabels:
app: mi-app
template:
metadata:
labels:
app: mi-app
spec:
containers:
- name: mi-app
image: mi-app:latest
ports:
- containerPort: 3000
Dieses Manifest zeigt an, dass der Cluster aufrechterhalten muss drei Pods im Betrieb Mit dem Image „my-app:latest“ werden alle Pods mit app=my-app getaggt, sodass ein Service sie finden und den Datenverkehr auf sie verteilen kann. Kubernetes kümmert sich automatisch um die Logik für Skalierung, Aktualisierungen und den Austausch von Pods im Fehlerfall.
Neben Deployments ist es üblich, Dienste vom Typ zu definieren. ClusterIP, NodePort oder LoadBalancerJe nachdem, ob der Microservice nur innerhalb des Clusters, von den Knoten oder aus dem Internet erreichbar sein soll, wird die gesamte Konfiguration in Repositories versioniert und nahtlos in CI/CD-Pipelines integriert.
Skalierung, Upgrades und Selbstheilung in Kubernetes
Einer der wichtigsten Gründe für die Verwendung von Kubernetes ist seine Fähigkeit, Skalieren und Aktualisieren von Microservices, ohne die Anwendung zu stoppenSie können die Anzahl der Replikate im Manifest (oder mit einem kubectl-Befehl) ändern, und der Cluster kümmert sich um das Erstellen oder Entfernen von Pods, bis der gewünschte Wert erreicht ist.
Diese Skalierung kann manuell oder automatisch erfolgen, unter Verwendung von Ressourcen wie beispielsweise Horizontaler Pod-Autoscaler (HPA)Diese Funktion passt die Anzahl der Replikate dynamisch anhand von Kennzahlen wie CPU- oder Speicherauslastung an. Dadurch wird die Kapazität bei hoher Nachfrage erhöht und Ressourcen werden bei sinkender Last freigegeben.
Bezüglich der Updates implementiert Kubernetes Folgendes: fortlaufende Updates Standardmäßig werden Pods mit der neuen Version erstellt und die der vorherigen Version schrittweise gelöscht, ohne einen abrupten Schnitt vorzunehmen. Falls etwas schiefgeht, Rollback Es ermöglicht Ihnen, schnell zur vorherigen Version zurückzukehren.
Eine weitere wichtige Funktionalität ist die SelbstreparaturWenn ein Container oder Pod ausfällt, erstellt Kubernetes ihn automatisch neu; wenn ein Knoten nicht mehr reagiert, werden die betroffenen Pods auf anderen verfügbaren Knoten neu eingeplant, sodass die Anwendung weiterhin betriebsbereit bleibt.
Überwachung und Beobachtbarkeit von Microservices in Kubernetes
Für den korrekten Betrieb einer Microservices-Umgebung reicht es nicht aus, sie einfach nur bereitzustellen und zu skalieren: Sie benötigen Echtzeit-Einblicke in die Leistung und den Status der Dienste.In Kubernetes ist es sehr üblich, Tools wie Prometheus zum Sammeln von Metriken und Grafana zur Visualisierung dieser Metriken zu integrieren.
Prometheus übernimmt das „Scraping“ von Metriken von Pods, Nodes und Clusterkomponenten, speichert diese und ermöglicht die Definition von Warnmeldungen dazu; in Kombination mit Grafana können Sie Dashboards erstellen, in denen Überwachen Sie CPU-Auslastung, Speicher, HTTP-Fehler, Latenz, Anzahl der Replikate oder Knotenstatus sehr deutlich.
Darüber hinaus bietet kubectl Folgendes an Befehle Um den Status von Deployments, Services, Pods und anderen Ressourcen zu überprüfen, siehe ProtokolleDies umfasst die Beschreibung von Ereignissen oder den Zugriff auf Container zum Debuggen. All dies ist Teil einer Observability-Strategie, die in Microservices … Es ist keine Option, wenn man ruhig schlafen will..
Beziehung zwischen Microservices, Docker und Kubernetes
Microservices, Docker und Kubernetes passen zusammen wie Teile desselben Puzzles: Die Microservices-Architektur definiert, wie die Anwendung entworfen wird, Docker kümmert sich um das Verpacken und Ausführen der einzelnen Dienste, und Kubernetes orchestriert all diese Container. in einem Cluster.
Jeder Mikrodienst ist gekapselt in ein Docker-Image, das seinen Code und seine Abhängigkeiten enthältDadurch wird sichergestellt, dass es sich auf dem Laptop eines Entwicklers, in einer Testumgebung oder in der Cloud-Produktion gleich verhält. Diese einheitliche Paketierung ist für die DevOps-Philosophie unerlässlich.
Kubernetes seinerseits fungiert als Container-OrchestratorEs legt fest, wie viele Instanzen jedes Mikrodienstes laufen sollen, wo sie sich befinden, wie der Datenverkehr auf sie verteilt wird, wie sie sich von Ausfällen erholen und wie sie skalieren, wenn die Nachfrage steigt oder sinkt.
In einer E-Commerce-Anwendung könnten beispielsweise Microservices für Authentifizierung, Katalog, Warenkorb und Zahlungen eingesetzt werden, jeweils mit eigenem Docker-Image und eigener Kubernetes-Bereitstellung. Auf diese Weise… Sie können den Katalog in großen Kampagnen oder Zahlungen zu kritischen Zeitpunkten skalieren, ohne den Rest zu beeinträchtigen.und orchestrieren Sie den gesamten Lebenszyklus von CI/CD-Pipelines bis hin zur Überwachung nach der Produktion.
Installation von Docker und Kubernetes unter Windows
Wenn Sie mit Windows arbeiten, ist der einfachste Weg zu beginnen die Installation. Docker-DesktopDazu gehören die Docker-Engine und zusätzliche Tools sowie Optionen zur Integration von Kubernetes in Ihren Rechner.
Der typische Ablauf beinhaltet Laden Sie Docker Desktop von der offiziellen Website herunter.Führen Sie das Installationsprogramm (Docker Desktop Installer.exe) aus und folgen Sie dem Installationsassistenten. Während der Installation können Sie zwischen der Verwendung von Hyper-V oder WSL 2 als Virtualisierungstechnologie; wenn nur eine verfügbar ist, wird diese verwendet.
Nach dem Neustart des Systems initialisiert das Öffnen von Docker Desktop die Containerumgebung; falls die Virtualisierung nicht aktiviert war, bietet das Installationsprogramm normalerweise selbst die entsprechende Option an. Automatische AktivierungVon dort aus können Sie Container starten, zum Beispiel Nginx oder Ihre eigenen Anwendungen.
Um Kubernetes unter Windows zu verwenden, müssen Sie zunächst Docker und die Virtualisierungsfunktionen aktivieren. Anschließend können Sie Kubernetes über Docker Desktop aktivieren. kubectl installieren und konfigurieren Externe Cluster zu verwalten und gegebenenfalls das Kubernetes-Dashboard über ein Remote-Manifest bereitzustellen.
Nach der Konfiguration können Sie über einen lokalen Proxy auf das Dashboard zugreifen. Dazu verwenden Sie ein mit kubectl generiertes Authentifizierungstoken, das beispielsweise auf die Konfigurationsdatei verweist. .kube/config um den Zugriff auf den Cluster vom Browser aus zu verwalten.
Installation von Docker und Kubernetes unter Linux
Auf Linux-Systemen wie Ubuntu ist die Installation von Docker in der Regel recht unkompliziert: Die Pakete werden aktualisiert, die Docker-Engine wird installiert und die Umgebung wird überprüft, um sicherzustellen, dass alles ordnungsgemäß funktioniert. Einen Testcontainer ausführen.
Zu den typischen Schritten gehört die Aktualisierung des Systems mit apt-get update und apt-get upgradeEntfernen Sie gegebenenfalls alle vorherigen Versionen von Docker Desktop und installieren Sie anschließend docker-ce, docker-ce-cli, containerd.io und das docker-compose-Plugin aus den offiziellen Repositories oder indem Sie die gewünschte Version angeben.
Um zu überprüfen, ob alles in Ordnung ist, wird üblicherweise ein „Hello-World“-Container gestartet. Es lädt ein minimales Image herunter und führt es aus.Wenn die Meldung korrekt angezeigt wird, ist Docker eingerichtet und betriebsbereit und kann nun mit der Containerisierung Ihrer Microservices beginnen.
Kubernetes kann unter Linux mithilfe von Tools wie beispielsweise … installiert werden. kubeadmDer typische Arbeitsablauf umfasst das Hinzufügen des Kubernetes-Repository-Schlüssels, das Konfigurieren der Paketlistendatei, die Installation von kubeadm und das Überprüfen seiner Version.
Der Cluster wird dann auf dem Master-Knoten initialisiert mit kubeadm init (Nachdem der Netzwerkbereich für die Pods festgelegt wurde), wird der Befehl „join“ aufgerufen, damit die Worker-Knoten dem Cluster beitreten, und der lokale Zugriff wird durch Erstellen des Verzeichnisses konfiguriert. $HOME/.kubedurch Kopieren der Datei admin.conf und Anpassen der Berechtigungen.
Damit verfügen Sie über einen grundlegenden Cluster, der für Folgendes bereit ist: Bereitstellung von containerisierten MicroservicesInstallieren Sie ein Netzwerk von Pods (Flannel, Calico usw.) und beginnen Sie mit der Arbeit an Deployments, Services und den übrigen Kubernetes-Ressourcen.
Bewährte Verfahren und Empfehlungen für die Verwendung von Docker und Kubernetes
Um diese Umgebungen optimal zu nutzen, empfiehlt es sich, eine Reihe bewährter Vorgehensweisen mit Docker zu befolgen, angefangen mit Verwenden Sie offizielle oder vertrauenswürdige Bilder, entweder von Docker Hub oder aus verifizierten privaten Repositories, um Sicherheitsrisiken zu minimieren.
Es wird dringend empfohlen Bildgröße optimieren durch Verwendung von leichtgewichtigen Basisimages, mehrstufigen Builds und Entfernen temporäre Dateien oder unnötige Artefakte. Kleinere Images werden schneller heruntergeladen und beschleunigen die Bereitstellung auf Kubernetes.
Ein weiterer wichtiger Punkt ist die Verwendung Datenvolumen für die DatenspeicherungAnstatt Informationen in Containern zu speichern, führt der Verlust oder die Wiederherstellung eines Containers nicht zum Verlust wichtiger Daten.
Die Begrenzung der jedem Container zugewiesenen Ressourcen (CPU, Speicher, E/A) hilft dabei, verhindern, dass ein einzelner Dienst den Host monopolisiert und den Rest beeinträchtigen. Darüber hinaus müssen Container mit Tools wie Docker Stats oder fortgeschritteneren Lösungen überwacht werden, um die Kontrolle im Produktionsbetrieb zu behalten.
Bei Kubernetes ist es unerlässlich, die Clusterarchitektur und ihre Komponenten vor dem Produktiveinsatz zu verstehen. Das erspart viele Probleme.
Es ist auch eine gute Idee so viel wie möglich automatisierenNutzen Sie Replikationscontroller, Autoscaler und Jobs für Batch-Uploads; profitieren Sie von Rolling Updates und Rollbacks; und definieren Sie versionierte deklarative Manifeste in Git-Repositories.
Sicherheit muss immer oberste Priorität haben: Beschränken Sie den Zugriff auf den API-Server, verwalten Sie Anmeldeinformationen mithilfe von Geheimnissen und verschlüsseln Sie Daten während der Übertragung und im Ruhezustand.Patches sollten regelmäßig eingespielt und Netzwerkrichtlinien definiert werden, die die Kommunikation zwischen Diensten nach dem Prinzip der minimalen Berechtigungen einschränken.
Schließlich ist es unerlässlich, gute zentrale Überwachungs- und Protokollierungssystemesowie in Vorproduktionsumgebungen, in denen Änderungen gründlich getestet werden können, bevor sie in den Produktionscluster übernommen werden, wodurch Risiken und unangenehme Überraschungen reduziert werden.
Dieses gesamte Ökosystem aus Microservices, Docker-Containern und Kubernetes-Orchestrierung ermöglicht den Aufbau von Systemen, die deutlich flexibler, skalierbarer und ausfallsicherer sind als herkömmliche monolithische Architekturen. Durch die Kombination einer durchdachten Architektur, geeigneter Tools und bewährter DevOps-Praktiken lassen sich Anwendungen bereitstellen, die sich nahtlos an veränderte Arbeitslasten anpassen, schnell von Ausfällen genesen und sich im Laufe der Zeit leichter weiterentwickeln lassen.

Leidenschaftlicher Autor über die Welt der Bytes und der Technologie im Allgemeinen. Ich liebe es, mein Wissen durch Schreiben zu teilen, und genau das werde ich in diesem Blog tun und Ihnen die interessantesten Dinge über Gadgets, Software, Hardware, technologische Trends und mehr zeigen. Mein Ziel ist es, Ihnen dabei zu helfen, sich auf einfache und unterhaltsame Weise in der digitalen Welt zurechtzufinden.